
Knowledge graphs play a role in many of our favorite products. They provide information and context that serves up recommendations and additional information just where we need it.
They’re how Alexa and Google search can provide information on entities related to a request. They’re how Netflix builds a profile of the genres, plots, and actors you like.
Many knowledge graphs that reach consumers are primarily built on internal data stores. But a growing number also augment their breadth and timeliness by sourcing information from the public internet.
Three North American entities have claims to crawling the whole web in order to structure information into knowledge graphs. These organizations are Google, Bing, and Diffbot.
All three provide some level of knowledge graph access to end consumers. Though –of these three – Diffbot is the only commercial knowledge graph provider that allows data teams to integrate and download the entirety of their data. This makes Diffbot’s Knowledge Graph a great starting point for machine learning projects, deeper market intelligence exercises, or web-wide news monitoring projects.
With that said, many product leaders and data teams are not looking for the widest coverage or the largest sets of ingestible data, per se. Rather, these teams are discerning which knowledge graph has the coverage they need.
For example, do you need rapidly updated information about large entities that are easy to track? Do you need suitable coverage of extremely long tail organizations? And what types of data do you need? Basic organizational data? Articles about specific entities? Product data? Discussions or events?
In this guide we’ll work through a comparison of data coverage between Diffbot and Google knowledge graphs, both of which are available through knowledge graph search APIs.
Note: Before we jump in, one thing worth noting is that the Google knowledge graph API is not recommended for production uses, rather it’s more of a demo of their internal technology and data.
Check out our comparison of data returned from Google and Diffbot KG search APIs here.
Which Knowledge Graph is Larger? Google VS. Diffbot
Historically, knowledge graphs used in academic settings have been too small for viable commercial use. But once knowledge graphs grew substantially past this size, the absolute size of a knowledge graph often wasn’t a proxy for the usefulness of a knowledge graph.
To show you what we mean, both the Diffbot and Google knowledge graphs hold roughly the same number of entities: ~5B (Google, 2020), and ~5.9B (Diffbot, 2022). But knowledge graphs are built around “things” (items in the world), and ~5B doesn’t begin to account for all of those.
So what “things” are included? Industry insights? Global news coverage? Can this data tell you whether you’d like a movie or should buy a product?
All of these are viable uses for knowledge graphs, and the answers are dependent on the following non-scale related features:
- What type (topics and fact types) of data is included
- How up-to-date data is
- The number of valuable fields per entity
- How accurate data is
- How easy it is to extract the data you need
- How easy it is to fit this data into your workflows
- And business process-related aspects like pricing, uptime, data provenance, and so forth
To dive into the differences between Diffbot and Google knowledge graphs on the above points, we’ll need to provide some background information about how these knowledge graphs are constructed. Following this, we’ll jump into an up-to-date benchmarking of the coverage of specific entities within each knowledge graph.
How Google Crawls the Web
Historically, Google has crawled the web to surface what it deems to be the most useful pieces of content around search keywords. Sites deemed more useful or “important” get crawled more frequently. And the top sites tend to present highly in many search terms related to their offerings.
While Google applies robust natural language processing to pages in order to provide their search service, many surfaced “facts” are not integrated with their knowledge graph as seen in knowledge panels or their KG search API. Take for example the knowledge panel result for Diffbot.
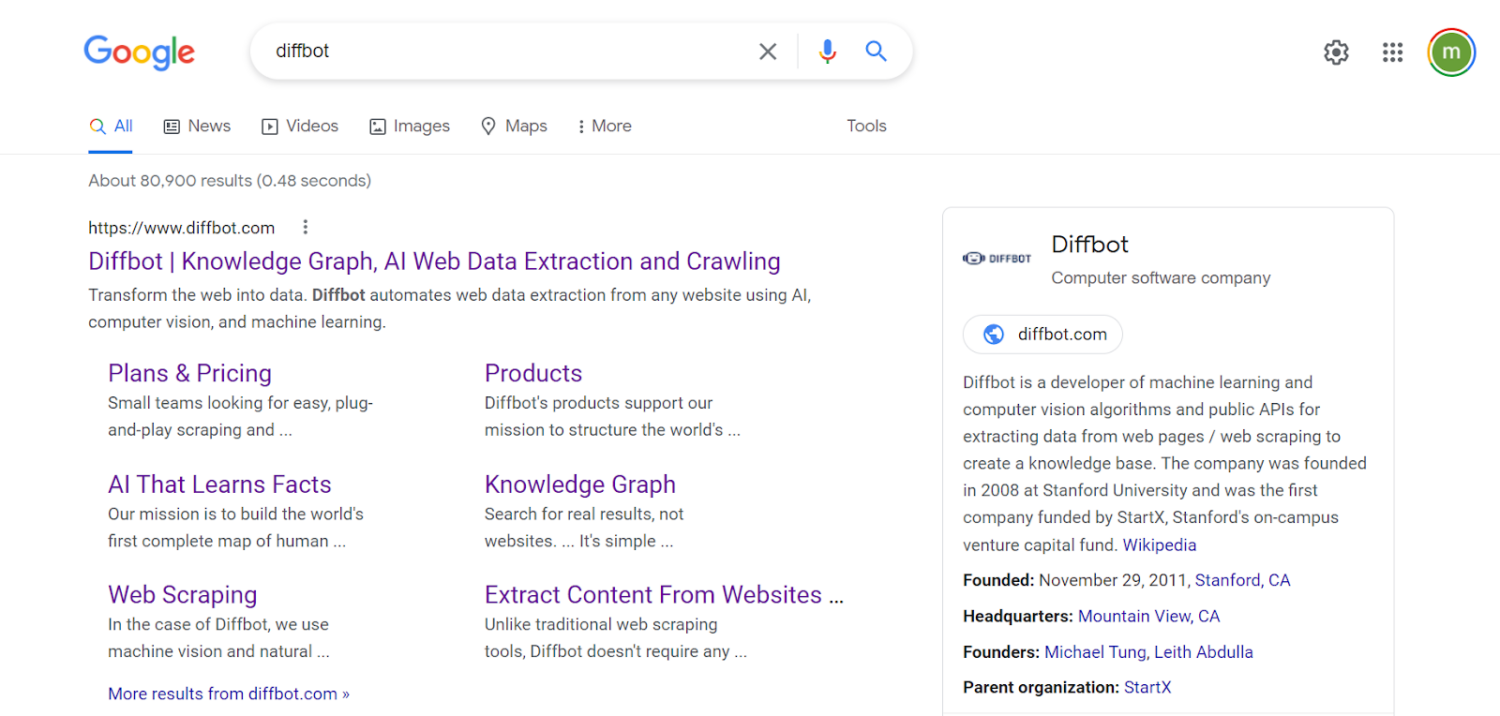
The area to the right in the screenshot above is the Google knowledge graph-derived knowledge panel. Facts included in these panels are typical of linked data, wherein the organization entity of Diffbot is attached to other knowledge graph entities including locations, people, and other organizations.
