
Recommendation systems have become an essential component of modern technology, used in various applications such as e-commerce, search engines, and chat assistants. In this blog post, we’ll explore how to generate high-quality company recommendations using large language models like OpenAI’s GPT-4 and knowledge graphs. We’ll dive deep into the technical details, discussing challenges and potential solutions, and provide Python code snippets to help you get started with your own implementation.
Large Language Models for Company Recommendations
Large language models such as GPT-4 have shown remarkable capabilities in understanding and generating human-like text. By leveraging their contextual understanding and knowledge of various domains, we can use them to generate company recommendations based on user input.
To start, let’s create a function that takes a user’s query and returns a list of recommended companies using the GPT-4 model. A typical call to the GPT-4 API might look like this.
import openai
def generate_recommendations(prompt, model="gpt-4", max_tokens=100, n=5):
openai.api_key = OPENAI_API_KEY
completion = openai.ChatCompletion.create(model=model, messages=[{'role': 'user', 'content': prompt}])
return completion.choices[0].message.content.split('\n')LangChain has become a popular tool for building LLM applications by chaining together various calls to LLM APIs and providing prompt management. They recently raised a $10M seed round from Benchmark and are purportedly currently raising $20M from Sequoia.
Let’s try to find companies similar to LangChain by using the prompt “Recommend me five companies similar to LangChain (langchain.com)”:
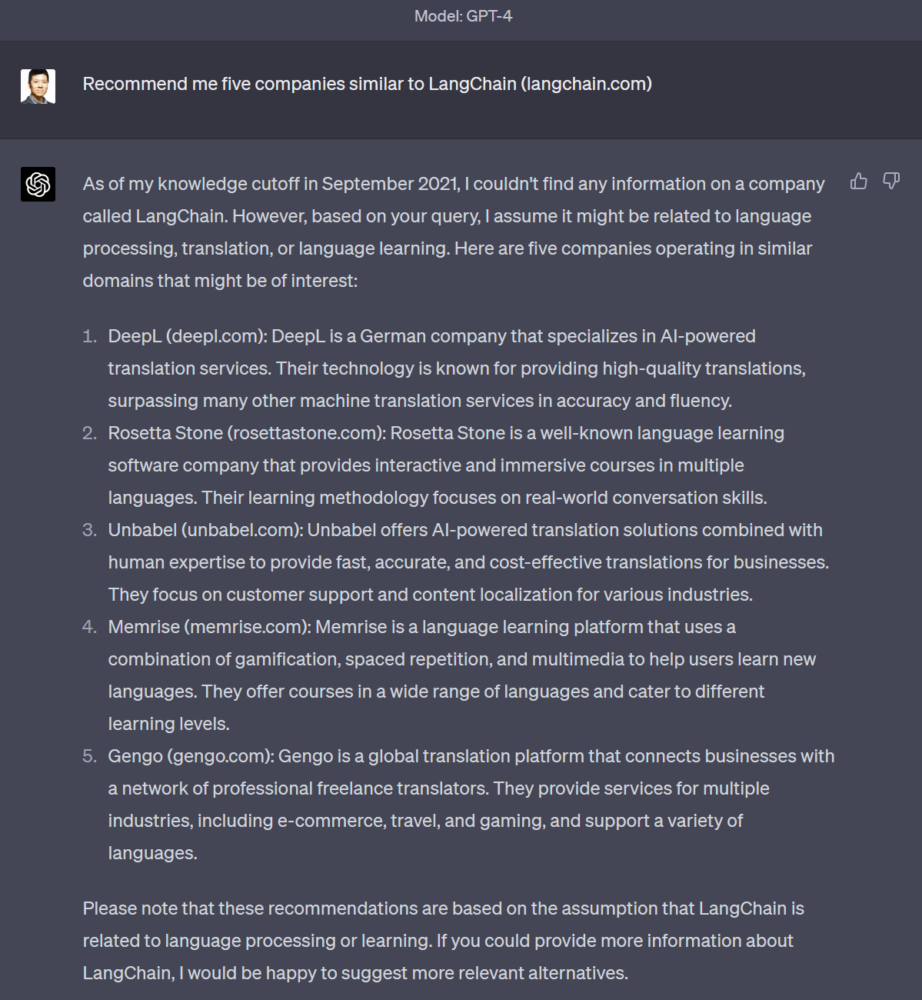
However, you will immediately run into one of the main problems of using LLMs for recommendations, which is that they are limited to the knowledge that was available at the time the LLM was trained (September 2021 according to GPT-4, here). Since the LangChain project was only started in late 2022, GPT-4 isn’t aware of it, and produces recommendations simply based on the name “LangChain”, returning back recommended companies that have to do with either translation services or language learning.
