Skip Ahead
Generation of leads is the single largest challenge for up to 85% of B2B marketers.
Simultaneously, marketing and sales dashboards are filled with ever more data. There are more ways to get in front of a potential lead than ever before. And nearly every org of interest has a digital footprint.
So what’s the deal? 🤔
Firmographic, demographic, technographic (components of quality market segmentation) data are spread across the web. And even once they’re pulled into our workflows they’re often siloed, still only semi-structured, or otherwise disconnected. Data brokers provide data that gets stale more quickly than quality curated web sources.
But the fact persists, all the lead generation data you typically need is spread across the public web.
You just needs someone (or something 🤖) to find, read, and structure this data.
How Diffbot’s Knowledge Graph “Finds, Reads, and Structures” the Public Web
The economics of manually structuring data haven’t changed in a long time. It may be quicker to find a fact from the internet then a library, but the unit price of information accumulated by human action doesn’t lower past a certain point.
This is limiting when we’re looking for data spread across the entire web.
In fact, quality lead generation intel often surfaces in many public web locations that aren’t covered by basic firmographic or demographic data providers. Leads come from insights that historically occur during human research and interactions.
Data often integrated into deciding whether a lead is qualified includes:
- Press releases
- Hiring trends
- Review site data
- Job Postings
- Case Studies
- Rebrandings
- Mergers and Acquisitions
- Patent Filings
- Technographic profiles from TOS’s
- Product Inventory
- News Coverage
- And more…
But no marketing or sales team can keep up with all of this disparate data on even a single industry.
That’s where Diffbot’s Knowledge Graph comes into play. Diffbot is one of three North American entities to crawl the entire web. We’ve spent close to a decade honing out AI, machine vision, and NLP-enabled scrapers. These scrapers don’t rely on rules for what to extract. So they can extract data from pages they don’t know the structure of in advance.
Natural language processing then pulls this data into facts about entities and relationships between entities. Presently the Knowledge Graph provides robust entity data offerings on:
- Organizational entities
- Person Entities
- Article Entities
- Product Entities
- Discussion Entities
- And more…
So what does this have to do with lead generation?
A few characteristics of our KG make our structured web data particularly suitable for lead gen.
- The ability to search across facets (e.g. “show me all organizations in a given industry with a given employee count”)
- The ability to enrich stale, incomplete, or inaccurate org or person data you may have (our Enhance product)
- The fact that we source data from across the web, from all the locations that may provide valuable signals (a feat that no manual lead gen effort could accomplish)
- The fact that structured data is easy to integrate into your own workflows or incorporate with existing data stores
These are all high-level reasons why the Knowledge Graph is a great source for quality lead generation data. But let’s jump into some more concrete examples.
Techniques For Lead Generation In the KG
At Diffbot we’ve used our web scrapers and Knowledge Graph internally for marketing and sales efforts for as long as they’ve been around. We’ve also had myriad customers share their uses for the KG related to lead gen. Below are some of our favorites:
Market segmentation and Research
Organizational and person data are some of our most robust datasets within the Knowledge Graph. At the date of this article’s writing the KG holds over 240M organizations and 720M person entities.
Rather than searching for human curated lists or written content about a market of interest, the KG lets you filter through organizations with a diverse set of selectors.
Organization entity fact types include:
- Industries
- CEO
- Board Members
- Social Account URIs
- Founders
- Investments
- Brands
- Market Caps
- Employment Counts
- Locations
- Revenue
- Stock
- And many more…
While Person entity fact types include:
- Articles
- Colleagues
- Social Account URIs
- Employers (and employment history)
- Skills
- Educations
- Connected Industries
- And Many More
As you may begin to imagine, the ability to knowledge search for a unique list of organizations or people who qualify as leads is immensely valuable. Any sizable set of results would take a noteworthy amount of time to compile manually. And that’s assuming search engines have indexed each given page or facts are available from a data broker of some sort.
