Data provenance (also referred to as “data lineage”) is metadata that is paired with records that details the origin, changes to, and details supporting the confidence or validity of data. Data provenance is important for tracking down errors within data and attributing them to sources. Additionally, data provenance can be useful in reporting and auditing for business and research processes.
Put most simply, the provenance of data helps to answer questions like “why was data produced,” “how was data produced,” “where was data produced,” “when was data produced,” and “by whom was data produced.” An example model of common provenance types can be seen below.
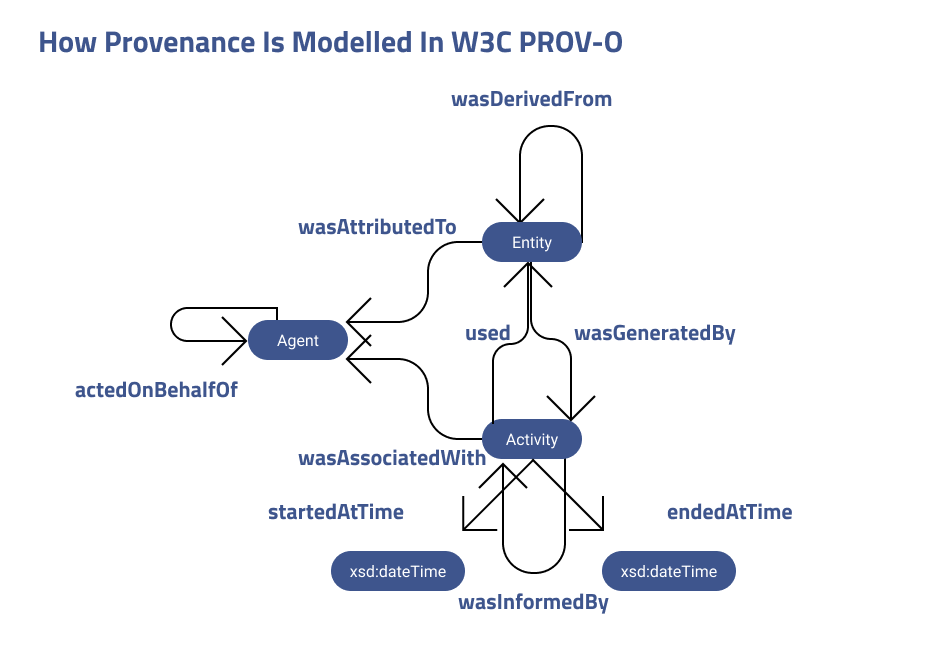
The W3 Provenance Incubator Group defines data provenance as
“a record that describes entities and processes involved in producing and delivering or otherwise influencing that resource. Provenance provides a critical foundation for assessing authenticity, enabling trust, and allowing reproducibility. Provenance assertions are a form of contextual metadata and can themselves become important records with their own provenance.”

The primary metadata points related to data provenance include:
- Data origin
- How data is transformed or augmented
- Where data moves over time
The primary uses of data provenance include:
- Validation of data
- Debugging of faulty data
- Regeneration of lost or corrupted data
- Analysis of Data Dependency
- Auditing and Compliance Rationales
The extent to which data provenance is important to an organization and implemented is typically influenced by:
- An enterprise’s data management strategy
- Regulations and Legal Requirements
- Reporting requirements
- Confidence requirements for critical segments of org data
- Data impact analysis
The primary motivations for producing and preserving data provenance include:
- Building credibility and trust in data, analysis and reporting
- Protect reproducibility in reporting and analysis
Unstructured data and data provenance
An estimated 80-90% of organizational data is unstructured. Additionally, the web is by-in-large almost entirely unstructured. Combined, this means that most organizations deal with unstructured data as at least some portion of nearly all of their data-centered activities. Sources of unstructured data of use to organizations are also growing much faster (as a share of utilized data and in total) than structured and curated data silos. Big data in particular is dominated by unstructured data sources, with an estimated 90% of big data residing in this form.
We should note that just because data is unstructured doesn’t mean it’s entirely chaotic. Rather, data is considered unstructured primarily because it (a) doesn’t reside in a database, or (b) doesn’t neatly fit into a database structure.
Two of the main issues organizations face when dealing with unstructured data include:
- Being able to prepare and unbox exactly what data is saying
- Being able to source the validity or origin of given data points (data provenance)
Diffbot’s Automatic Extraction APIs, Knowledge Graph, or Enhance are all potential solutions for these issues with unstructured data.
Data Provenance and Diffbot
Within Diffbot’s Knowledge Graph, facts are sourced data points about a given entity. As entities within the Knowledge Graph are contextually linked, a fact may also pertain to multiple entities. An example of this could be seen through the statement “Albert Einstein won the Nobel Prize.” This fact could be included within the Albert Einstein entity as one of his “awards won.” Simultaneously the Nobel Prize entity could include Albert Einstein within a field “recipients of.”
