Automation Bias is a well-studied phenomenon in social psychology that says humans have a tendency to overly trust the decisions of automated systems. This effect was on full display during last month’s Bing Chat launch keynote and Google Bard launch. As many sharp-eyed bloggers pointed out, both demos were riddled with examples of the LLM producing inaccurate and “hallucinated” facts. Everyone, including Bing in their keynote, recognizes that AI makes mistakes, but what was surprising here is that AI was so good at getting past all of the human reviewers–all of the engineers, product managers, marketers, PR folks, and execs that must have reviewed these examples for a high profile launch event that Satya Nadella described as the “third wave of the web”.
Factual accuracy is not part of the objective function that Large Language Models are designed and optimized on. Rather, they are trained on their ability to “blur” the web into a more abstract representation, which forms the basis of their remarkable skill in all manner of creative and artistic generation. That an LLM is able to generate any true statements at all is merely the coincidence of that statement appearing enough times in the training set that it becomes retained, not by explicit design.
It just so happens that there is a data structure that has been specifically designed to store facts at web-scale losslessly and with provenance: Knowledge Graphs. By guiding the generation of language with the “rails” of a Knowledge Graph, we can create hybrid systems that are provably accurate with trusted data provenance, while leveraging the LLM’s strong abilities in transforming text.
To see this, let’s go through some of the examples demoed in the Bing Chat keynote and see how they could have been improved with access to a Knowledge Graph.
Let’s Shop for TVs using Bing
In this example, Yusuf Medhi, Chief Consumer Marketing Officer for Microsoft, is demoing the new Bing’s ability to do interactive refinement of search results through dialogue. He asks Bing Chat for the query “top selling 65-inch TVs”.

Looks like a pretty decent response. While it’s difficult to fact-check Bing’s claim that these are the “top selling 65-inch TVs in 2023″ without access to private sales data, these ten results are at least TVs (more specifically TVs product lines/series) that have 65” models. For the sake of discussion, let’s give Bing the benefit of the doubt, and assume these are correct:
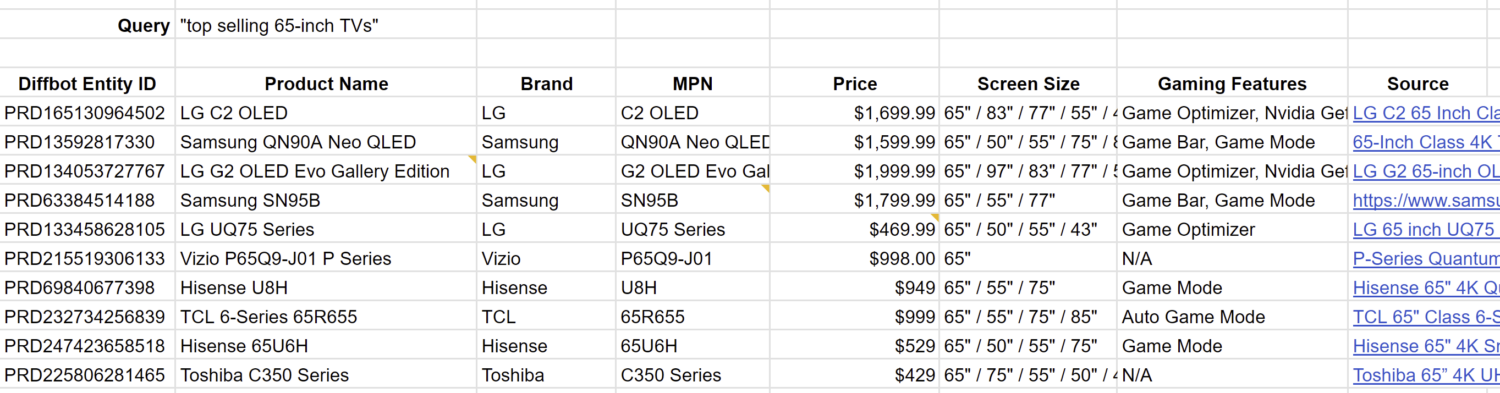
Next, Yusuf asks Bing “which of these is best for gaming?”