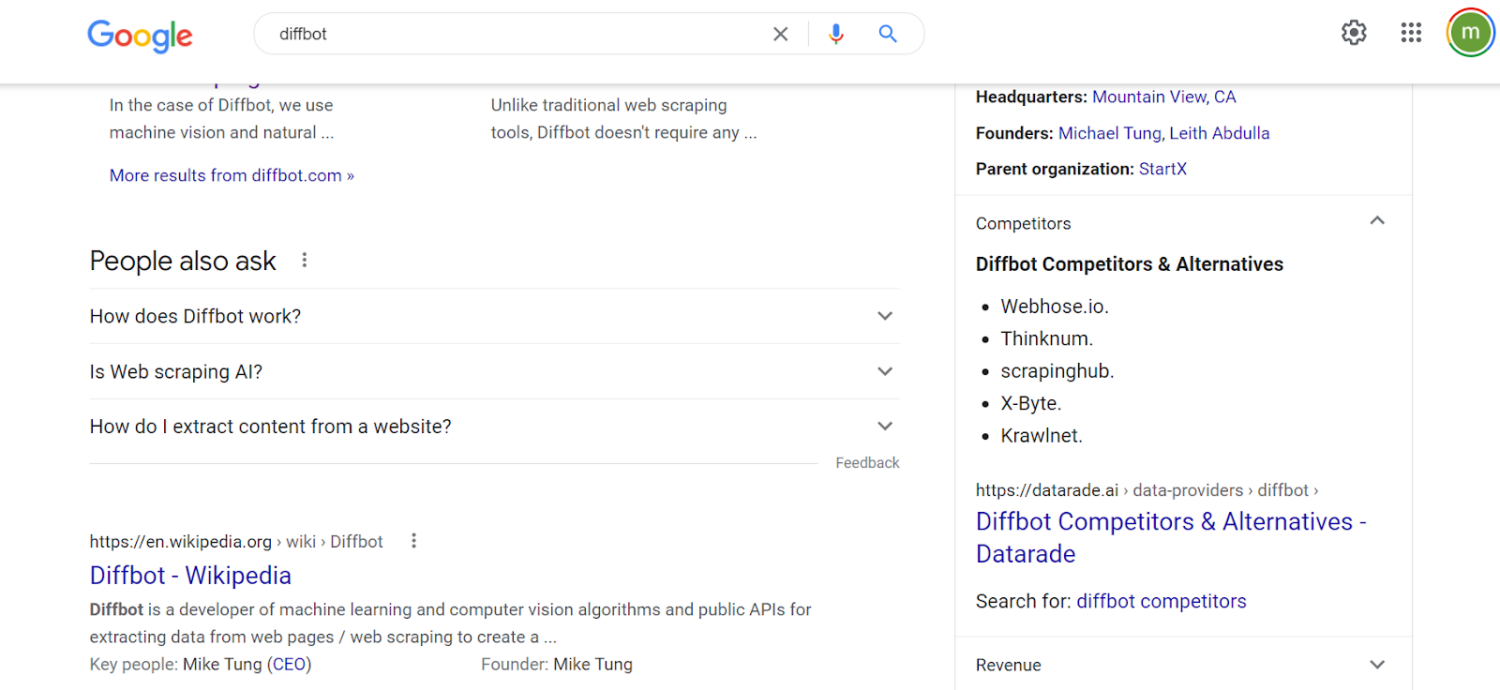
Furthermore, the result is enhanced by additional content. If we click through to competitors, Google can serve up and highlight a portion of content that claims to be about competitors. But even though Webhose, Thinknum, Scrapinghub and others listed all have their own knowledge graph entries, this data isn’t linked. The NLP by which Google is parsing content to categorize and serve up this article on competitors is not integrated into the Google knowledge graph. Clicking through to the headline about competitors does not lead to knowledge panel-related data. But rather takes you to an article that is the top ranking result of the search “Diffbot competitors.”

Let’s take another example, wherein we look at a publicly traded company. Searching “Microsoft Revenue” returns the Microsoft knowledge panel as well as the most recent publicly listed revenue number. A great number of fields displayed here are from the Google knowledge graph API. But clicking through to the disclaimer below financial data takes us to Google Finance, a separate service from Google’s knowledge graph. Linked data is present in the “people also search for” section. And each of these organizations does have their own knowledge panel result. But at the end of the day, clicking through any of these simply routes users to a suggested search.
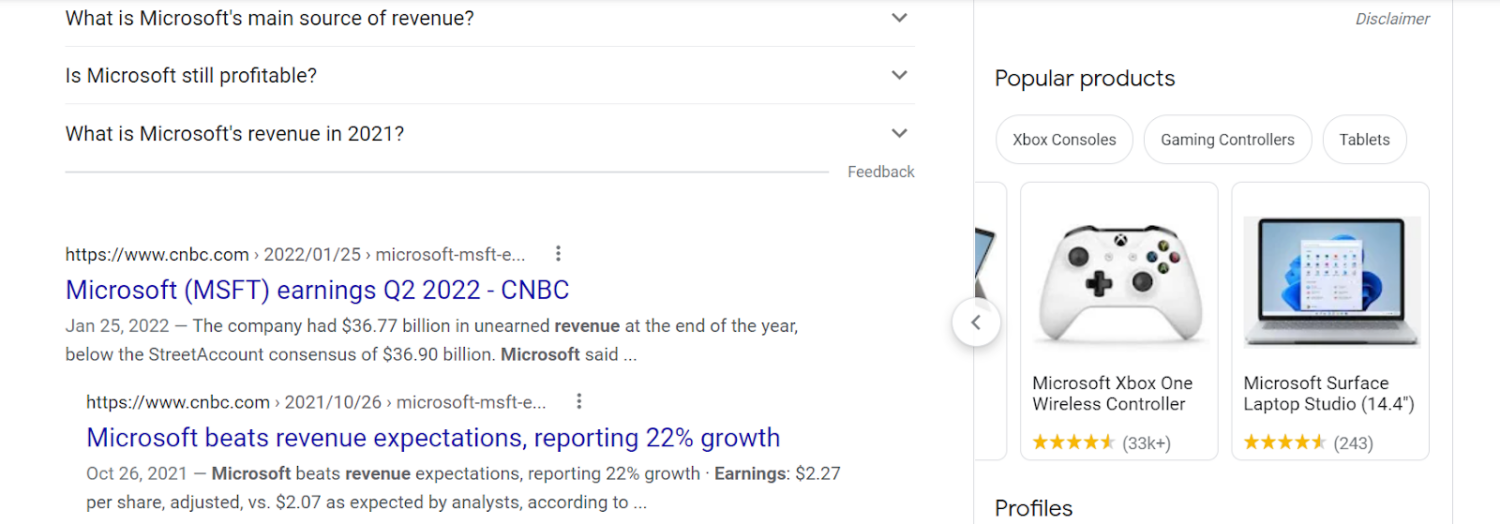
Dropping to the bottom of the knowledge panel for Microsoft, yet again we see the appearance of linked data. In this case products that are related to Microsoft. But clicking through to each simply returns search results (albeit aggregated values related to price, availability, and reviews). We can verify that this product data is not in fact part of Google knowledge graph by searching for a “Microsoft Xbox One Wireless Controller” using the knowledge graph search API.
