
Harnessing the public web as data is one of the smartest things product, marketing, PR, and machine learning teams can do. It also opens up a host of questions.
- What type of data is valuable to us?
- How accurate do we need our data to be?
- How timely do we need our data to be?
- What are our data sources?
The answers to these questions will inform many aspects of your web data strategy. And should inform whether you provide for your data extraction and maintenance needs in house or from a firm that specializes in web extraction.
In this guide we’ll look at two of the most prominent web data extraction providers: Diffbot and Import.io.
We’ll look at the process of extracting data from the web through both service providers and expose some foundational differences about what data is extracted, and how data is processed (or not).
Additionally, we’ll look at categorical differences between what these providers supply.
Notably, the difference between a web data extraction provider and Knowledge-As-A-Service provider.
Table of Contents:
- How to Extract Data with Import.io
- How to Extract Data with Diffbot
- Web Data Extraction Versus Knowledge-As-A-Service
- Analysis of Import.io Offerings
- Analysis of Diffbot Offerings
How to Extract Data with Import.io
Import.io offers one of the most beginner-friendly web extraction solutions available. For data that is already somewhat structured, simply inputting a URL will pull up a rendering of the page and what data Import.io believes you want extracted.
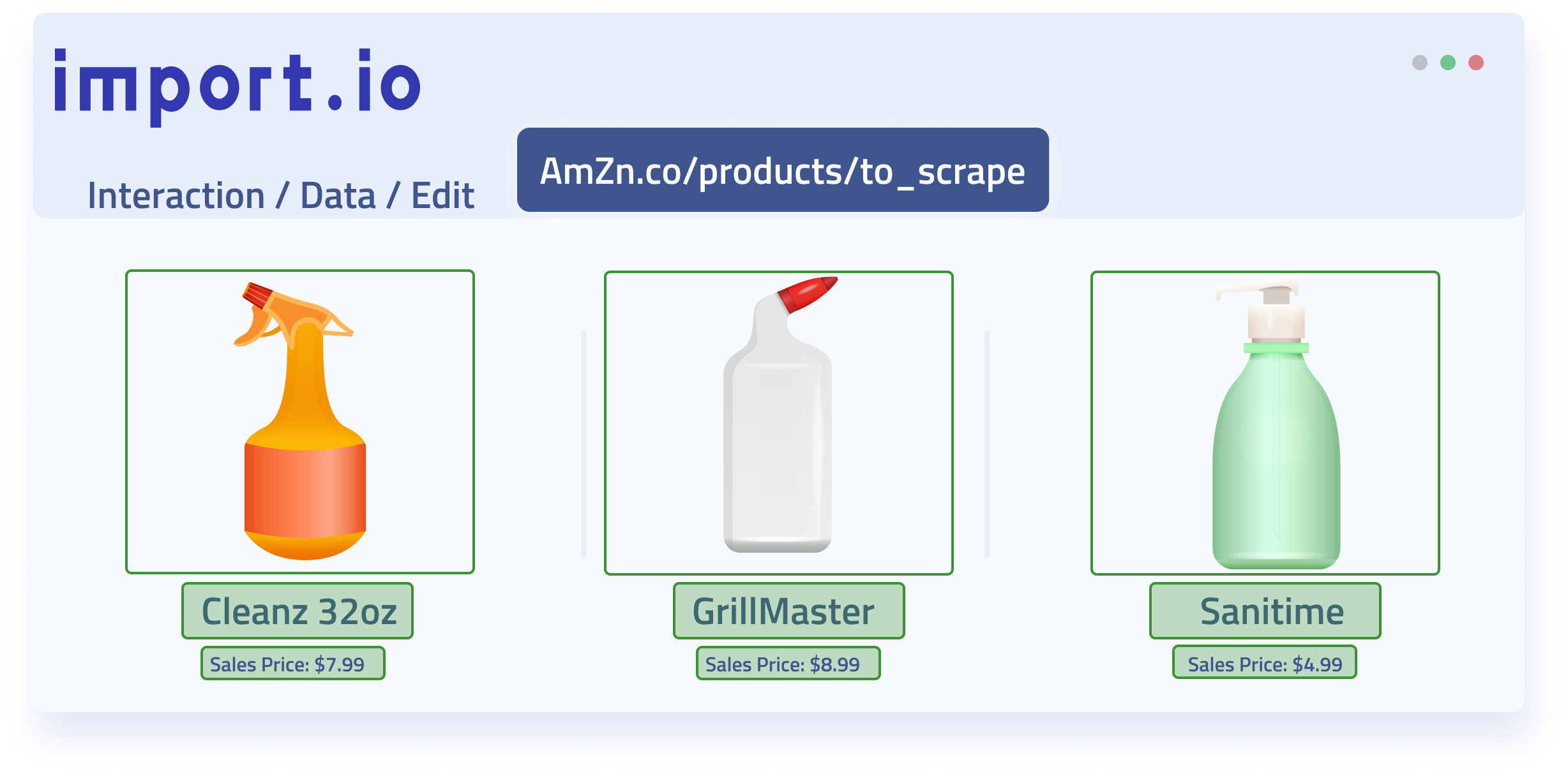
For well-known sites and single pages, this typically works as expected. We tried it out on Amazon search results for “Vitamin C.” The resulting fields of data included:
- Product title
- Product Page Link
- Pricing Data
- Sale Pricing Data
- Availability
- Average review scores
Essentially, Import.io quickly extracted all visual and non-visual front end data from items on the search result page.
Additionally you can train the extractor on multiple pages. This is helpful in the event you’re going to want to extract across paginated pages or pages that are slightly different to one another.
Once you save your scraper you can set your scrape to a given schedule as well as import a list of urls to extract from. With the help of a crawling tool such as Screaming Frog one can quickly input entire sections of sites to be crawled.