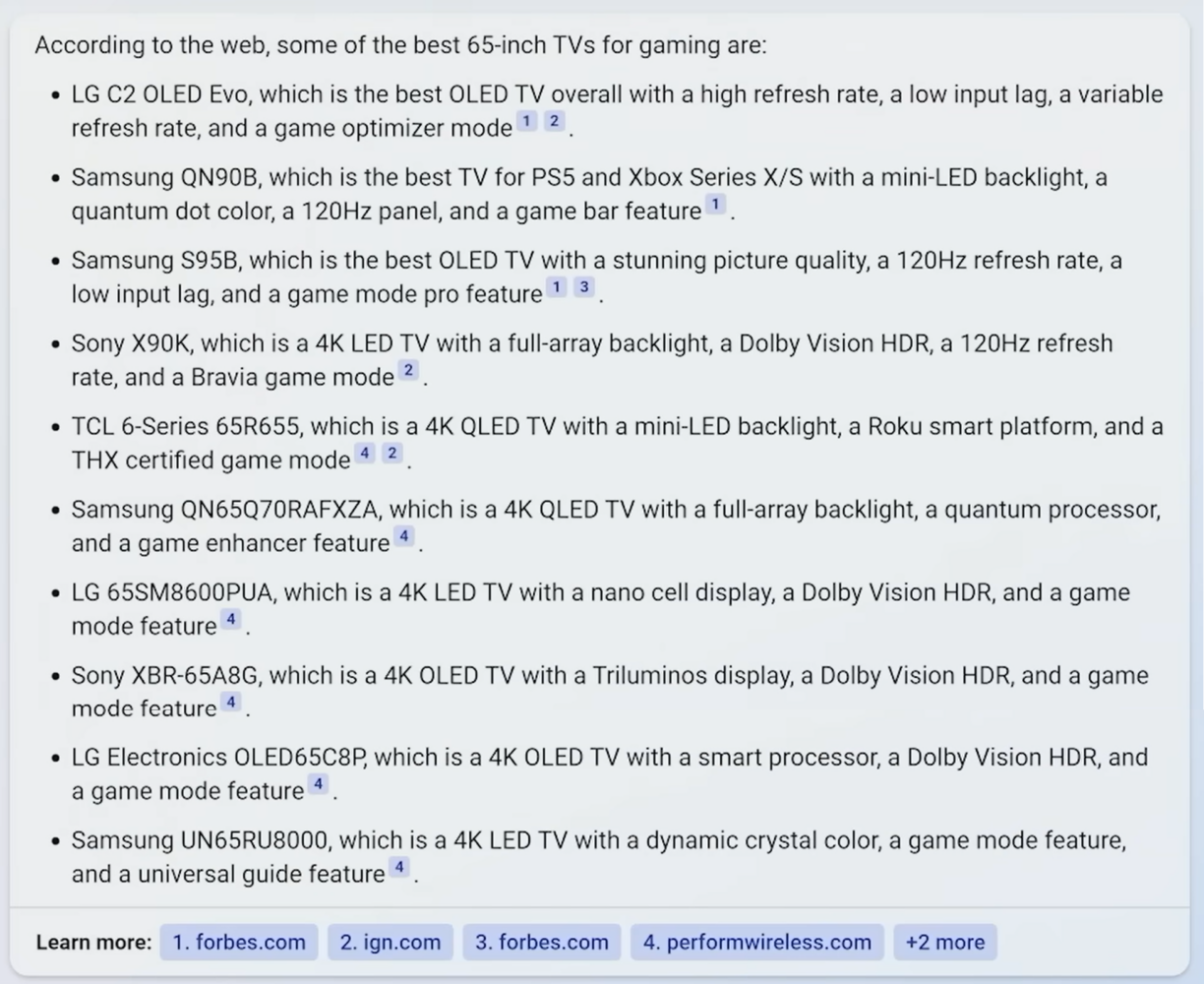
Seems pretty great right? From a quick visual scan, you can see the token “game” sprinkled liberally throughout the response. But look more closely. These responses are not at all a subset of “these” 65-inch TVs from the previous response! In fact, out of these 10 recommendations, only 3 of these are from the previous list. 7 have been swapped out:
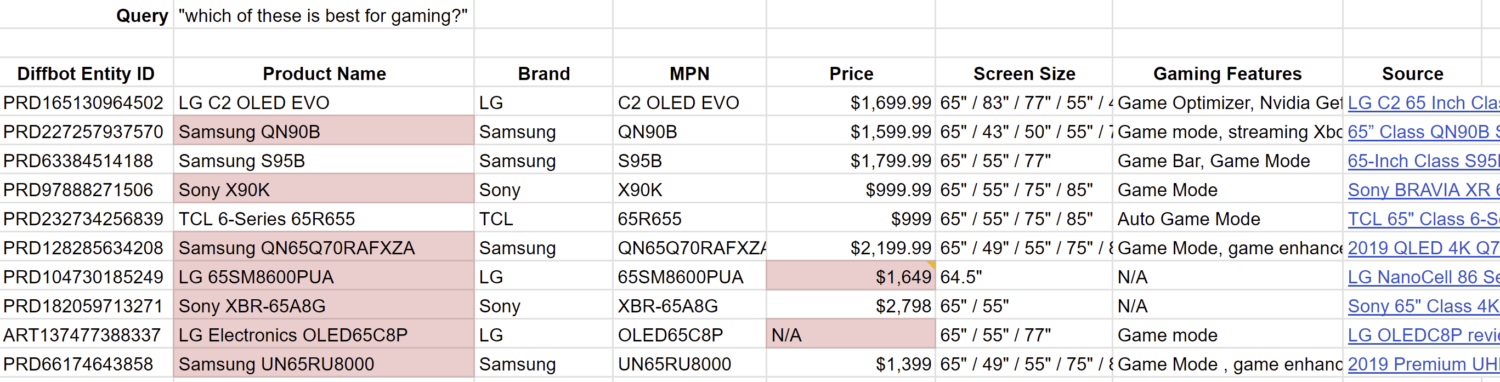
This is where the demo of query refinement starts to break down. As you start to add more conditions to your query, the likelihood that someone has created a piece of content on the web that answers the specific question at the intersection of those conditions becomes exceedingly rare. I.e, the probability of a blog post existing for “best selling 65-inch TVs” is greater than the probability someone has created a blog post for the “best selling 65-inch TVs for gaming.
Notice that now, Bing is starting to return individual product model numbers instead of product lines or series. The LLM is definitely picking up on the input token “gaming” and blending in product numbers it has seen in gaming related content, but two of the recommendations, the “LG 65SM8600PUA” and “LG OLED65C8P”, have been discontinued and are no longer sold on the web (though you can find the 65SM8600PUA used on Amazon according to the Diffbot Knowledge Graph).