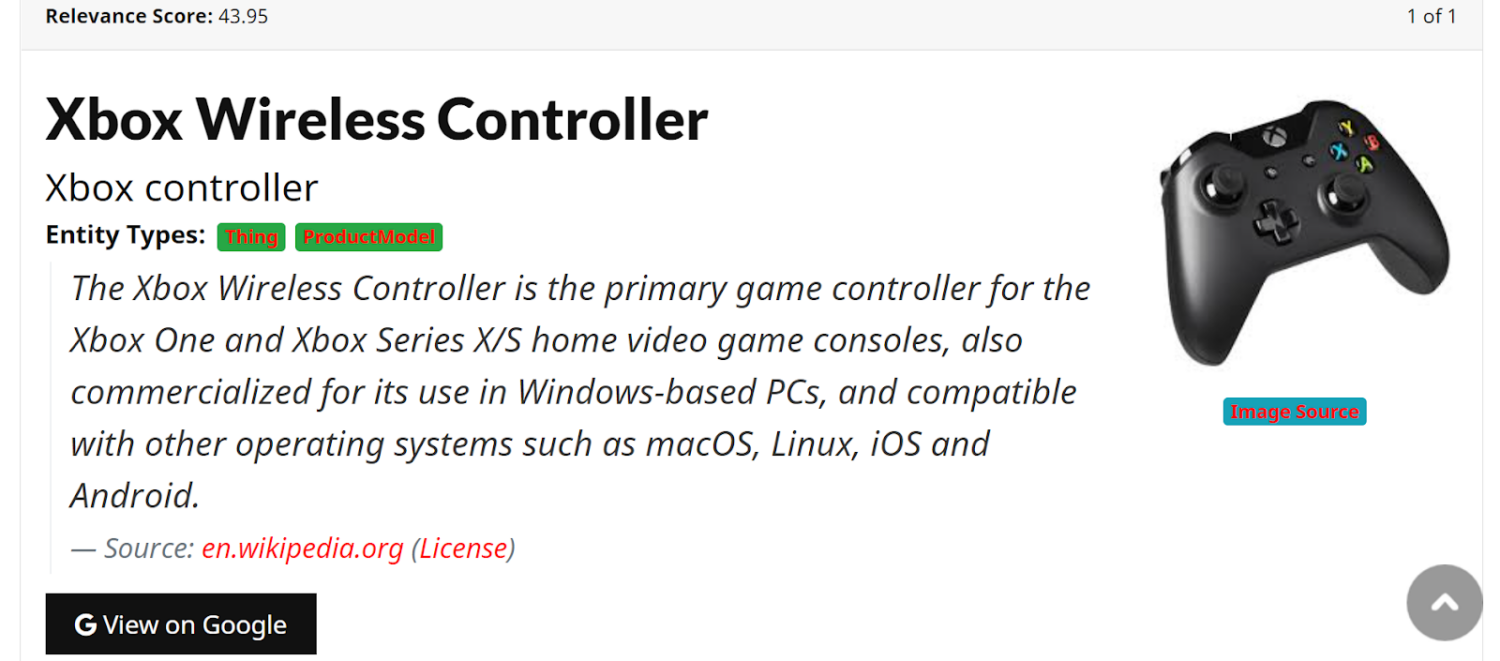
Above is the result for a Google knowledge graph API search for a particular model of XBOX controller (an XBOX One controller) that is served up within the knowledge panel results. What is returned is a general category of “XBOX controller” sourced from Wikipedia, with entity types of “thing” and “productModel.” The closest entity to what was served within the knowledge panel as actually a somewhat generic category of products. The “XBOX One Controller” from the knowledge panel actually isn’t from the Google knowledge graph.
All this hints at the fact that Google pads out the appearance of their knowledge graph in it’s most prevalent form (knowledge panel results) while not actually ingesting and linking many of these additional data structures.
Sure, Google crawls the entire web to return search results. But what does a large portion of this crawling have to do with their knowledge graph?
This distinction between Google’s search-related crawls and their knowledge graph data likely begins with Freebase. Freebase was rolled into an early version of Google’s knowledge graph after the company was acquired. Freebase largely crowdsourced knowledge, allowing users to manually tag, relate, update, and create their own knowledge bases. While this enabled some scale (2.4B facts as of 2014), little automation was factored into fact accumulation. While Freebase compiled one of the largest commercially-aimed knowledge bases, they did so manually.
Freebase’s data pipeline didn’t really have anything to do with Google’s automated knowledge accumulation that powers their search engine.
You don’t have to take our word for it, see Google’s own description:
“Facts in the Knowledge Graph come from a variety of sources that compile factual information. In addition to public sources, we license data to provide information such as sports scores, stock prices, and weather forecasts. We also receive factual information directly from content owners in various ways, including from those who suggest changes to knowledge panels they’ve claimed.”
Or put another way: “it’s a bit amusing that i’ve been invited to speak at a conference on automated knowledge base construction because both in the world I work and my background I don’t know anything about the automated side of this. The world I work in is far from automated. We have automated processes and things like that. But in terms of knowledge base construction, the world I work in is really one of a watchmaker. A precision scientist.” – Jamie Taylor, Decade-long leader at Freebase (now Google Knowledge Graph)
While Google’s knowledge graph is certainly a massive knowledge base, the inclusion of core constituents that are manually sourced including “claimed” (human sourced) knowledge panels and Freebase point to a knowledge graph primarily based on human inputs.
How Diffbot Crawls the Web
For comparison, Diffbot’s web crawling was always set up as a way to extract, structure, validate, and link data across the web in an automated way (see “The Economics of Building Knowledge Bases”) . Our original product line of AI-enabled automatic extraction APIs were meant to be able to extract valuable facts and information from a variety of page types without even seeing their format in advance. Over time, crawling infrastructure as well as the ability to link and apply automated inference and understanding on top of these page crawls enabled our Knowledge Graph.
How does this work?
Early research shows us that a large majority of the internet was composed of 9 separate “types” or pages. Think of these pages like articles, discussions, profiles, product pages, event pages, lists, and so forth.
Across languages and sites, the “types” of information that humans tend to find valuable on these page types persists. For example, whether you’re on Amazon or Walmart’s websites, some of the valuable data types on a product page include reviews, price, availability, a picture, and product specifications. These commonalities allow Diffbot to automatically extract information humans care about in a standardized format even if the actual layout of pages is different. All of this with no human input.
Once facts, underlying text, images, and metadata are extracted, powerful natural language processing tech can transform these inputs into entities and relationships (constructing a graph).
Because they provide information and context, graph databases are one of the most well suited data sources for machine learning. We leverage ML over our graph to incorporate new fact types such as similarity scores, enhanced organizational descriptors, and estimated revenue of private organizations.
