
As opposed to data as a service or information as a service, knowledge as a service provides data and context in the form of knowledge-based products. Context encoded alongside data is a central notion of the semantic web and crucial for intelligent applications. Context is useful as it can help end users and intelligent applications to deal with what information “means.”
Where historical indexes of information (such as search engines or libraries) have relied on index or string matching (the matching of a set of characters or words), information and context allows for a much richer ability to organize and filter through information at scale.
In surveys of knowledge as a service providers, two main trends stand out. Some providers rely on human curators or subject-matter experts to layer context on a set of information. These providers are often niche providers dealing in relatively smaller collections of information. One example of this form of knowledge as a service provider could be a natural resource prospecting firm. Alongside environmental signals, years of experience in the field may enable the ability to “tag” data points as particularly noteworthy, or the ability to pull out patterns other interpreters of the data may not see.
A second set of knowledge as a service providers add context to information programmatically, notably with artificial intelligence, natural language processing, and machine vision. An example of this second set of knowledge as a service providers include search engines equipped to provide semantic results, firms providing natural language processing services, and creators of knowledge graphs.
Characteristics of Knowledge As A Service
Knowledge has historically been an elusive concept. But in practice, knowledge as a service providers tend to offer services with some collection of the following characteristics. The main distinguisher between these clusters is often what information is being transformed into knowledge, and whether this is a human-enabled or programmatically-generated knowledge as a service product.
- Information + context enables knowledge directly at your fingertips, when you need it. In this case, knowledge as a service providers help to enhance your knowledge workflows.
- Processing of large amounts of previously unstructured data in a way that provides context. In this case, a portion of the product involves taking data that is unusable at any large volume and rendering it meaningful.
- Expert systems that in some way attach human judgement to a data product. This case is commonly seen in consulting settings or niche data providers.
- Exposure to tacit knowledge (that is, non-explicit knowledge that often must be taught first hand). This is the most remote knowledge as a service type from programmatic knowledge as a service.
Knowledge Graphs as Knowledge As A Service
Knowledge graphs typify machine-enabled knowledge as a service. They take an underlying information source and place each node of information into a matrix of relationships. This provides context. Additionally, the structure of different entity types — as described by an ontology — allows for different types of objects to be represented in different ways.
Within Diffbot’s Knowledge Graph, an article entity may contain fields such as author, sentiment, publisher, topical tags, a date, and so forth. Meanwhile, an organization entity may contain facts such as funding rounds, employees, locations, subsidiaries, and news mentions. Additionally, different entity types may be linked. For example, a person may work for an organization. Or an article may contain a person as a speaker.
You can find a basic overview of Diffbot’s Knowledge Graph entity types in the video below or our Knowledge Graph ontology docs page.
Natural Language Processing As Knowledge As A Service
Natural Language Processing is a second common component of machine-aided knowledge as a service. A majority of information held by organizations today is in the form of unstructured data. At this scale, human interpreters simply can’t keep up. Natural language processing allows for the programmatic parsing of unstructured documents to pull out information (and at best, context as well).