Are these the “best for gaming”? That’s subjective and hard to evaluate, but these results certainly cannot be the “best-selling in 2023” if they are not even available for sale, except on a used Amazon listing. The steelman argument could be that these were the best selling TVs back in 2021 when the LLM was trained, but the response says that these are in 2023.
Next, Yusuf asks “which one of these is the cheapest?”
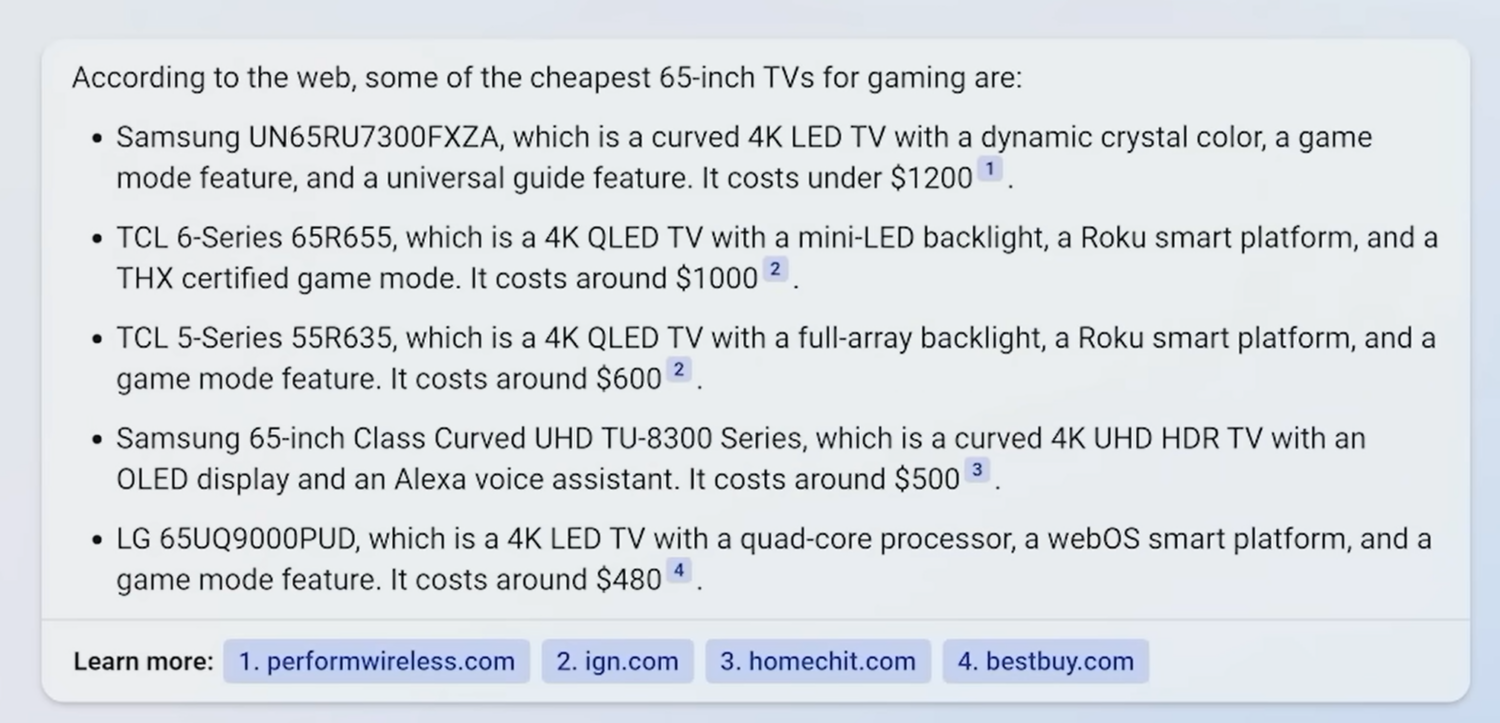
Again, these results look great in the context of a demo if you don’t look too carefully at what they are saying.

If you are actually trying to use Bing to do product research though, and have specific reasons for wanting the TV to be 65-inches (maybe that’s how much space you have to work with on your living room wall, or that is something you have already decided on based on previous reviews), then they aren’t so great. We can see here that one of the TVs recommended is 55 inches. And again Bing loses the context from the previous questions, with only 1 out of the 5 recommendations being a subset of the prior results, seemingly there by coincidence.
Let’s Learn about Japanese Poets
I think this example was put into the keynote to show how Bing Chat can be used to do more exploratory discovery, as a contrast to goal-oriented task sessions, which to be fair is a pretty great use case for LLMs.
Yusuf asks Bing Chat simply “top japanese poets”
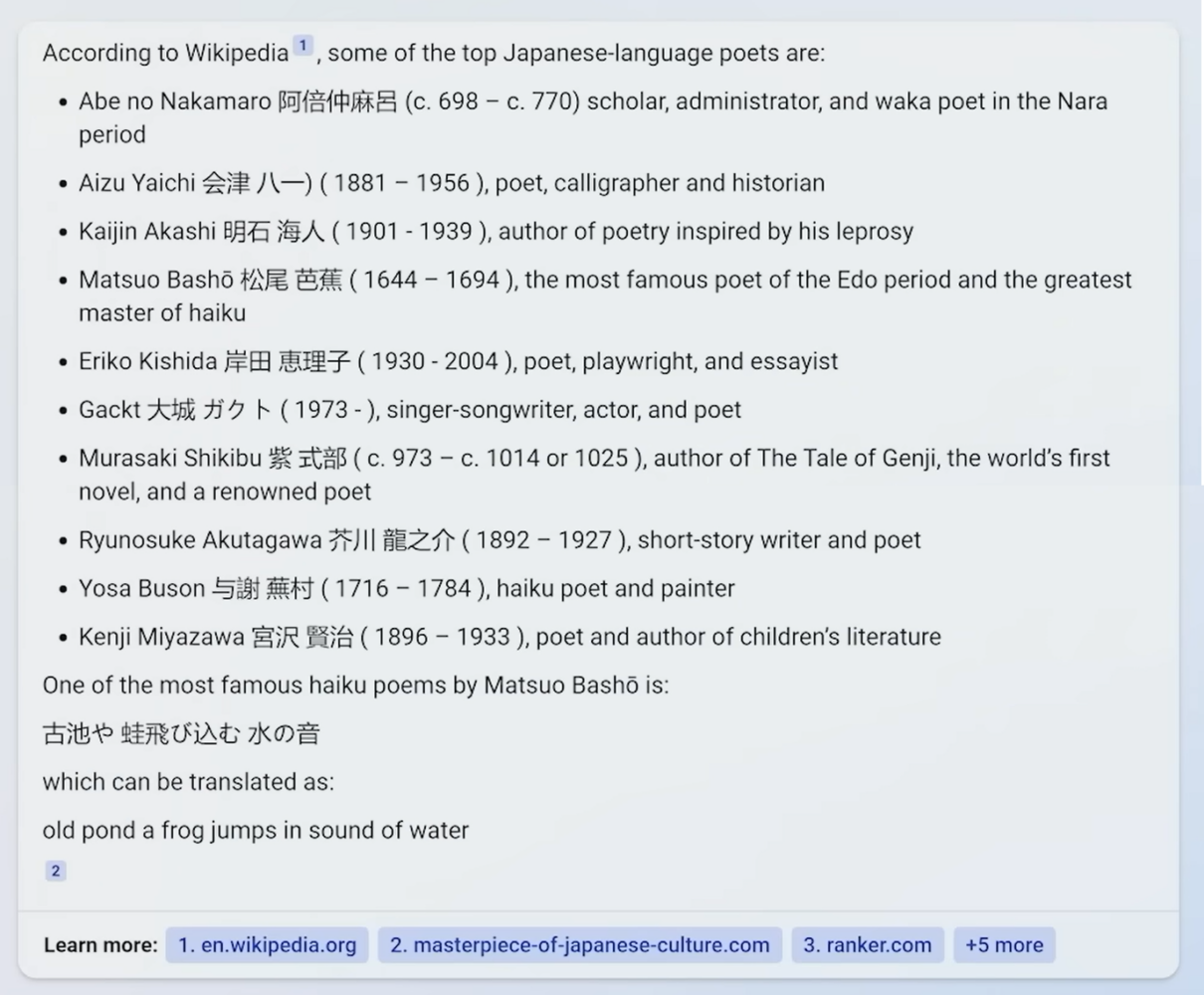