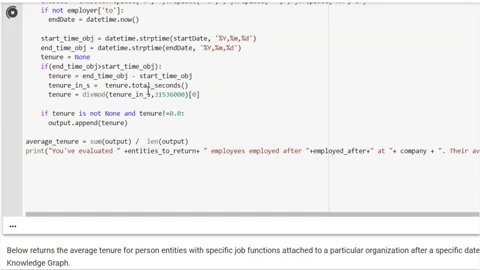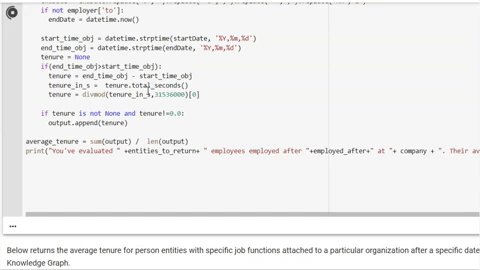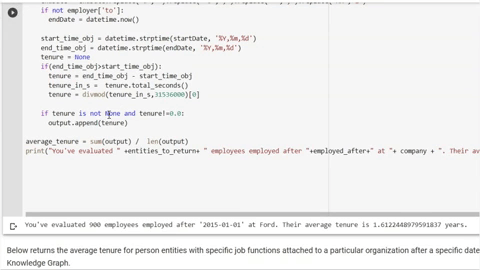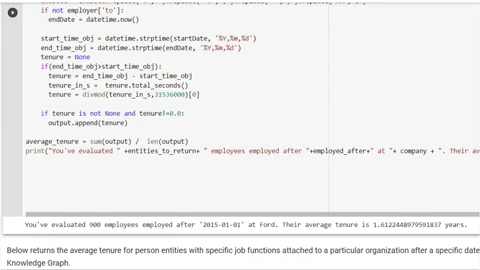
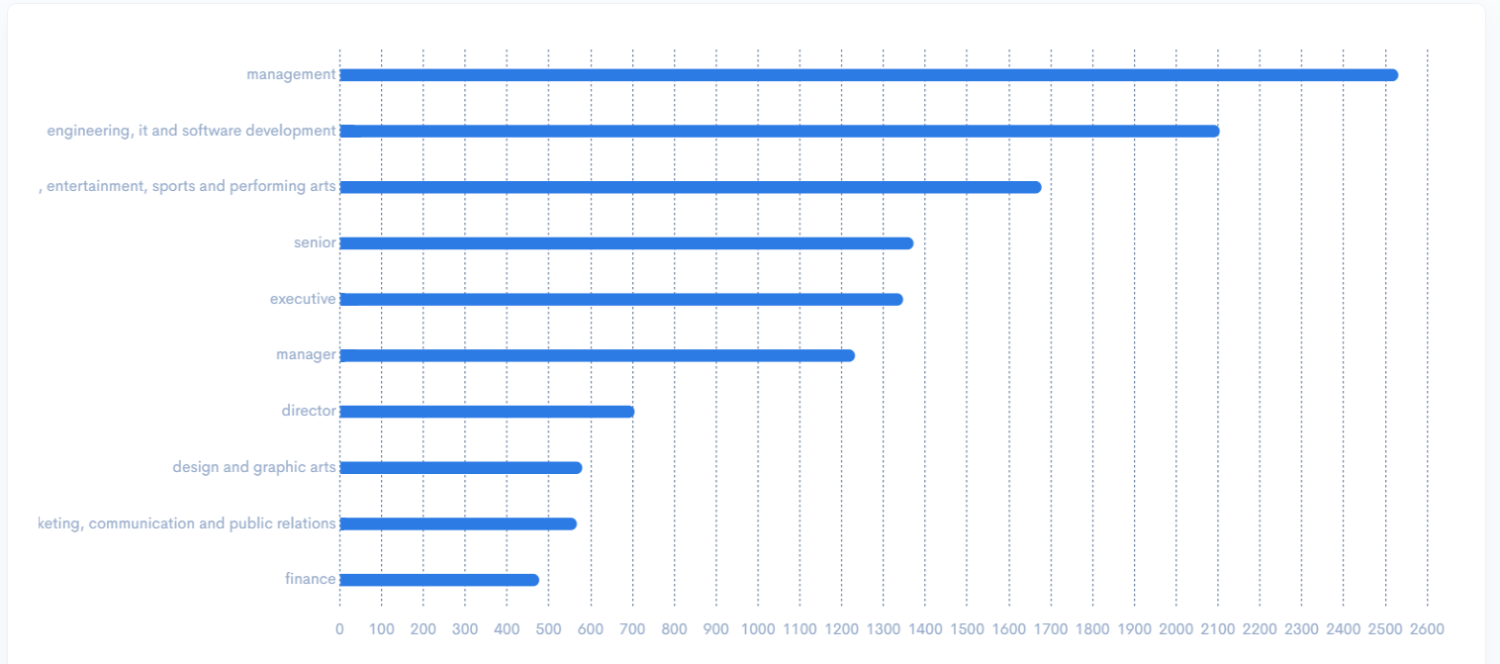
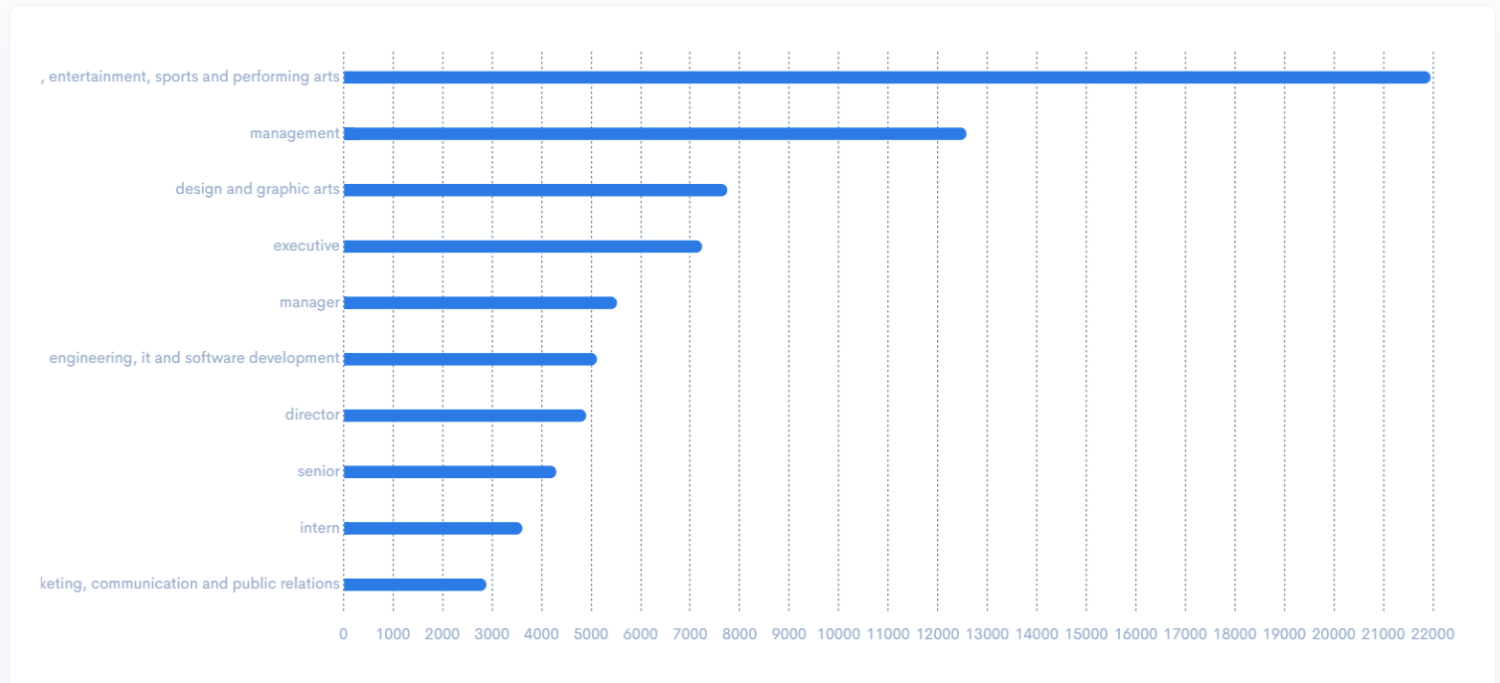
The range of automated inputs allow Diffbot’s Knowledge Graph to cover a huge range of commercially interesting data types. As of the time of this article’s writing, our data coverage included the following, all linked and with an average of 31 facts per entity:
- 243MM organization entities
- 773MM person entities
- 1,879MM image entities
- 1,621 article entities
- 880MM post entities
- 128MM discussion entities
- 141MM product entities
- 89MM video entities
- 20MM job entities
- 42MM event entities
- .56M FAQ entities
- 73MM miscellaneous entities
- 10MM place entities
- 49MM creativeWork entities
- .17MM intangible entities
Total: 5,953MM entities
We’ll jump into additional comparisons of data within Diffbot and Google knowledge graphs in the next section. But hopefully you can begin to see the fundamental differences between a Knowledge Graph built for automated fact accumulation from the start (Diffbot) and one built with manual processes (Google).