Queries within the Knowledge Graph are performed with Diffbot Query Language. You can also perform most basic to intermediate queries with a visual query editor that’s easy to get started with right away.
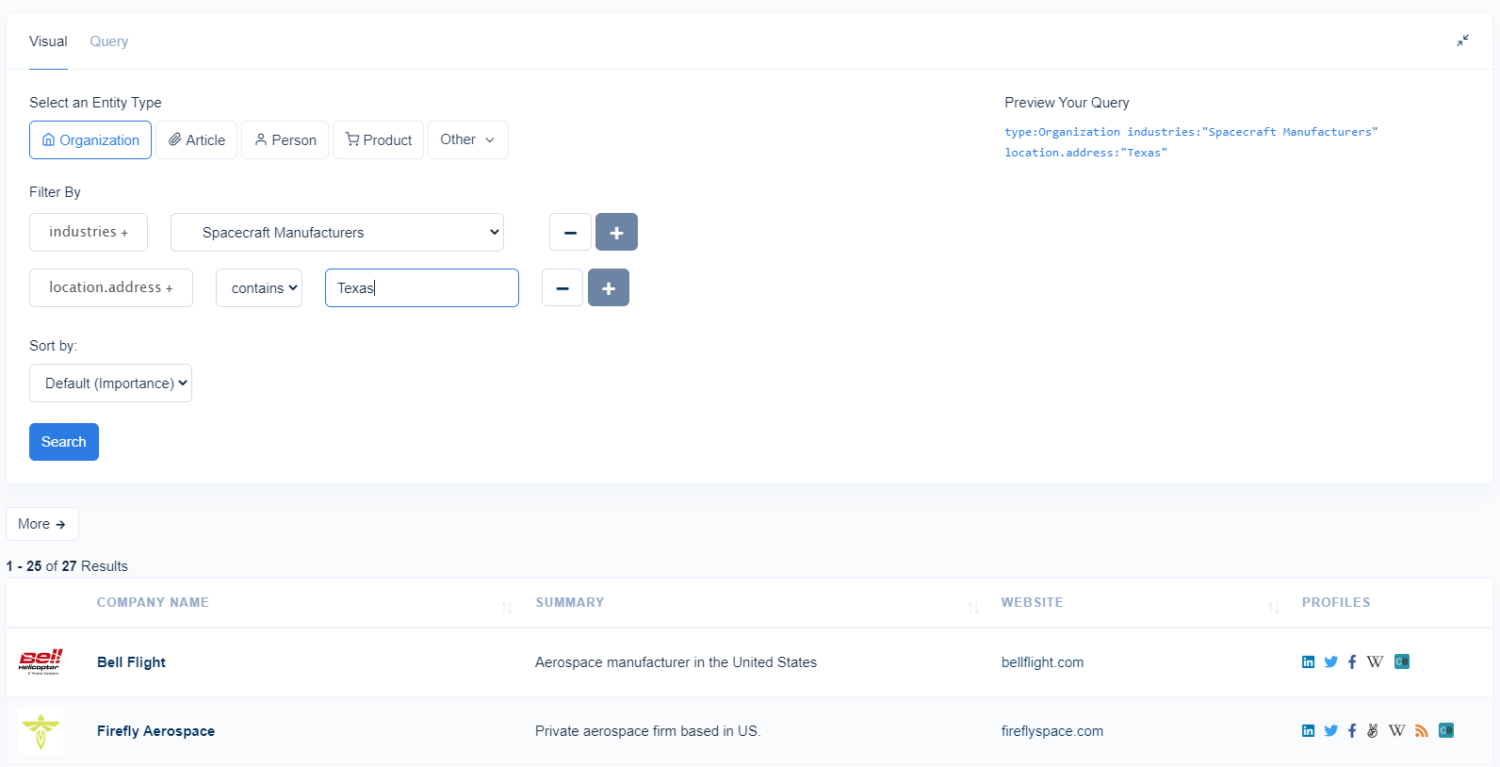
Within each set of results, each entity is populated with additional information. You can download the entirety of the data from your results in JSON, CSV, or via API calls. Additionally, org and person data is available within your workflow through a number of our integrations.