Again, this looks like a great result if you’re looking at the results with the mindset of a demo and not with the mindset of an actual learner trying to learn about Japanese poets. It certainly seems to come back faster and cleaner than the alternative of searching for an article on the web about famous Japanese poets written by an expert and dealing with the potentially jarring visual layout of visiting a new website. But is the underlying information correct?
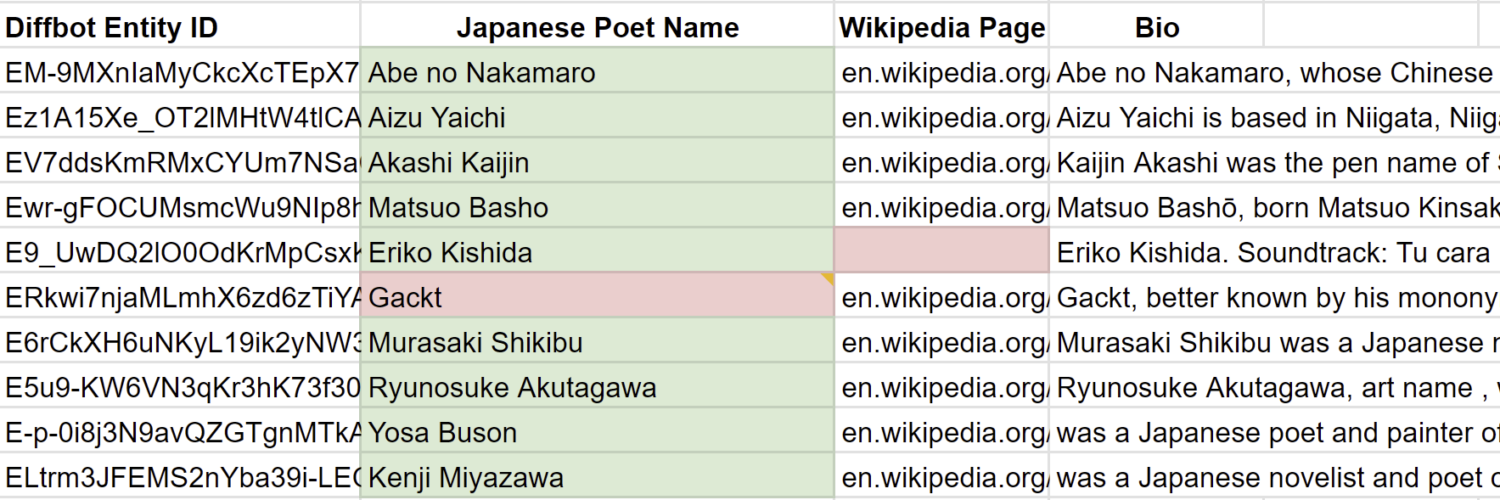
Well, it is mostly correct. But the question is asking for top Japanese poets, and Gackt (which I admit having listened to his songs during my teenage years), being a famous Japanese rock star and pop group, is definitely no poet. Yes, he could have written a poem, backstage, after a jam session, during a moment of reflection, but there is no charitable common-sense interpretation of this answer where Gackt is one of the top 10 Japanese poets. Another nit with this response is that Eriko Kishida has no Wikipedia page (though she has IMDB credits for writing the lyrics of many children’s TV shows) yet Bing claims “according to Wikipedia”. By citing Wikipedia for these results, Bing confers a greater sense of authority to these results than they actually deserve.
A General Recipe for Grounded Language Generation using Knowledge Graphs
So, how could both of these examples been improved by using a Knowledge Graph?