Benchmarking Google And Diffbot’s Knowledge Graphs
While there are substantial coverage differences between entity types in Google and Diffbot knowledge graphs, organization entities are well represented in both. Organization entities are also of broad commercial interest, with uses ranging from market intelligence, to supply chain risk analysis, to sales prospecting.
For our study of Google and Diffbot knowledge graph organizational coverage, we looked at a representative number of randomized head entity and long tail organizations. Head entity organizations in this case are publicly-traded companies randomly chosen from the Russel 2000 index. Long tail entities include a random sampling of Series A and earlier startups with less than 50 employees.
For both head entity and long tail organizations, we sought out external records of truth on a range of fields including:
- CEO
- Headquarter location
- Number of employees
- Revenue
- And homepage URL
Example “ground truth” publications included SEC financial filings, Crunchbase, and Linkedin.
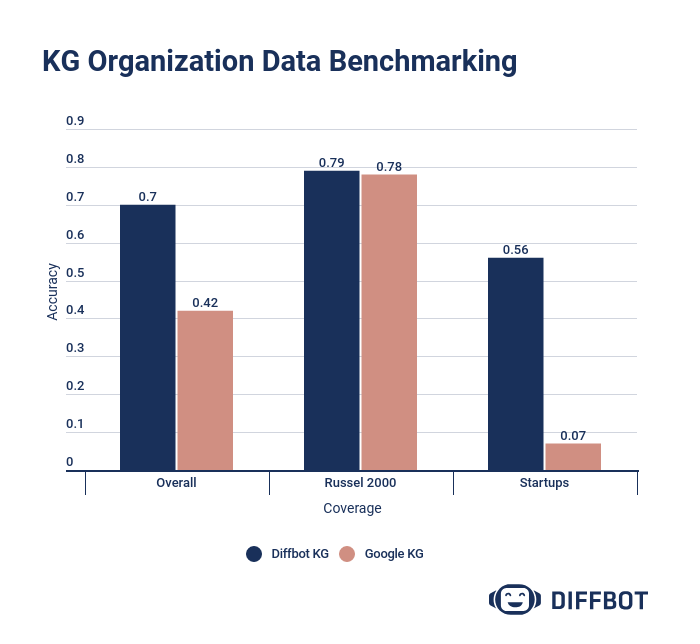
The results of our analysis show strong coverage of head entities across both knowledge graph providers. In this instance, lack of coverage centered around missing “ground truth” revenue fields in the case of several publicly traded companies who are yet to generate revenue.
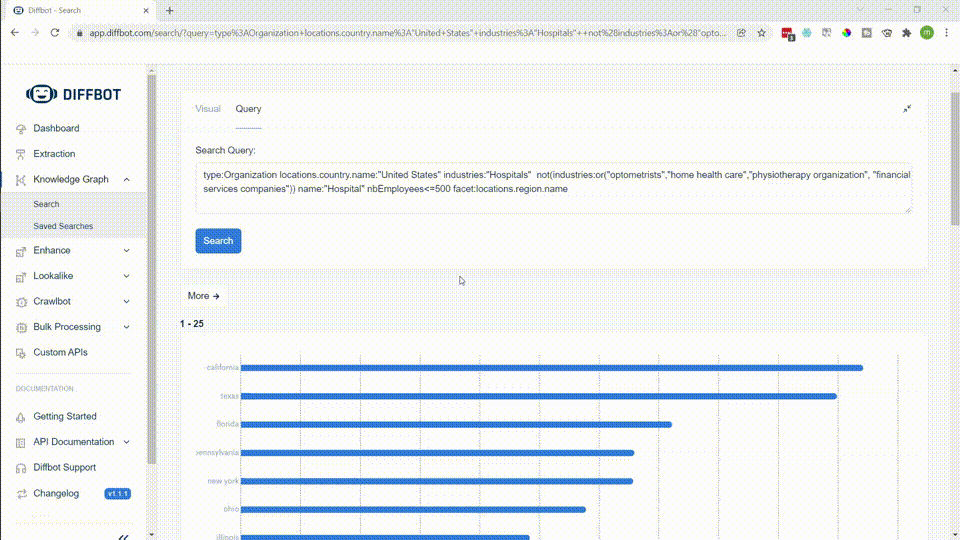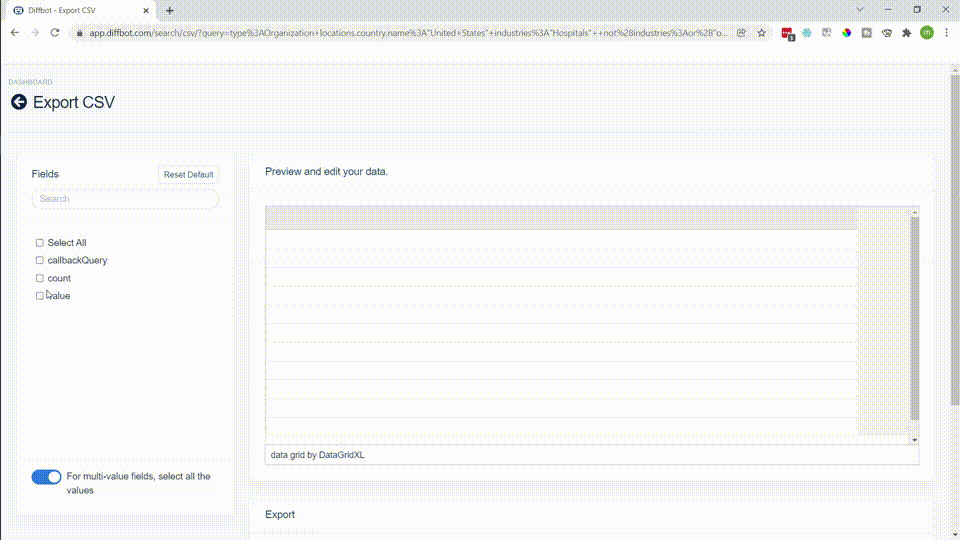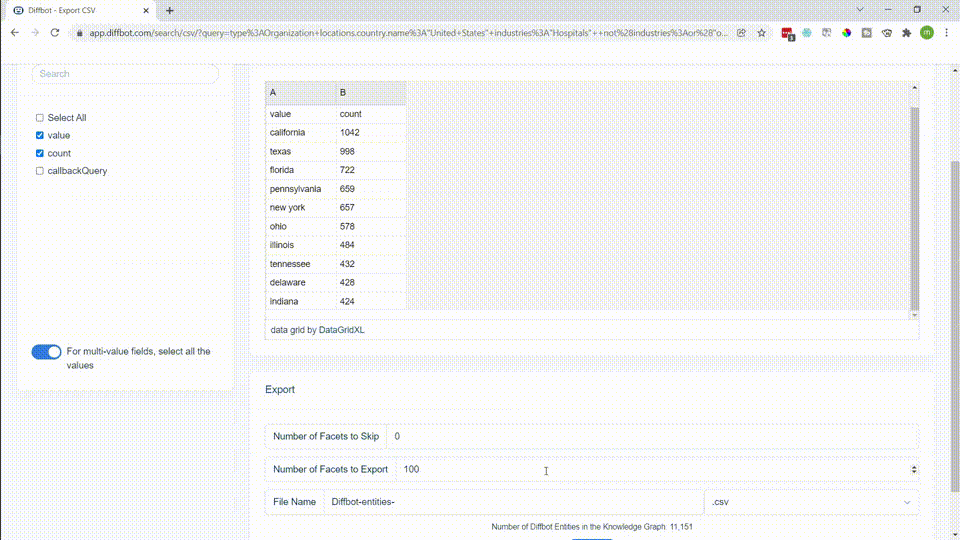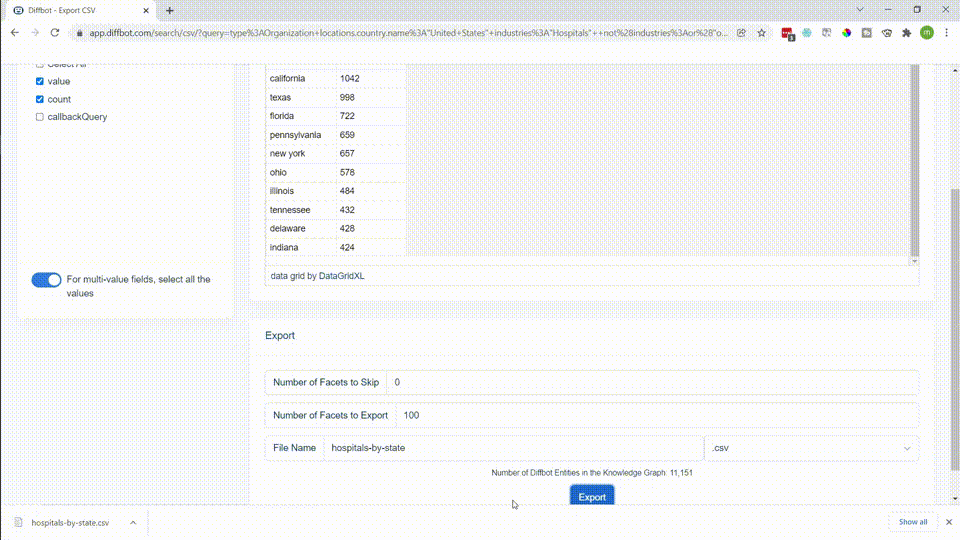
Among startups, a substantial spread emerged. For many uses, SMB/MMKT data is particularly hard to come by at scale, and Diffbot’s coverage includes 100’s of millions of “longtail” entities.
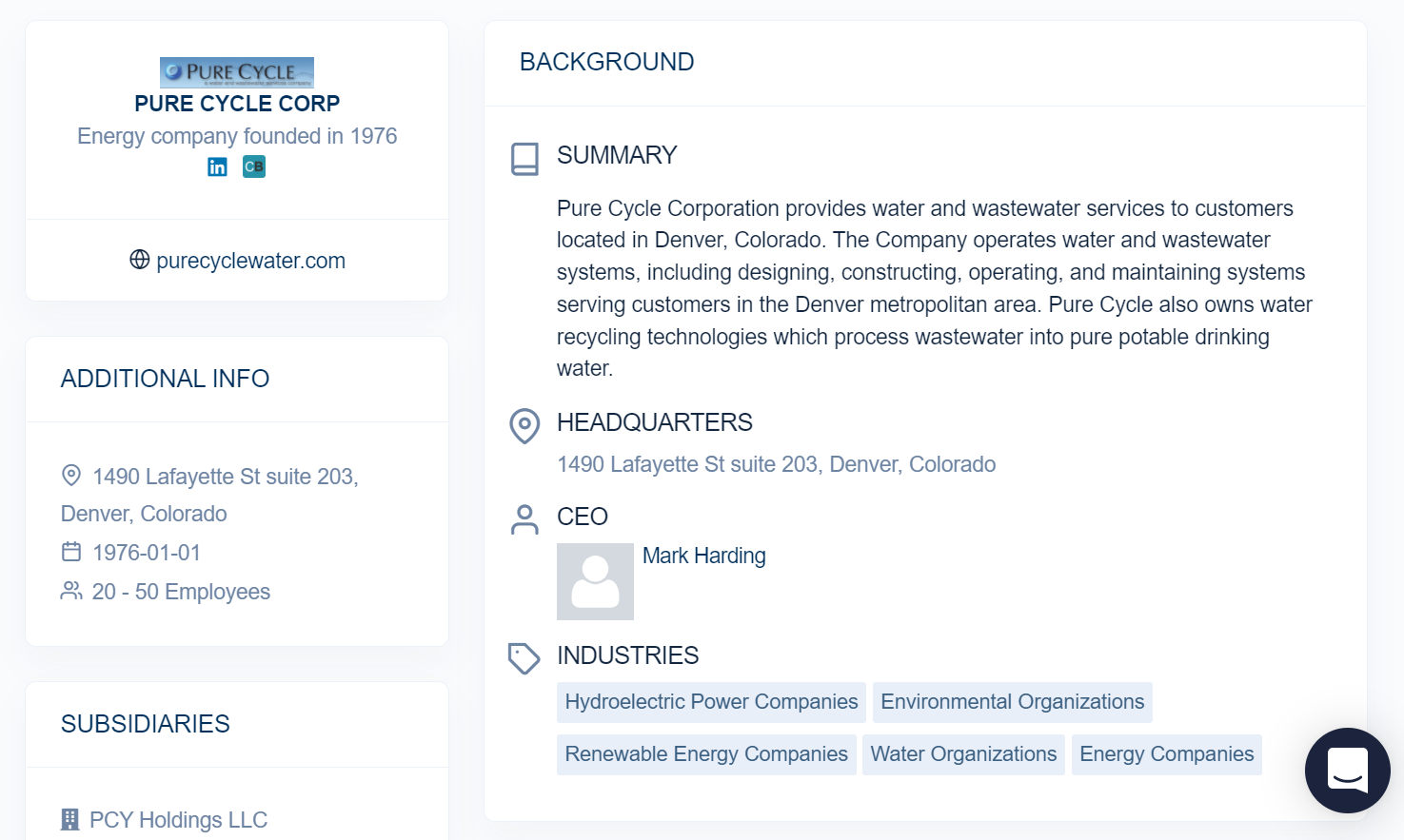