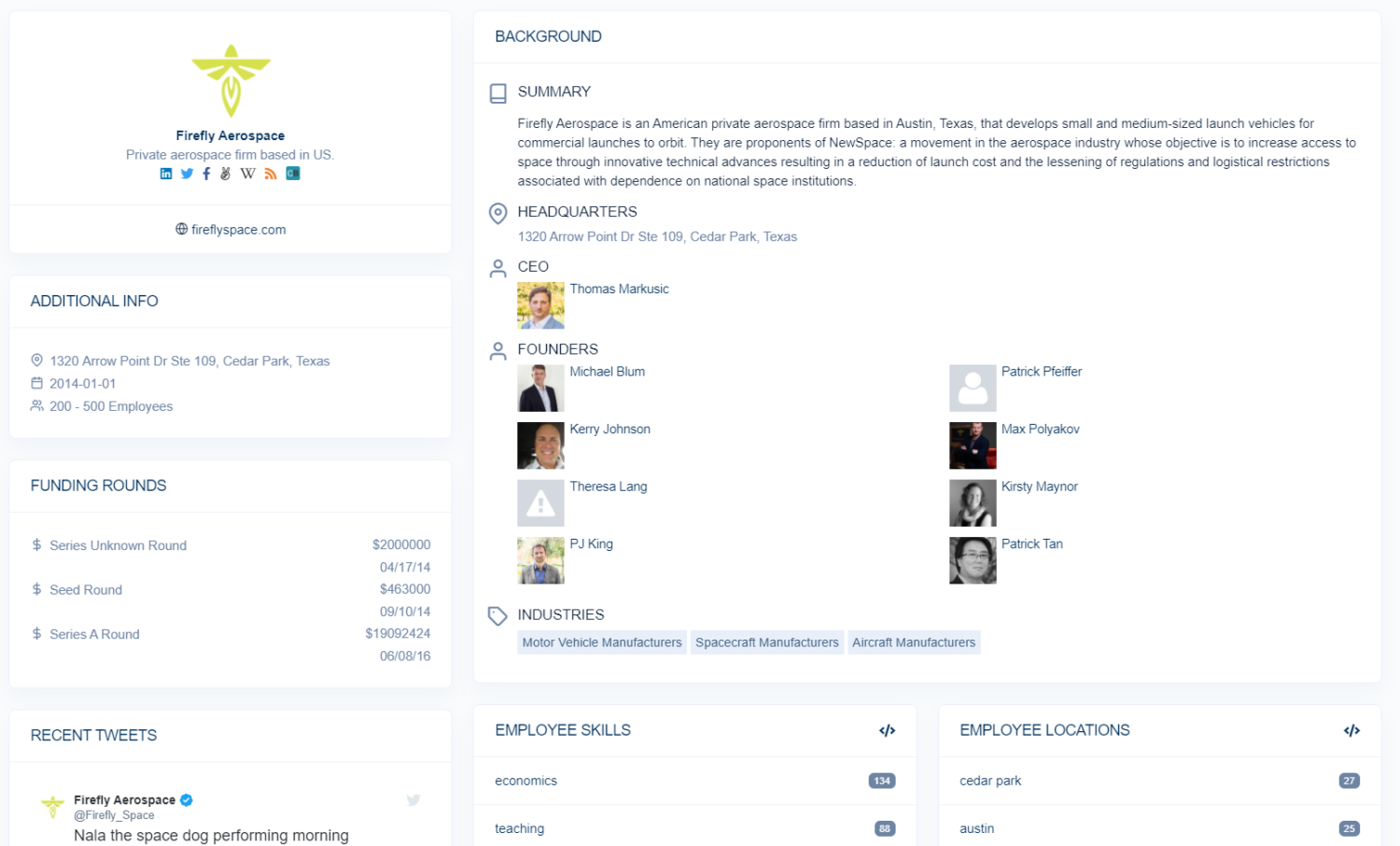
While key individuals at organizations such as CEO’s, board members, and founders are directly embedded in organizational entities, for a list of all employees of an organization you’ll need to approach your data through person entities.