First of all, it’s important to recognize that not all use cases of LLMs require or desire accuracy. Many of the most impressive examples of LLM and multi-modal LLM outputs are examples where creativity and “hallucination” create a lot of artistic value and present the user with novel blends of styles that they would not have thought of. We love stories about unicorns and pictures of avocado chairs.
But for use cases where accuracy matters, whether this is because of an intersection of hard constraints, a need for auditability / review, or for augmenting professional services knowledge work, Knowledge Graphs can be used as a “rail” to guide the generation of the natural language output.
For these applications, a common design pattern is emerging for grounded language generation:
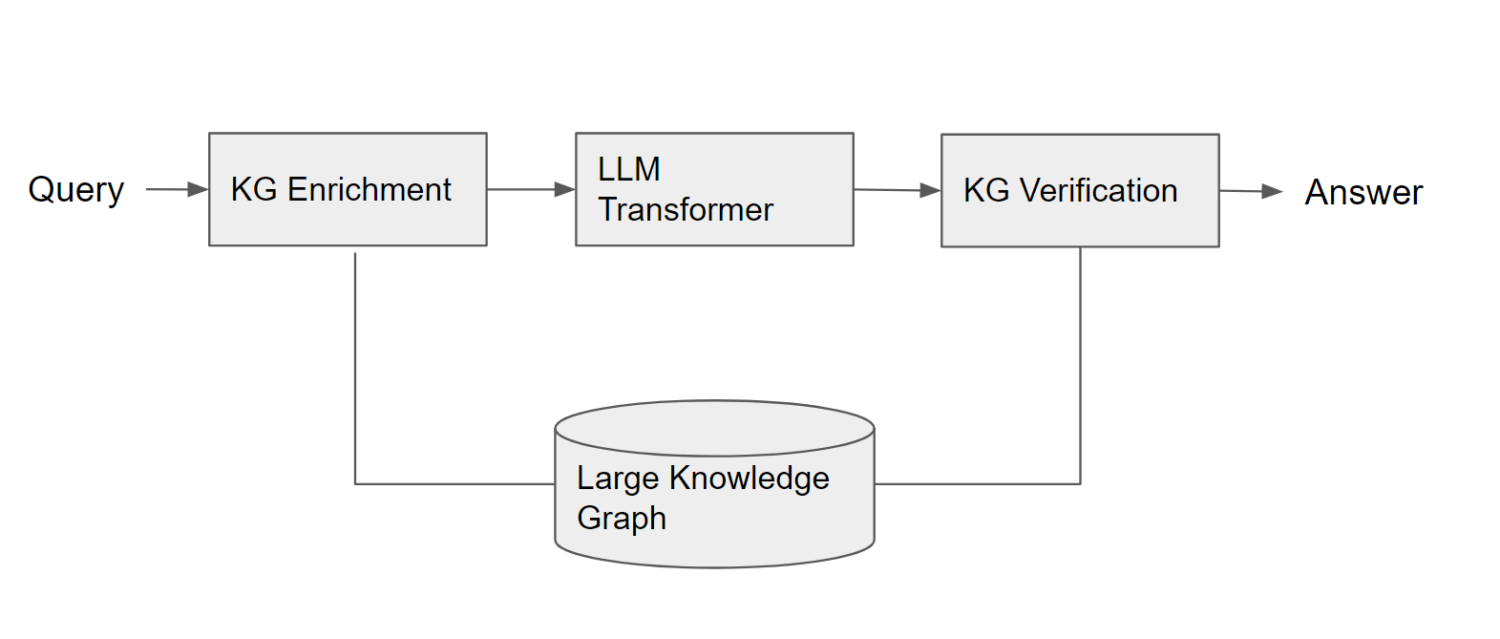
The first step is using the structured data of the Knowledge Graph to enrich the natural language of the query with structured data. In the example of the TV shopping and Japanese poets, it is recognizing that the question aligns with an entity type that is available in the Knowledge Graph. In the TV example it is “type:Product” and in the poets example it is “type:Person“. Knowing the requested entity type of the question is very useful, allowing you to type-check the responses later, and even present result UIs that are optimized for that type. There is an extensive line of academic research in this vein and Diffbot provides tools for structuring natural language.