Granted, Import.io works right out of the box with selection of elements to be extracted via the UI for many major sites. For sites where data is less well structured, or where you may need to perform a complex series of interactions to get to the data, however, less technical users may be up for a challenge. Xpath and Regular Expressions can be used to hone what Import.io is trying to extract. But those are also processes many less technical users may not be up for.
Web Data Integration Solutions
Now extraction of single or small batches of pages are really just the start of what Import.io does. Import.io bill themselves out as providers of web data integration solutions. What they mean by this is that they provide support for some post-extraction processing as well as the consuming of these data feeds.
In particular, Import.io offers the following features for Premium account holders:
- The ability to set up interactions with a page to surface data you’re after
- Data transforms that take a data feed, and process the data in some pre-specified manner before being sent your way
- The ability to only extract data that has changed since the last data extraction process
- Reporting on when extractions were run, the results of extractions, and changes to your data
- Visualization of data
- Depending on your tier of service, a team of data extraction specialists to help get your data extraction set up
Together these features can take a one-off extraction and turn it into an ongoing data stream to be consumed in spreadsheets, dashboards, or apps of your choosing.
Import.io is trusted by many industry leaders and holds a strong place within the web data extraction industry. But as we’ll see in the following section, there are categorical differences between aid in data extraction (as Import.io provides) and the creation of web-based knowledge.
How to Extract Data with Diffbot
Diffbot’s mission is to help individuals turn unstructured web data into insightful structured information. We’re a Knowledge-as-a-Service provider, and we accomplish this through several routes. While Diffbot’s web data extraction products are largely built on the same underlying technologies, there’s likely one or two products that will help you to achieve your unique web data sourcing needs more directly.
The three primary ways to gain access to extracted data via Diffbot include:
- Diffbot’s Automatic Extraction APIs
- Diffbot’s Knowledge Graph
- And Diffbot’s Enhance Product
Diffbot’s Automatic Extraction APIs are some of the underlying tech that powers Diffbot’s other products. While not the preferred extraction method for non-technical users, it’s worth being aware of how the Automatic Extraction APIs work if you’re going to be using any of Diffbot’s products.