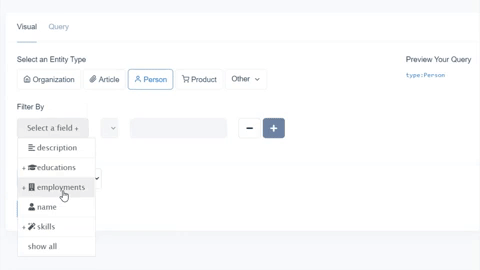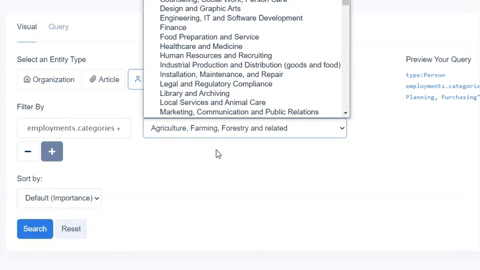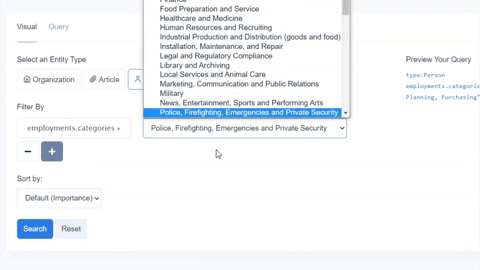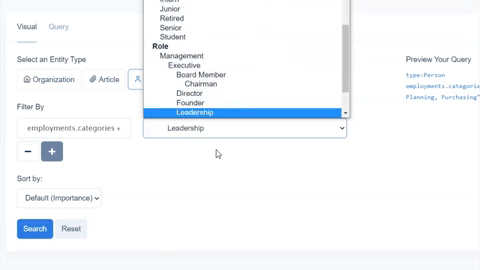
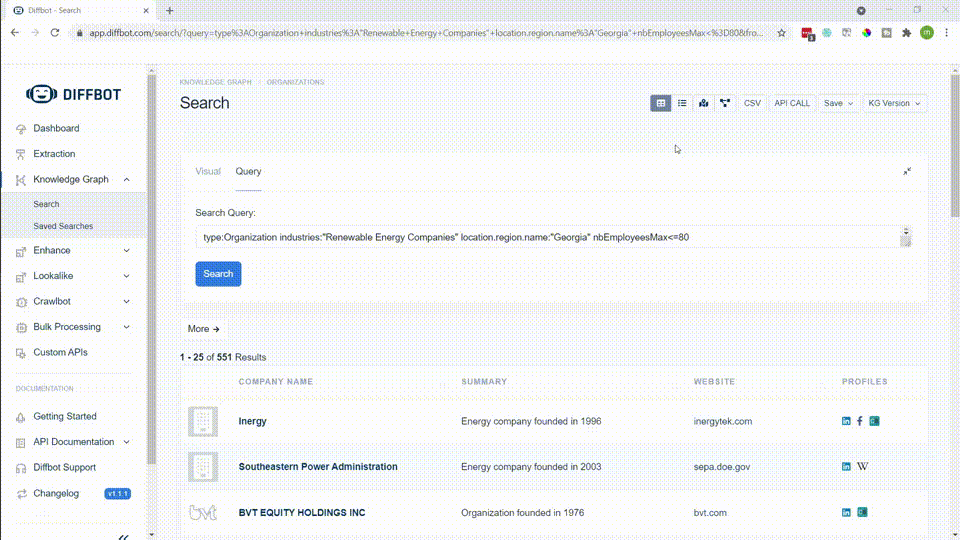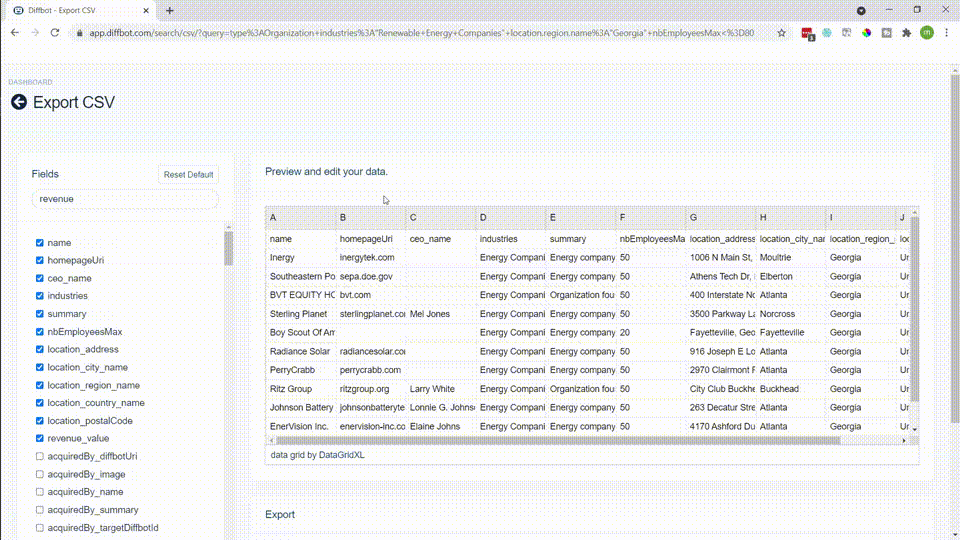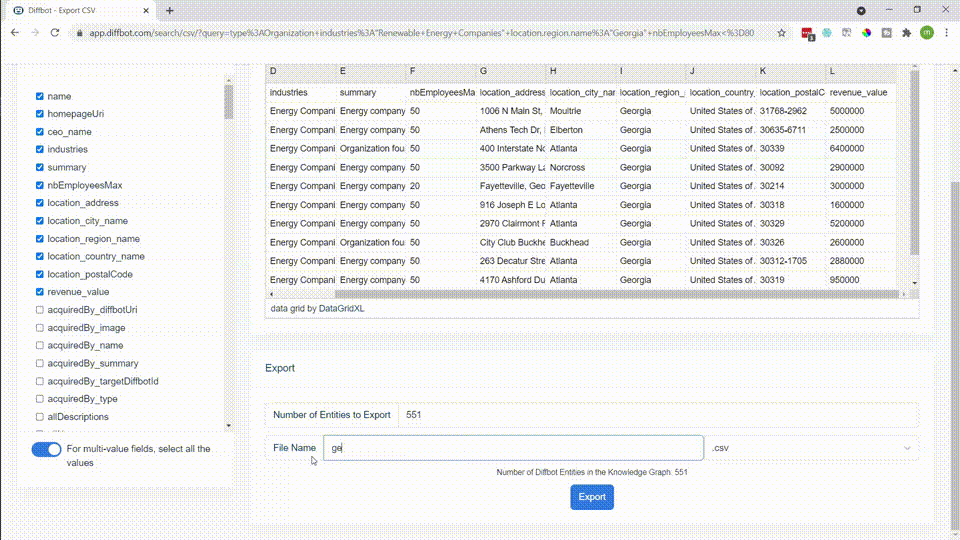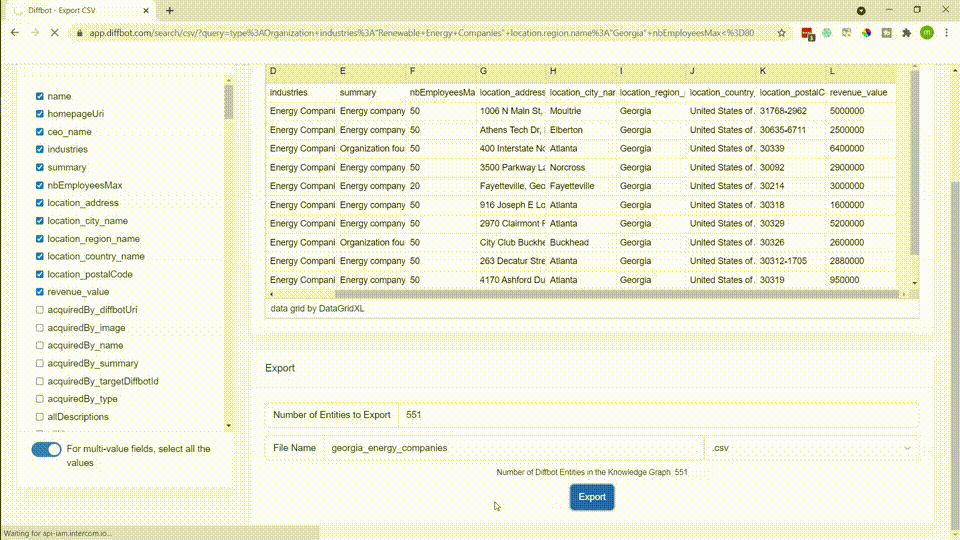
While we chose fields present for organizations in both knowledge graphs, Diffbot’s Knowledge Graph also provides a wider range of additional fields. Above is a screenshot from our Knowledge Graph search visual interface. But additional fields attached to most organization entities within the Knowledge Graph include:
- Noteworthy Employees
- News Coverage
- Industries
- Locations
- Subsidiaries
- Funding Rounds
- Descriptions
- Revenue (or estimated revenue)
- Similar organizations
- Technologies used
- Among many other fields.