The Enrichment step is also where you might pull in any additional information about entities that are mentioned in the natural language question. For example, if the question is “What are alternatives to Slack?”, you’d want to pull in information from the Knowledge Graph about Slack, structured attributes as well as text descriptions so that the LLM has more text to work with. This is especially important if the question contains entities that are not so popular on the web, or only known about privately.
Using the now augmented input, formulate a prompt for the LLM that provides this context and specifies the expected type of entity that is desired (e.g. products, companies, people, poets). Prompt engineering is becoming more-and-more of its own skillset, so we won’t cover that in detail here, but will show some examples of Knowledge Graph prompts in a follow up post.
As we’ve seen in the above two examples, even with the desired type provided to the LLM, it can still generate inaccurate outputs. This is where the next step of KG-based verification comes in. You can look up each of the LLM-generated results in a Knowledge Graph and discard results that do not match on the desired type or required attributes. This would have allowed you to discard the 55″ TV from the product result (specs), discontinued and non-existent products, and the Japanese rock star (employment) from the list of poets. If you have confidence in the completeness of your Knowledge Graph, you can discard any LLM-generated responses that don’t appear in the knowledge graph or only use candidates from the knowledge graph during the enrichment stage in the prompt.
Another aspect in which the Knowledge Graph can help in the rectification of the results is in the presentation itself. A Knowledge Graph can provide provenance for where each of the recommendations in the response came from, separately. For some applications, you can even use the Knowledge Graph to limit which facts are returned to only those facts that are in the Knowledge Graph, so that you have 100% provenance for everything that is shown to the user. In this mode, you can consider the LLM as a intelligent “SELECT” clause on the Knowledge Graph that adaptively picks which columns to present in the user experience based on the query. For many use cases, such as comparison product shopping, a tabular presentation of the products showing the title, image, price, specs, etc is a lot more user friendly to deal with than text, which is why it is the design of most shopping sites. Next-gen LLM/KG hybrid systems should take the lessons learned from UX design but use the new capabilities of LLMs to create adaptive inputs and outputs.
The future of trustworthy AI systems lies in the synergy between LLMs and Knowledge Graphs and knowing when it’s appropriate to use both. By combining the creative power of LLMs and the factual index of Knowledge Graphs, we can build systems that not only inspire creativity, but can be relied on for knowledge workflows and mission-critical applications.
You must be logged in to post a comment.