These powerful extraction APIs are built to provide rule-less data extraction for page types that comprise more than 98% of the public web. Machine vision and natural language processing systems in our extraction APIs don’t just extract data from the pages you provide, they understand what the data means.
This means you aren’t just pulling unstructured data from the web and manipulating its formatting. Rather, you’re extracting unstructured data and letting our cutting-edge AI turn it into information (for more on this, read about the DIKW Pyramid).
Our Automatic Extraction APIs are broken into individual APIs depending on the type of data you want to extract. These include:
- The Article Extraction API
- The Discussion Extraction API
- The Image Extraction API
- The Product Extraction API
- And the Video Extraction API
Additionally, if you want all data types returned from a given domain, you can point the Analyze API to a location.
The results of your extraction via one of the above APIs mirrors the structure of data contained in Diffbot’s Knowledge Graph. You can think of our Knowledge Graph as the result of pointing the above APIs at billions of web pages every few days, followed by additional processing to ensure the proper assimilation of facts from across the web.
Remember how we mentioned that our AI-enabled data extraction actually understands the meaning of the data being extracted? Well explaining the Knowledge Graph is a great way to show exactly what we mean by this.
The Knowledge Graph essentially crawls billions of pages every several days. Facts about different entity types are extracted. And based on a sophisticated process that gauges the reliability of these facts, these facts are included within the records of individual entities.
What are entities, you ask?
For Diffbot’s Knowledge Graph, entities are collections of records that represent organizations, people, or “things.” Knowledge Graph entities are meant to represent something out in the world (and that’s talked about on the public web) that are useful for human purposes. And so our list of entity types expands over time.
Presently, the types of entities you can gain information on include:
- AdministrativeArea
- Article
- Corporation
- Degree Entity
- Discussion
- EducationMajorEntity
- EducationalInstitution
- EmploymentCategory
- Event
- Image
- Intangible
- Landmark
- LocalBusiness
- Miscellaneous
- Organization
- Person
- Place
- Post
- Product
- Role
- Skill
- Or Video
Each of these entity types contains a collection of facts pertinent to that entity type, and judged to be the most accurate (as there are often conflicting “facts” online). Additionally, entities are connected to one another. For example, a collection of person entities will comprise a list of employees within a corporation entity. And a list of skills will be present inside of a person entity.