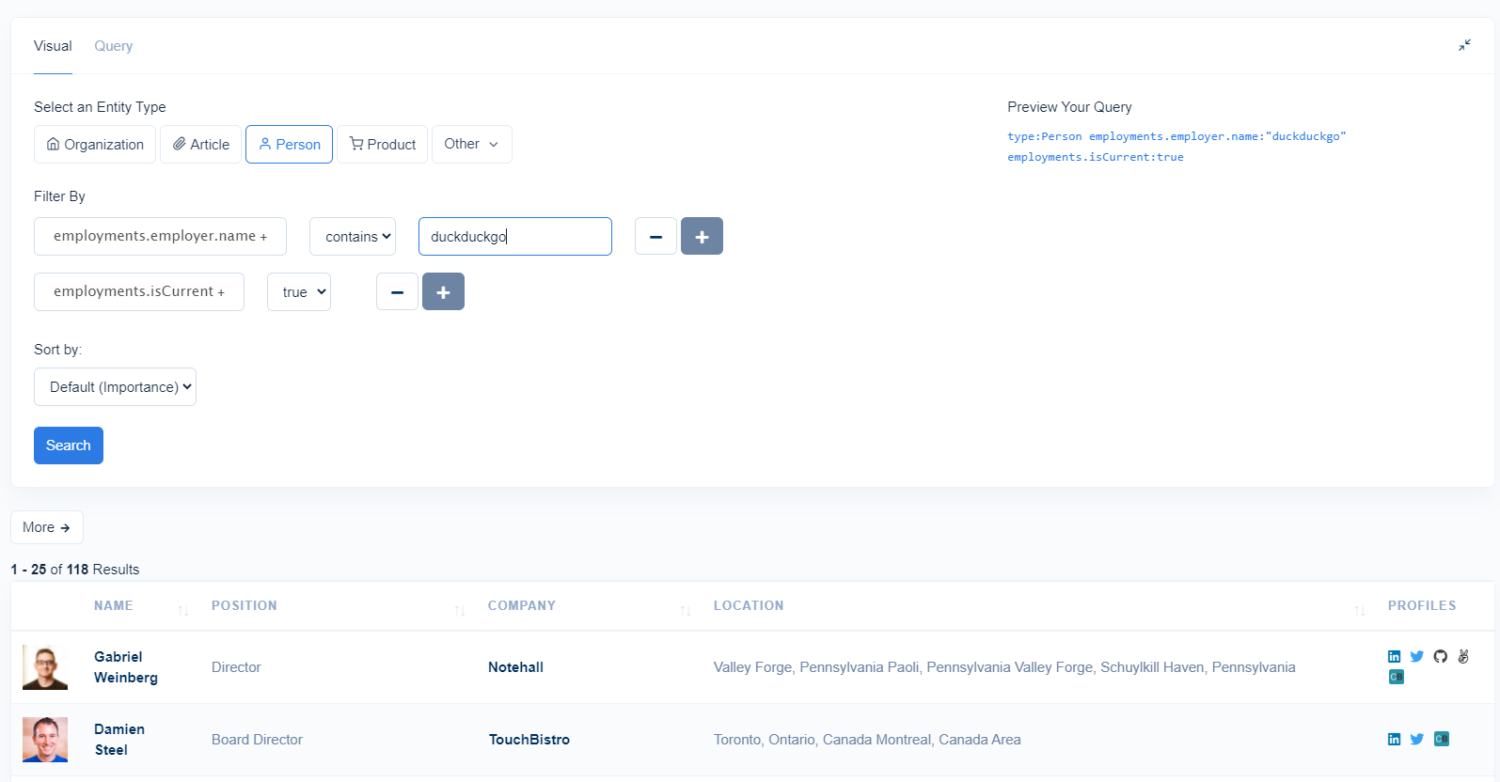
By using the employer and isCurrent selectors, you can find a list of individuals who are publicly listed online as working for a given organization. You can then filter by all of the fields associated with person entities such as articles published, position, education, location, skills, and more.