Diffbot’s Natural Language API is built to turn natural language corpora of your choosing into the raw materials needed for a knowledge graph. Namely, our NL API pulls out:
- Entities
- Relationships between entities
- Facts
- Topic Categories
- Sentiment for entities
- Data provenance for all of the above
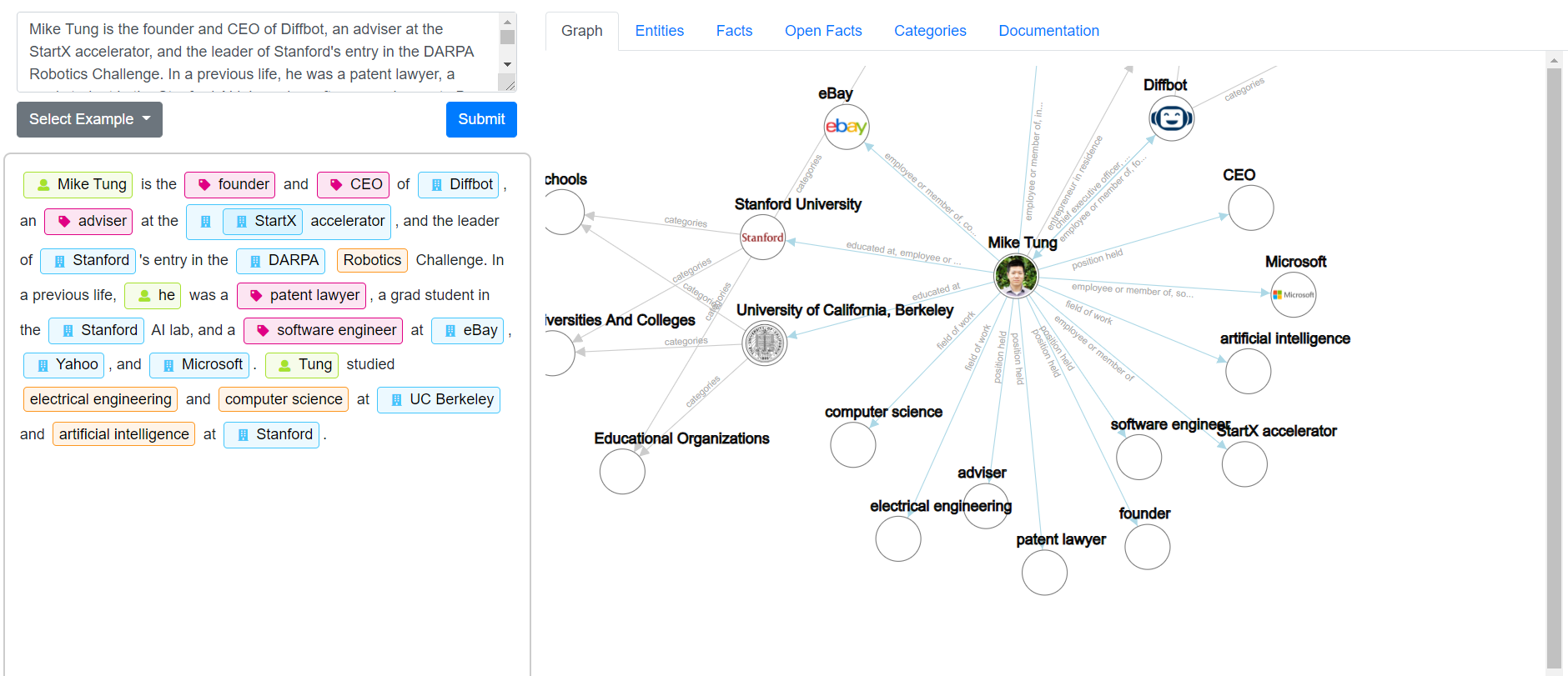
Try out our interactive NL API demo (pictured above)
For NLP to provide knowledge that is important to your workflows, it’s important that NLP be able to understand the types of entities you find valuable. To this end, Diffbot’s NL API allows for the creation of custom entity types. This means you can use a benchmark-topping NLP tool in a range of niches and industries.
Web Data Extraction As Knowledge As A Service
Arguably the public internet is the largest source of information in the world. But information online is often not structured in a format suitable for programmatic parsing or deriving insight into. This is where web data extraction can come into play.
The public web is the underlying source of Diffbot’s Knowledge Graph, which exemplifies one route for turning unstructured data into information and context (knowledge).
For teams that need specific portions of the web structured with greater frequency, or in search of custom values, web data extraction can provide a more direct and impactful data source.
Diffbot’s Crawlbot used in tandem with our Automatic Extraction APIs allow you to quickly and repeatedly crawl all common page types and derive insight from previously unstructured data.
Using machine vision and natural language processing our web data extraction suite can turn public websites into contextual data feeds for news monitoring, market intelligence, ecommerce uses, or machine learning training data.
You must be logged in to post a comment.