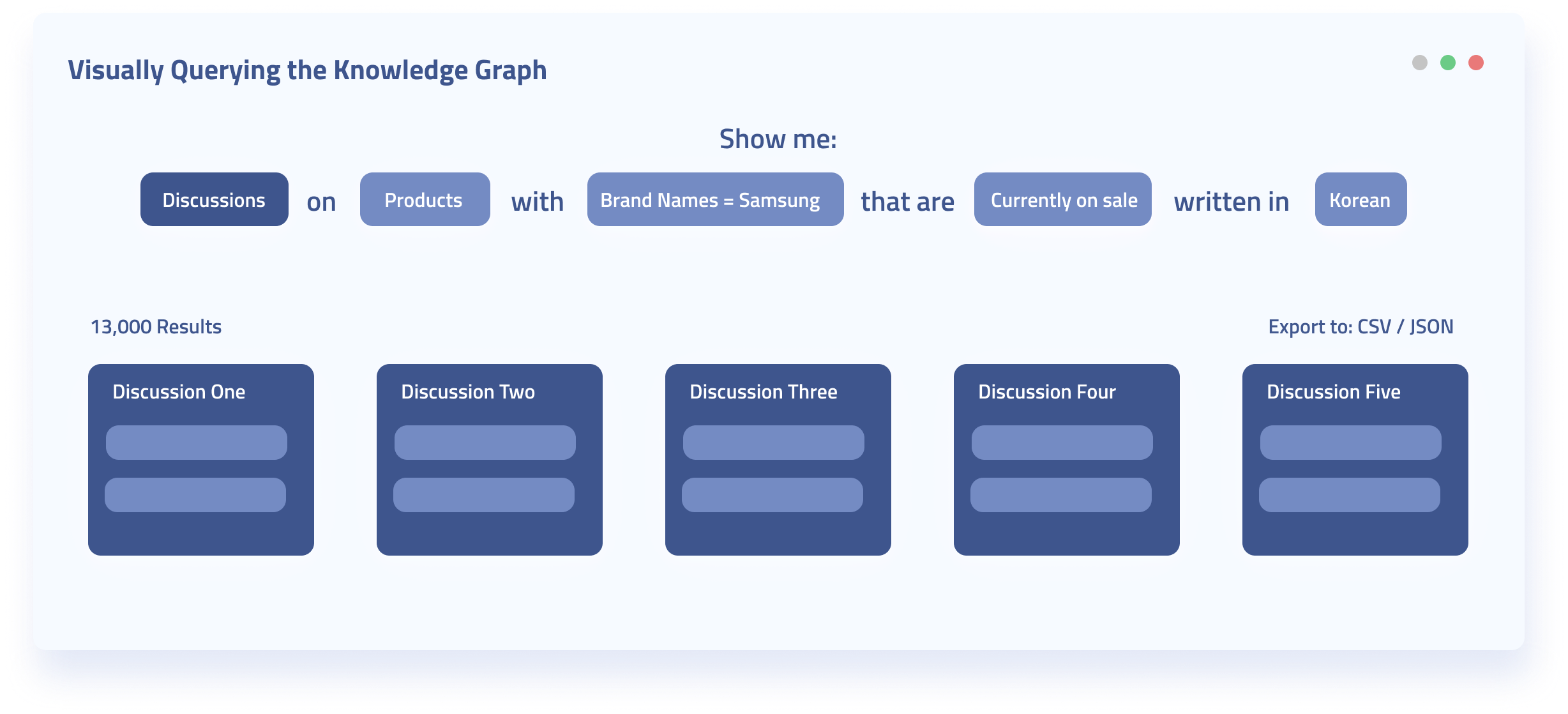
Because Knowledge Graph entities are structured to preserve the relationships between different entities, much more valuable questions can be asked of the Knowledge Graph than other web data sources.
Example questions you could ask the Knowledge Graph:
- What was the sentiment score of all articles written about a competitor product in Korean?
- How many individuals with data science skills work for Intel?
- What’s the sales price of an internationally sold product when it’s sold in India?
- And many others…
Now you may be wondering what this has to do with data extraction…
Many web data providers provide the ability to pull data from an unstructured page and structure it. In the case of the Knowledge Graph, we’ve already extracted data from virtually the entirety of the public web. The data extraction is taken care of so you can worry about what you’re going to do with your web data.
While other tools may aid you in extracting data by yourself, Diffbot’s Knowledge Graph lets you leave data extraction to the experts so that you can move on to other more central issues.
While the Knowledge Graph is at the center of Diffbot’s web data universe, we mentioned our third route to extracted data earlier in this section and we’ll cover that now. Diffbot Enhance is a data enrichment tool meant to update or flesh out data that you may already have.
Enhance runs over the underlying Knowledge Graph with a separate matching algorithm geared towards finding specific entities. Where Knowledge Graph is meant for searching across extracted data, Enhance is meant for finding specific entries and ensuring their accuracy.
Enhance comes with a range of integrations including Excel, Google Sheets, and Tableau. This allows non-technical users to quickly pull in the power of the Knowledge Graph to enrich existing data in many of the most popular productivity softwares. As with the Knowledge Graph itself, Enhance allows you to skip the data extraction phase of knowledge work and simply draw from our comprehensive already-extracted KG.
Web Data Extraction Versus Knowledge-As-A-Service
While we touched on this difference to some extent in the last section, in this section we’ll look over some of the key conceptual differences between what Diffbot and Import.io provide.
Both Import.io and Diffbot provide web data extraction tools. These are tools that can pull unstructured data from a page and transform this data in some way so that it is more usable.