Lead Scoring and Routing
You can widen your outreach net. But unless leads are qualified, you’ll likely spend more resources for diminishing returns. One way to ensure you’re aimed at the right target to begin with is to perform lead scoring. You can augment your CRM data (or wherever you hold lead data) with Knowledge Graph data to filter out and prioritize which leads should take up more or less time.
If you have your ICP finely honed, you can filter out organizations that don’t fit from a firmographic perspective. If you’re seeking to reach out to individuals with a certain skill, job title, or seniority level, you can also filter through person entities.
When building off of an existing list of leads, Diffbot’s Enhance product can be used to traverse the KG using a different matching algorithm. This matching algorithm focuses on surfacing a single match given a set of potentially incomplete, incorrect, or partially correct data points. AKA, Enhance fixes and augments your CRM.
When Enhance matches an organization or person that you know some details about (say, a potential lead), what is returned are all facts attached to this individual within the Knowledge Graph. That means you can take a list of individual leads and supplement them with industry codes, employee counts, or skills and job titles (for people).
Enhance can be implemented via API, our dashboard (simply upload a CSV with your lead data) or through integrations like Excel.
Filtering leads can occur through logical operations (“all organizations who are not aerospace or vehicle manufactures). Additionally, you can create your own lead scoring rubric (“10 points if this individual is a data team leader, 10 points if they’re based in California, 10 points if their org uses a given technology”).
Finally, lead routing is a cinch with Diffbot’s firmographic and demographic data. Fields like employee count, industry, or job title can be used to forward a particular lead to a member of your sales team.
Personalization of Messaging
Equally as important as identifying qualified leads is the process of lead nurturing and outreach. Today, content and interactions in many B2B settings are expected to be highly tailored and provide immediate value to leads.
Diffbot offers a variety of public web data-enabled tools to help you personalize your messaging. From the ability to surface social accounts and articles written by organizations and people, to the ability to parse given press coverage with natural language processing to surface conversation starters programmatically.
In the below video we work through utilizing our Enhance Zapier integration to surface KG data about individuals who have selected a time for a meeting in a calendar. This is but one of many ways to gain intelligence useful for future outreach to key individuals with Diffbot’s web data.
News Monitoring and Qualifying Event Tracking
Finally, as organizations and individuals make moves, timing can play a crucial role in whether you snag a sale or not. The Knowledge Graph offers a news index 50x the size of Google News, and the ability to filter by a rich set of fields and fact types (similarly to org and person entities) can help you to build out a lead-centered news monitoring dashboard.
Fields you can filter article entities within the KG by include:
- Sentiment
- Topical tags
- Publisher Country
- Author
- Date Published
- Quotes
- Speakers
- Discussions
- And more…
Additionally, our Natural Language API can derive even more useful structured data fields from news or social media text. The ability to derive sentiment for entities mentioned in text is incredibly valuable for pinpointing potential pain points for leads. Additionally, the ability to track key hires, mergers, acquisitions, or expansions into new markets can trigger optimal outreach times.
Finally, if you have a list of specific niche domains that you want to monitor by the hour or minute, the use of Crawlbot with one of our Automatic Extraction APIs can provide an almost-live feed of industry or organization news.
In the below video we show many of these news monitoring data sources combined in a custom solution for a given industry and competitor set.
Conclusion
At the end of the day sealing deals comes down to human judgment, communication, and the quality of your product. But the process of generating quality leads shouldn’t be the point at which your sales engine breaks down. Nearly every organization and person has a digital footprint on the public web. The issue is that these lead generation-enabling facts are spread across the internet. That’s where Diffbot comes in, by providing structured web data from across the web and inserting it directly within your knowledge workflows! 👊 🤖
You must be logged in to post a comment.