Freshness of information isn’t the only problem. Even if text describing the company was available at the time of training, if the company is a long-tail company (which most of the day-to-day entities you deal with likely are), a good representation of the company may not have been retained in the weights of the LLM. This is because of the nature of LLMs to “compress” the information in the original large corpus into a relatively smaller model, leading to invalid “hallucinated” answers in the generation when it is asked a rare question.
Knowledge Graphs for Enhanced Recommendations
Knowledge graphs are structured databases that store entities, attributes, and relationships between them. By using knowledge graphs, we can extract up-to-date and relevant information to enhance our recommendations. Unlike LLMs, which are lossy compressed representations of information stored in in-memory weights, a Knowledge Graph, like most databases, are exact representations of information and are retrieved from much larger disk-based storage.
There are a variety of languages used to ask Knowledge Graphs questions, e.g. GraphQL/SparkQL/SQL, but what they have in common is that they involve specifying your query in a precise way with typed statements and using predicates from a defined schema vocabulary. For example, to find companies “like LangChain”, we have to ask ourselves what “like LangChain” means. One reasonable interpretation of that might mean that we are looking for NLP startups that have also recently raised a Series A. This is what that question would look like, expressed in the Diffbot Query Language:
type:Company industries:"natural language processing" investments.series:"Series A"
This is what the results look like against the Diffbot Knowledge Graph.
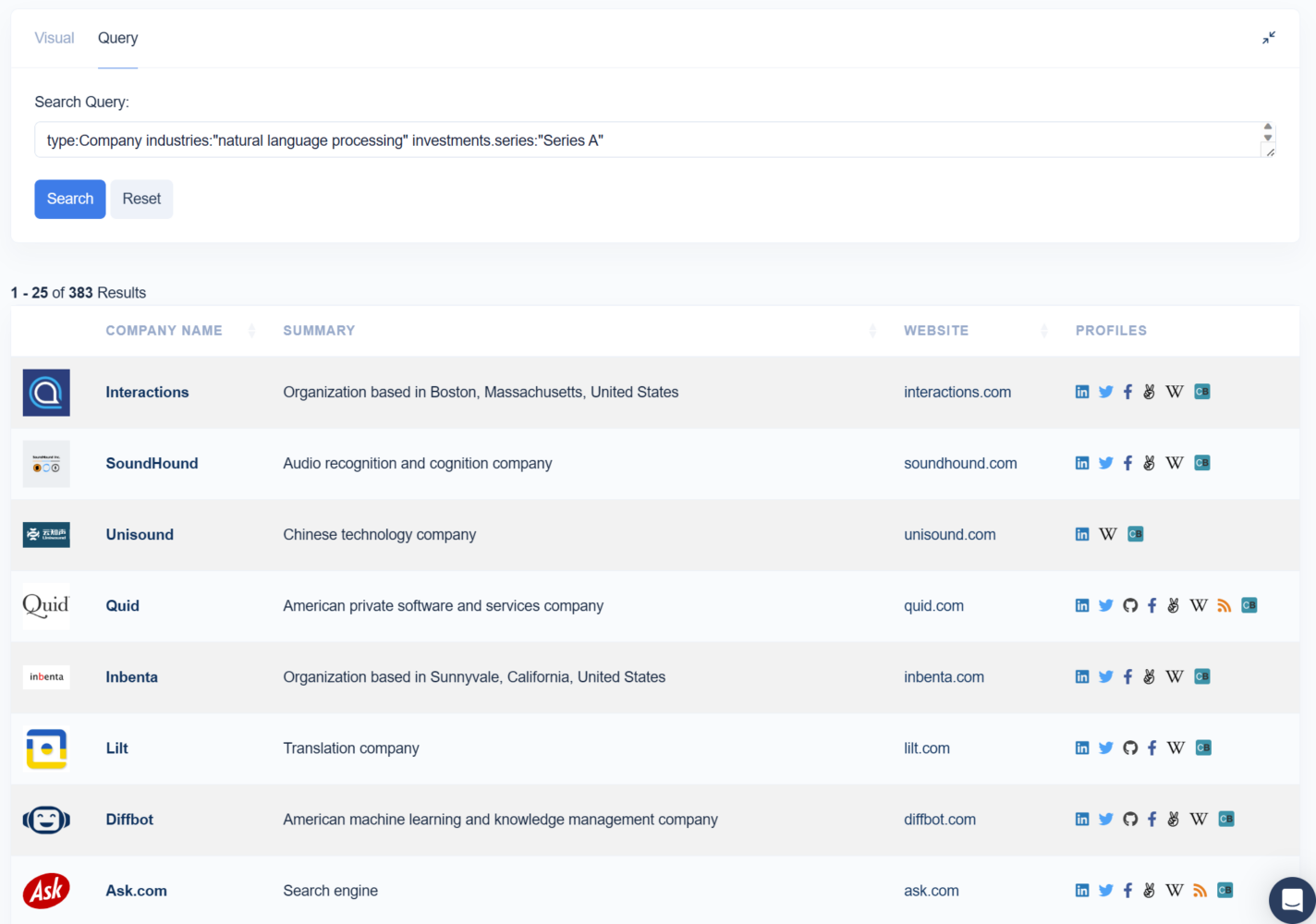
Structured knowledge bases give you back exactly what you asked for–i.e. there is a deterministic execution against a precise intent and you know exactly why each result is there. There is no room for hallucinations and no information is corrupted in the retrieval process.