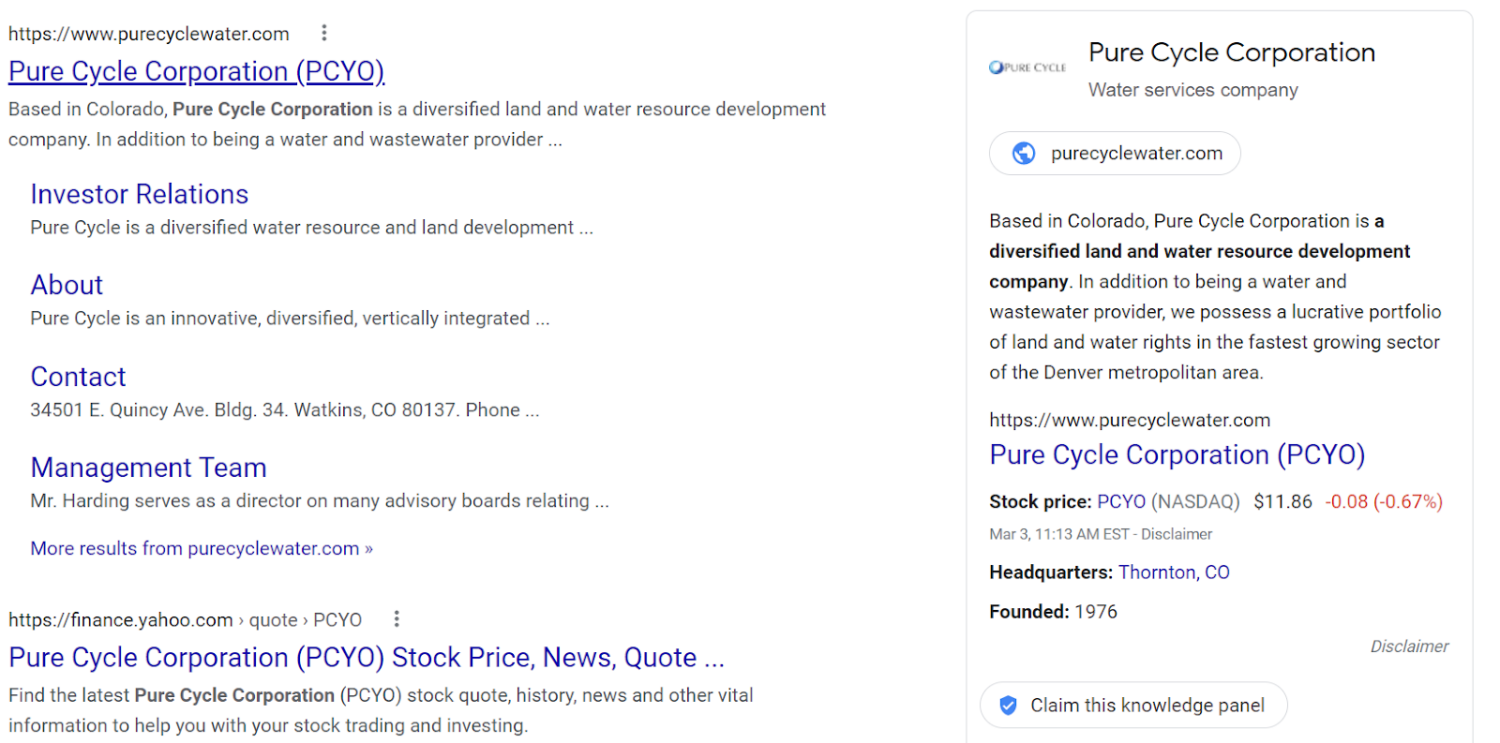
In the Google knowledge graph derived knowledge panel, the only three fields not presented by an external API (Google Finance) are a brief description, the URL of the organization, and the logo.
While we’ve presented but a handful of samples within this article, Diffbot routinely benchmarks wide ranges of our knowledge graph against competitors and can patently say we have the world’s most accurate and up-to-date large-scale knowledge graph.
Interested in exploring Diffbot Knowledge Graph data for yourself? Grab a free trial or reach out to our sales team for a custom demo.

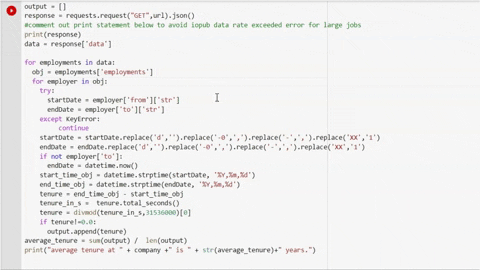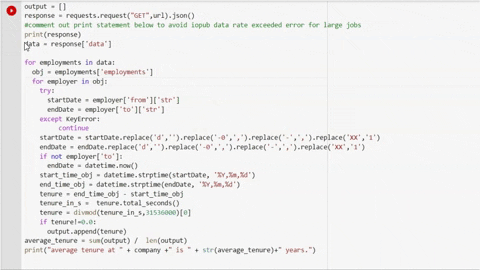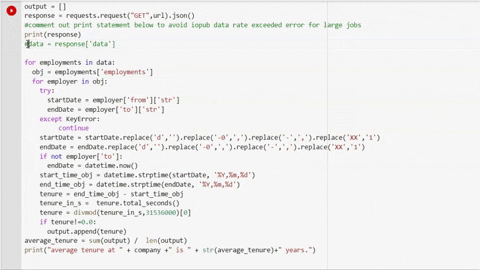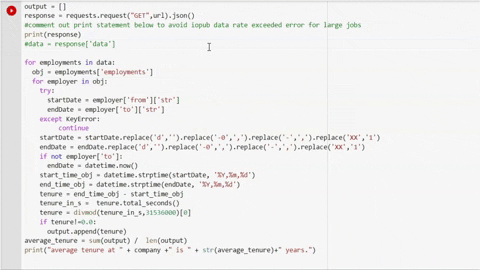


")
")
")

















You must be logged in to post a comment.