Web data extraction tools commonly require you (or someone on your team) to:
- Locate the web data you need
- Determine how regularly you need your data updated
- Determine what format you want to consume the extracted data in
- Configure extraction tools (depending on how unstructured the data is)
- Wrangle, cleanse, and transform the data extracted
This process takes up more than 80% of many data teams’ time and resources.
Knowledge-As-A-Service providers like Diffbot are built on the new understanding that data aggregation, verification, and upkeep costs can quickly overrun the value of the data itself.
While Diffbot’s Automatic Extraction APIs ARE web data extraction tools, they’re structured to return results in formats similar to our Knowledge Graph or Enhance products. This allows users to skip time consuming data wrangling, cleansing, and transforming steps within the data life cycle. Even Diffbot’s most extraction-focused product is a far cry from many competing web extraction services.
Furthermore, our Automatic Extraction APIs are just part of Diffbot’s data sourcing continuum. Within many use cases, Diffbot users employ multiple web data tools, enabling the full benefits of Knowledge-As-A-Service. Namely, that Diffbot’s Knowledge Graph and Enhance products cut up to 80% of time from a typical data lifecycle.
One final note is that there is a key qualitative difference between extracted data, and semantic web data parsed into information. You can organize tabular data into useful structures. You can ask semantic data complex questions in human language.
This allows data teams and decision makers to spend more time asking impactful questions of their data, and less time simply questioning their data.
All three products (as well as Crawlbot, a related web crawling tool) are available in all tiers of Diffbot’s service plans. Interested in what our Knowledge Graph, Automatic Extraction APIs, or Enhance can do for you? Try us out with a 14-day free trial today!
Analysis of Import.io Offerings
Import.io Overview
Import.io is one of the most beginner-friendly web data extraction platforms available. For sites with semi-structured data, Import.io almost always works directly out-of-the-box. For more convoluted extraction sites, Regular Expressions and XPath can make your extractions more precise.
Among paid plans users can set their extraction on a timer, choose to only update fields that have changed, and employ a range of preset data transforms on extraction data. Additionally, Import.io offers several methods to visualize extracted data within custom dashboards.
What type of data is available?
- Text Data
- Pricing Data
- Link Data
- Image Data
Import.io Features
- A visual UI for selecting elements you want extracted from a page
- The ability to extract data on a timer
- Reports on how scheduled data extractions change over time
- The ability to visualize extracted data
- The ability to customize extractions with Regular Expressions and XPath
Import.io Use Cases
- Market Intelligence
- Pricing Data Extraction
Import.io Pricing
- $0/Month Community Tier For 1,000 pages extracted a month
- $299/Month for lowest paid tier per user
Analysis of Diffbot Offerings
Diffbot Overview
Diffbot sources Knowledge Graph™ data through web-wide crawls that are then parsed by a cutting-edge machine vision and natural language processing AI system. Data is organized into entity types that are interlinked and populated by facts. Data within Diffbot entities is semantic, meaning that data is encoded next to the “meaning” or context of that data. At a general level, Diffbot takes unstructured data from billions of sites across the web and provides this data structure within the world’s largest knowledge graph.
Diffbot also offers customizable data extraction solutions including Crawlbot as well as custom Extraction APIs.
What type of data is available?
- Organizational (firmographic) data
- Person data
- Product data
- News mention data
- Other entity data
Diffbot Features
- Access to structured entity data extracted from pages across the web (Knowledge Graph)
- Data enrichment (Enhance)
- Bulk crawler
- Custom Extraction APIs
- Excel, Google Sheets, Tableau integrations
Diffbot Use Cases
- Market Intelligence
- News Monitoring
- Ecommerce
- Machine Learning
- Web Scraping
Diffbot Pricing
- $299-$899/Month
- $299/Month Standard “Startup” Plan
Interested in how Diffbot can help your news monitoring or research use cases (among others)? Check out our recent news monitoring case study, or sign up for a free 14-day trial today!