On average each of the entities within the Knowledge Graph has 22-25 facts. Each fact has an average of three origins or sources. The culmination of these validated facts of traceable origin is the single largest collection of web data that provides for data provenance.
When evaluating data providers, having data provenance ensures that you can trust and audit where the data comes from. Since Diffbot’s Knowledge Graph is built by an advanced AI system from the open web, it maintains various data provenance metadata about each of the trillions of facts in the Knowledge Graph, including:
- Origin: The source(s) of this fact on the public web
- Timestamp: When was this fact retrieved via crawling from the web?
- Precision: To what level of granularity / preciseness do we know this fact? Applies to numerical facts such as locations / times
- Confidence: The probability that the system believes this is a true fact
The Importance of Confidence
Each fact in the Diffbot Knowledge Graph has a confidence score, ranging from 0 to 1 that represents the system’s belief in the truth of the fact. Currently, all facts that have a computed confidence score below 0.5 are discarded from the Knowledge Graph. This score is calculated by a process we call Knowledge Fusion – an active area of machine learning research that involves automating the process of fusing information from multiple sources. Using Knowledge Fusion, we compute a trust score for every site on the web, and combine scores so that they represent a consistent view of the world.
Accessing Provenance Metadata in the Diffbot Knowledge Graph
As an example, let’s take the entity Apple Inc. in the Diffbot Knowledge Graph. Here is it’s summary information:

How do we know whether to trust that Apple was founded on April Fool’s Day, 1976?
By passing in parameter &jsonmode=extended to the appropriate DQL API call, we can see all of the additional metadata surrounding the foundingDate property of the Apple Inc. entity.
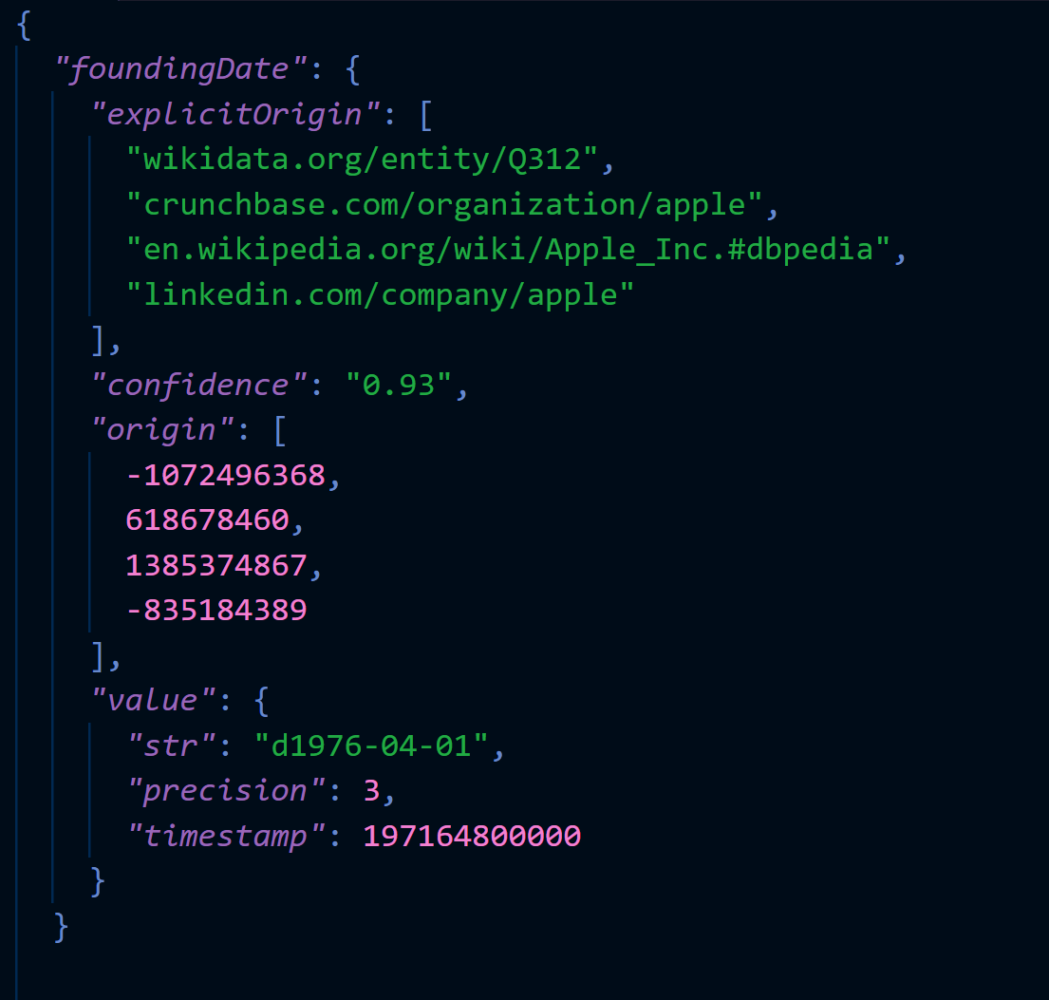
This tells us that there is a property foundingDate that has a value d1976-04-01. “precision”: 3 indicates that we know all three values of the date–the year, month, and day.
