During the summers of my high school years in suburban Georgia, my friend and I would fill the time by randomly walking into local establishments asking for odd jobs. It was a great way as a student to meet people from all walks of life and learn about different industries. We interviewed to be warehouse forklift operators, car salesmen, baristas, wait staff, and lab technicians.
One of the jobs that left an impression for me was working for AT&T (BellSouth) in their fulfillment center doing data entry and taking technical support calls. It was an ideal high school job. We were getting paid $9 per hour to play with computers, talk on the phones to people dialing in from all across the country (mostly those having problems with their fax machines and Caller ID devices), and interact with adults in the office.
In the data entry department, our task would be to take in large pallets of postal mail, open each envelope, determine which program or promotion they were submitting to, enter in the information on the form into the internal CRM, and then move on to the next bin.
This setup looked something like this:
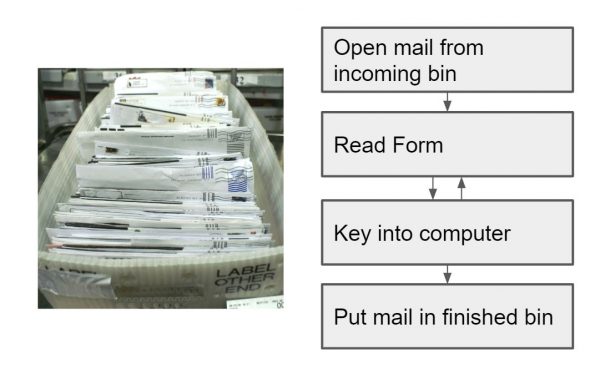
Given each form contained about 6 fields, and each field had about 10 words, typing at 60 words per minute meant that it took on average a minute to key in each form. At $9 / hour, this translates to $0.025 to obtain each field being entered into their CRM. This is a lower bound to the true cost, as it doesn’t include the costs to the customer of filling out this form, the cost of mailing this letter to the fulfillment center, and the costs of the overhead of the organization itself, which would increase this estimate by a couple factors more.
What limits the speed, and therefore cost, of data acquisition? Notice that in the above diagram, the main bottleneck and majority of the time spent is in the back-and-forth feedback loop that takes place between reading and typing. This internal feedback loop is tied to the human brain’s ability to process symbols on the page, chunk them into bits of meaning, and plan a sequence of motor actions in my fingers that result in keystrokes.
As far as knowledge work goes, this setup is quite minimalist, as I am only entering in information from a single information source (the paper form); most knowledge work involves combining information from multiple sources, and sometimes synthesizing and reconciling competing pieces of information to produce an output. However, note that the largest bottleneck of any knowledge acquisition job is not actually the speed or words per minute that I can type. Even with access to a perfect high-bandwidth human-machine interface via a neural lace directly wiring the motor and somatosensory cortex of my brain to the computer, the main bottleneck would still be the speed in which I could read and understand the words on the page (language processing is largely believed to be happening in the Broca’s region of the brain).
Manual data collection like the setup of my summer job is by far the most prevalent form of building digital knowledge bases, and has persisted from the beginning of digital computers til the present day. In fact, one of the original motivations for creating computer companies was to enable this task. The founder of original computer company, IBM, was motivated in part by his work in compiling the 1880 US census, one of the first databases.
While we can scale up the knowledge acquisition effort (i.e. we can build larger knowledge bases) by hiring larger teams of people to work in parallel, this would simply be an aggregation of labor, and not a net gain in productivity. The unit economics (i.e. the cost per field) wouldn’t change, we’d simply be paying more for a larger team of humans, and it would in fact go up a bit due to the overhead cost of coordinating the team of humans. For many decades, due to the growth of the modern corporation, this is how we got larger and larger knowledge bases, including Cyc, one of the early efforts to build a knowledge base for AI, which contained 21M fields. Most knowledge bases today are constructed by an organization of people trained to do the task. However, something was brewing in the mid-90s that would change this cost structure forever.
That step-function change was the Internet. A growing global network of inter-connected computers meant a large increase in the addressable labor pool (millions, and then later billions of people), and access to global economies with lower wages. The biggest change though, was that a lot of people spent their “free” time on the Internet. This allowed sites like Wikipedia to flourish, which can be viewed as a knowledge base built by a global community of contributors. This dramatically lowers the effective cost of each record, as most of the users don’t view building the knowledge base as their primary means of employment, but a volunteering activity or hobby. Building a knowledge resource like Wikipedia would have been very prohibitively expensive for a single organization to execute on pre-Internet.
A startup called MetaWeb leveraged crowdsourcing in order to build a knowledge base called Freebase. Importing much of Wikipedia and with a wiki-style web-based editor, they were able to build the size of the knowledge base up to 1.9B fields. This represented a 100X improvement in the cost of acquiring each field in the knowledge base. Freebase was summarily shut down when MetaWeb was acquired by Google, however its Wikipedia origins are why many of the knowledge graph panels that Google returns are based on Wikipedia pages.
Crowdsourcing has become an effective technique for maintaining large publicly-accessible knowledge bases. For example, IMDB, Foursquare, Yelp, and the Google Knowledge panels all take advantage of Internet users to curate, complete, and find errors in those knowledge bases. While crowdsourcing has been great in enabling the creation of these very useful datasets and tools, it has its limitations as well. The key limitation is that it is only possible to crowdsource the construction of a database in certain areas of knowledge where there is a sufficient level of mass-market popularity to form an online community of users, typically 100k or more. This is why, as a general rule, we tend to see crowd-sourced knowledge bases in the domains of celebrities (Wikipedia pages), movies (IMDB), restaurants (Yelp), and other entertainment activities but not scientific and business activities (e.g. drug interactions, vendor databases, financial market data, business intelligence, legal records). This is because, unlike leisure, work requires specialized knowledge, and there are not online communities of 100k specialists in each area.
So what technology will enable the next 100X breakthrough in knowledge acquisition?
Naturally, to go beyond the limitations of groups of humans, we will have to turn to artificial intelligence for acquiring knowledge. This field is called Automated Knowledge base construction, and is the focus at Diffbot. At Diffbot, we have developed a commercial system that combines multiple areas of research–visual extraction of webpages, natural language processing, computer vision, and knowledge fusion–to build an automonous system that can build a production-level knowledge base. Because the fields in the knowledge base are not gathered by humans but by an AI system that is synthesizing multiple documents, the domains of knowledge are not limited to what is popular, and and it now becomes economically feasible to acquire the kind of knowledge that is useful for business applications.
Here is a summary of the unit economics of various methods of building knowledge bases. Much credit goes to Heiko Paulheim, for his analysis framework in “How much is a Triple?” (ISWC ’18), which I have merely updated with my own estimates and calculations.
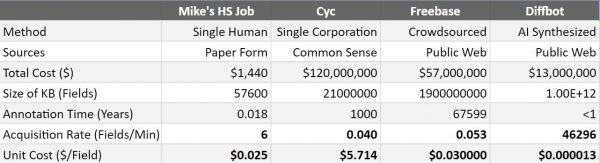
The above framework makes some simplifying assumptions. For example, it treats the economic task of building a knowledge base as building a static resource, of a fixed size. However, we all know that the real value of a knowledge base is in how accurately it reflects the real world, which is always changing. Just as we perform a census once every 10 years, the calculations above don’t take into account the cost of refreshing and maintaining the data, as an ongoing knowledge service that is expressed per unit time. Business applications require data that is updated with a frequency of weeks, days, and even seconds. This is an area where the AI factor is even more pronounced. More on this later…
You must be logged in to post a comment.