Skip Ahead
There are only a handful of publicly available knowledge graphs. And among those, only a few provide data with enough breadth to in some way represent the entire internet, and with enough granularity to be useful.
The Global Database of Events, Language, and Tone (the GDELT Project) is one such database, and within certain use cases a strong contender with Diffbot’s Knowledge Graph. Unlike many knowledge graphs that are primarily of academic interest, Diffbot and the GDELT Project both extract data at the scale of the web, process it and synthesize this data into enormous (and usable) graphs.
In this guide we’ll compare and contrast these two heavyweights of web extraction, processing, and knowledge graph creation.
In particular, we’ll look at:
- GDELT’s History
- GDELT Data Products
- GDELT Use Cases
- Diffbot’s Data Products
- Diffbot’s Use Cases
- GDELT Versus Diffbot Data Structures
- Analysis of GDELT Offerings
- Analysis of Diffbot Offerings
If you’re a researcher looking for access to the world’s largest database, be sure to check out our 14-day free trial or to contact sales for opportunities for academic partnerships.
GDELT’s History
While web data providers do pivot and adapt to the times, the history of a web extraction and graphing organization can provide details on what their mission and primary focus are.
The Global Database of Events, Language, and Tone (GDELT) was co-founded by Kalev H. Leetaru of Yahoo! and Georgetown University. Leetaru had pioneered some of the earliest web mining technologies at the National Center for Supercomputing Applications (the home of the modern web). GDELT was a continuation of these inquiries that coalesced around a 2011 conference paper by co-creator Philip Schrodt.
Schrodt, as a political scientist, was interested in political and governance applications of web mining, as evidenced in his outlining paper for GDELT titled “Automated Production of High-Volume, Near-Real-Time Political Event Data.” Over the last decade, GDELT has grown into one of the largest databases of just this: a catalog of political events, who the actors of these events are, and how these events are perceived by the general public.
Today GDELT is supported by Google Jigsaw, a unit within Google responsible for threat emergence and detection.
GDELT Data Products

GDELT’s primary data offering is that of a several petabyte-sized database with entries on events, actors in events, news mentions of events, and sentiment analysis. A range of interrelated datasets can be accessed which total trillions of data points.
The three primary streams supporting these data sets include:
- A stream codifying physical activities of over 300 types worldwide (for example, a conference, or a sporting event)
- A stream codifying people, places, and organizations as well as themes and emotions for parties affected by events
- And a stream codifying visual imagery from news coverage
Together these streams cover worldwide news from print and web-based sources in nearly real time, with streams updating every 15 minutes around the clock. Supplementary sources that are also encoded include over 215 years of digitized books, 21 billion words of academic literature, and many publicly available closed circuit video feeds.
The data products that are provided from this dataset include:
- The GDELT Event Database categorizes physical activities occurring around the world
- GDELT Global Knowledge Graph provides the ability to see how events affect or are affected by organizations and people
- GDELT Visual Global Knowledge Graph is a random sampling of millions of images from the news of a nation presented in one day increments
- GDELT GKG Special Collections are sources of particular interest processed through GDELTs other tools. These include digitized books and academic literature
GDELT Use Cases
GDELT has primarily gained notoriety within research and governance settings, though commercial implementation of their databases is certainly possible. Some of the most well-known use cases for GDELTs products include:
- Disaster Monitoring and Reporting
- Event Monitoring
- Risk Assessment
- Influencer Analysis
- Social Science Research
- News Monitoring
- Sentiment Analysis
Within research settings, GDELT is often used to gain geographic information related to news or academic literature mentions. In governance settings, GDELT is often used to gauge sentiment across broad geographic areas. For example, one of the most publicly known uses of GDELT was Foreign Policy Magazine’s mapping of media outrage at the passing of the Affordable Care Act plotted geographically.
Among event and sentiment-centered databases, it is noted that there is only one comparably sized database known as the U.S. Department of Defense’s Worldwide Integrated Crisis Early Warning System. This database is not publicly available, however. Diffbot’s Knowledge Graph can be used for similar sentiment-centered queries on billions of entities. With key differences being that Diffbot does not source data from non web-based sources, GDELTs sentiment data goes back to 1979, and Diffbot provides a much wider range of fact types.
Diffbot’s Data Products

Diffbot’s data products center around the process of turning unstructured data from across the web into structured, contextual data.
Data parsed through Diffbot’s cutting-edge machine vision and natural language processing systems is primarily available through four routes:
- Diffbot’s Knowledge Graph extracts data from across the web every 3-5 days. Unstructured data is parsed and fused into connected entities such as organizations, people, articles, products, and more.