The explicitOrigin field tells us the pages on the public web that agree with this fact. Because these are pretty reputable sites, our algorithm computed a fairly high level of confidence in this fact: 93%.
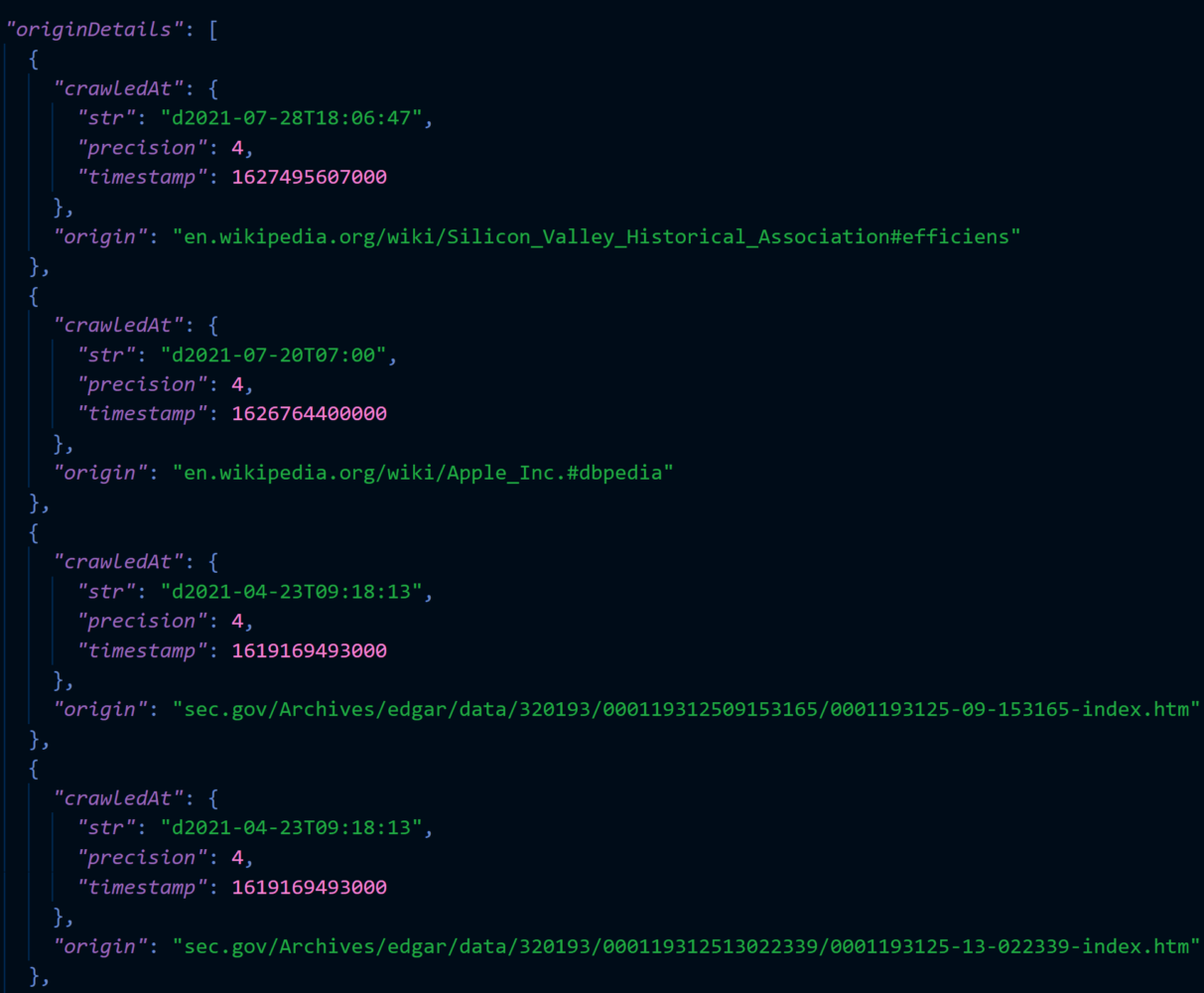
Freshness
Another piece of metadata (a fact about a fact) that is important in the context of business applications is freshness. There is nothing worse that making a business decision based on stale data. In order to trace the freshness of each fact in the Knowledge Graph, you can used the crawlTimestamp field as an overall summary of when this entity was computed. From an individual page-level, this is where the originDetails property is useful. The originDetails property will tell you the exact time each page that was used to calculate the Diffbot entity was visited by our system, giving you a precise way to audit the freshness of the data:
Data Provenance Research
- “A Survey of Data Provenance in e-Science”
- “A Survey of Data Provenance Techniques”
- “Big Data Provenance: Challenges, State of the Art and Opportunities”
See also transparency and explainability in AI.
You must be logged in to post a comment.