- Diffbot’s Automatic Extraction APIs can be pointed to a precise location you want data from. Data is then parsed into entities similarly to the Knowledge Graph including organizations, people, articles, products, discussions, and more. Automatic extraction APIs are best if you want data that is updated more regularly than the Knowledge Graph, or if you know precisely what data you want to extract
- Diffbot’s Enhance looks over Knowledge Graph data with a slightly different matching algorithm. Enhance is primarily used for data enrichment. When you have some information on an entity and you would like to enrich this data, Enhance is your best bet. Enhance is available with multiple integrations include Excel and Google Sheets.
- Diffbot’s Crawlbot extracts structured data from entire sites at once (or on a schedule). This data can then be parsed by an Automatic API (or wrangled with tools of your choosing). Crawlbot is best used if you want to extract data from a domain with many sub pages or if you want to extract on a schedule.
While more technical users can use custom data extraction through APIs, Knowledge Graph and Enhance offer access to the world’s largest Knowledge Graph composed of over 2 trillion facts and over 10 billion Knowledge Graph entities.
Diffbot Use Cases
Diffbot’s web data is semantic, meaning that extracted data is encoded alongside what the data means. This enables Diffbot’s AI systems to infer facts about different entity types. It also allows Diffbot’s AI systems to encode relationships between different entities. For example, a product entity may contain facts about it’s pricing, availability, and reviews. This product may be linked to a larger brand, or company entity, which would be composed of different types of facts.
The breadth, structure, and interlinked nature of Diffbot’s data supports a huge range of use cases. And allows for \unstructured web data — once processed — to answer complex searches.
Some example searches that Diffbot’s Knowledge Graph can answer include:
- What companies in San Francisco in Finance employ more than 20 data scientists?
- What is the sentiment of articles written about an organization by week?
- What is the breakdown of skills by organizations in a given industry?
- And countless other examples…
Results are explorable down to individual and interlinked profiles of people, organizations, products, and more.
The major categories of Diffbot’s use cases include:
- Market Intelligence
- News Monitoring
- Ecommerce
- Machine Learning
- And Web Scraping
Within each of these use cases studies have suggested that data teams can spend up to 80% of their time and resources just sourcing, cleaning, and verifying the quality of data. Diffbot helps to minimize this burden through a range of Knowledge-As-A-Service solutions. Additionally, Diffbot’s data is sourced from a wider range of sources than potentially any other commercially-available data provider.
GDELT Versus Diffbot Data Structures
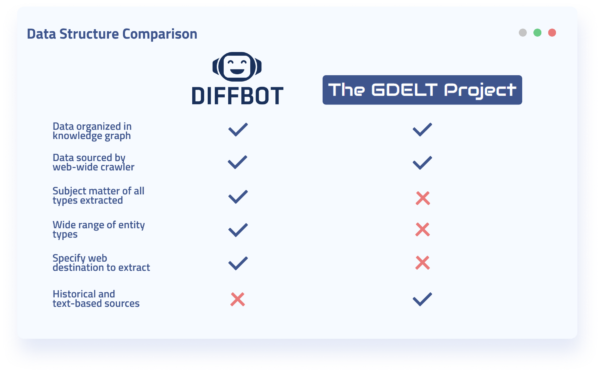
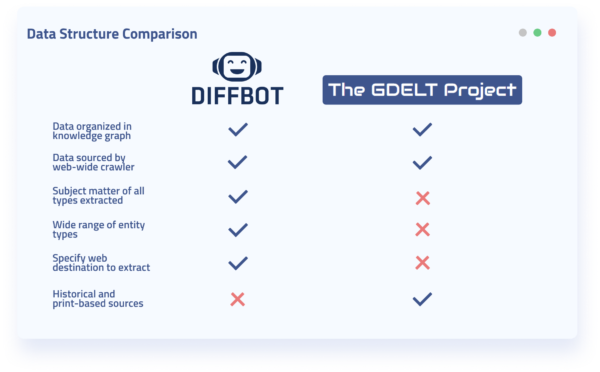
From a high-level perspective, GDELT and Diffbot organize their data similarly. Both GDELT and Diffbot employ knowledge graphs for the organization of entities.
Graphs are an informatics concept and organizational schemas that focuses on preserving the relationships between entities. The focus on relationships is greatly distinguishable from how “traditional” databases work, which are built to preserve the integrity of data for individual database entries. Even relational databases, built to include information on the relationships between database entries are highly inefficient when dealing with large relational datasets when compared to Knowledge Graphs.
The “knowledge” portion of “knowledge graphs” relate to the semantic nature of the data. This “smart data” is encoded to preserve the meaning of the data next to the data itself. This means new facts can be inferred programmatically. This also means that searches can traverse different entity types, exposing valuable insights into complex relationships.
From a high-level perspective, GDELT and Diffbot also source their data similarly. Both employ what could be termed “web-wide crawlers.” Some differences between Diffbot and GDELT data sources include:
- GDELT includes some print-based news data sources
- GDELT offers some historical data going back to 1979
- GDELT looks for events, sentiment, and actors in events
- Diffbot crawls the entirety of the public web (not just news sources)
- Diffbot can be pointed at any domain for rules-free crawling
- Diffbot is optimized for many different data types (organizations, people, articles, products, discussions, and more)
While there are definite similarities between GDELT and Diffbot data offerings, one of the largest differences is the subject matter of data extracted from across the web.
Diffbot’s AI-enabled Knowledge Graph and Automatic Extraction APIs parse facts from across the web into an ever evolving set of entity types. Through machine learning, Diffbot’s entities are optimized to contain information that humans find valuable. For example, a fact about a fundraising round may be pertinent to an organization, but likely not to an article.
What this means is that entities in Diffbot’s Knowledge Graph are structured to mirror entities in the real world.
A present list of Diffbot’s Knowledge Graph entity types includes:
- AdministrativeArea
- Article
- Corporation
- Degree Entity
- Discussion
- EducationMajorEntity
- EducationalInstitution
- EmploymentCategory
- Event
- Image
- Intangible
- Landmark
- LocalBusiness
- Miscellaneous
- Organization
- Person
- Place
- Post
- Product
- Role
- Skill
- Or Video
On the other hand, GDELT is based on only a subset of extractable facts found in data sources. In particular, GDELT is interested in events — and particularly in events of political importance. Entity types that GDELT tracks and deems important for supporting this mission include:
- Events
- People
- Sentiment
This doesn’t mean that there isn’t any overlap in coverage between the two knowledge graphs. You could search the Diffbot Knowledge Graph to gain sentiment analysis scores within news articles about a given person or event. But that is not the single focus point. You could similarly search for people entities given applicable parameters in both knowledge graphs. But the data returned about these people would be substantially different.
Analysis of GDELT Offerings
GDELT Overview
GDELT, short for The Global Database of Events, Language, and Tone, is the world’s largest event-centered database. Well-used in research and governance applications, GDELT provides a near real-time database of actors (people or organizations), events, and sentiment towards these actions. GDELT data is sourced from both print and selected web-based news sources, and
What Type of Data is Available?
- Event data
- Sentiment analysis data about events
- Knowledge graph of entities involved in events (people, organizations, news mentions)
- News data
- Academic literature data
GDELT Features
- GDELT Analysis Service Platform For Analysis and Visualization of Data
- Google BigQuery Access to Data
- Downloads for All Data or by Time Frame
- News Image Aggregation Visualization
- Precise geographic data for events and those involved
GDELT Use Cases
- Disaster Monitoring and Reporting
- Event Monitoring
- Risk Assessment
- Influencer Analysis
- Social Science Research
- News Monitoring
- Sentiment Analysis
GDELT Pricing
GDELT as well as the GDELT analysis service are free. Individuals or organizations may even repurpose data for use in their own products as long as they cite GDELT with a link.
Analysis of Diffbot Offerings
Diffbot Overview
Diffbot sources Knowledge Graph™ data through web-wide crawls that are then parsed by a cutting-edge machine vision and natural language processing AI system. Data is organized into entity types that are interlinked and populated by facts. Data within Diffbot entities is semantic, meaning that data is encoded next to the “meaning” or context of that data. At a general level, Diffbot takes unstructured data from billions of sites across the web and provides this data structure within the world’s largest knowledge graph.
Diffbot also offers customizable data extraction solutions including Crawlbot as well as custom Extraction APIs.
What type of data is available?
- Organizational (firmographic) data
- Person data
- Product data
- News mention data
- Other entity data
Diffbot Features
- Access to structured entity data extracted from pages across the web (Knowledge Graph)
- Data enrichment (Enhance)
- Bulk crawler
- Custom Extraction APIs
- Excel, Google Sheets, Tableau integrations
Diffbot Use Cases
- Market Intelligence
- News Monitoring
- Ecommerce
- Machine Learning
- Web Scraping
Diffbot Pricing
- $299-$899/Month
- $299/Month Standard “Startup” Plan
Interested in how Diffbot can help your news monitoring or research use cases (among others)? Check out our recent news monitoring case study, or sign up for a free 14-day trial today!
You must be logged in to post a comment.