However, the obvious downside is that the user had to do work to formulate a precise question. They also need to know the schema of the knowledge graph and what entity types and properties are available in order to “translate” their question into the structured query language.
Combining Large Language Models and Knowledge Graphs
What we’d really like is a system that’s like a smart human assistant that has access to a high-quality database of information. You could express what you want in your own language, without prior knowledge of the database schema or needing technical skill in querying.
Here’s what a recommendation function that combines and LLM with a KG might look like:
import re
import requests
def kg_enhance(company, url):
res = requests.get('https://kg.diffbot.com/kg/v3/enhance', params={
'token': DIFFBOT_TOKEN,
'type': 'Organization',
'name': company,
'url': url
})
data = res.json()['data']
return data[0]['entity'] if data else None
def kg_enhanced_recommendations(company, url):
prompt = f"Recommend me five companies that are similar to {company}. For each answer, include the name, (url), and up to 5 word summary."
# Lookup company in knowledge graph
input = kg_enhance(company, url)
if input:
prompt = f"About {company}:\n {input['description']}\n\n" + prompt
# Ask LLM using enhanced input
answers = generate_recommendations(prompt)
# Validate answers against KG
pattern = r'(\d+)?\.?\s?([\w\s]+)\s\(([^)]+)\)'
return [line for line in answers if (matches := re.match(pattern, line)) and kg_enhance(matches.group(2), matches.group(3))]In this code snippet, we first take our input company (LangChain), and look it up in the Knowledge Graph to get additional information about it using the Enhance API. In Diffbot’s Knowledge Graph, we can see that LangChain is described as a “large language model application development library”, is based in Singapore, and recently raised $10M. We can use this information to augment the prompt, so that the language model can know what the company actually does in order to recommend other companies that do similar things. Here is what the retrieval-augmented prompt, along with the output of GPT-4 looks like.
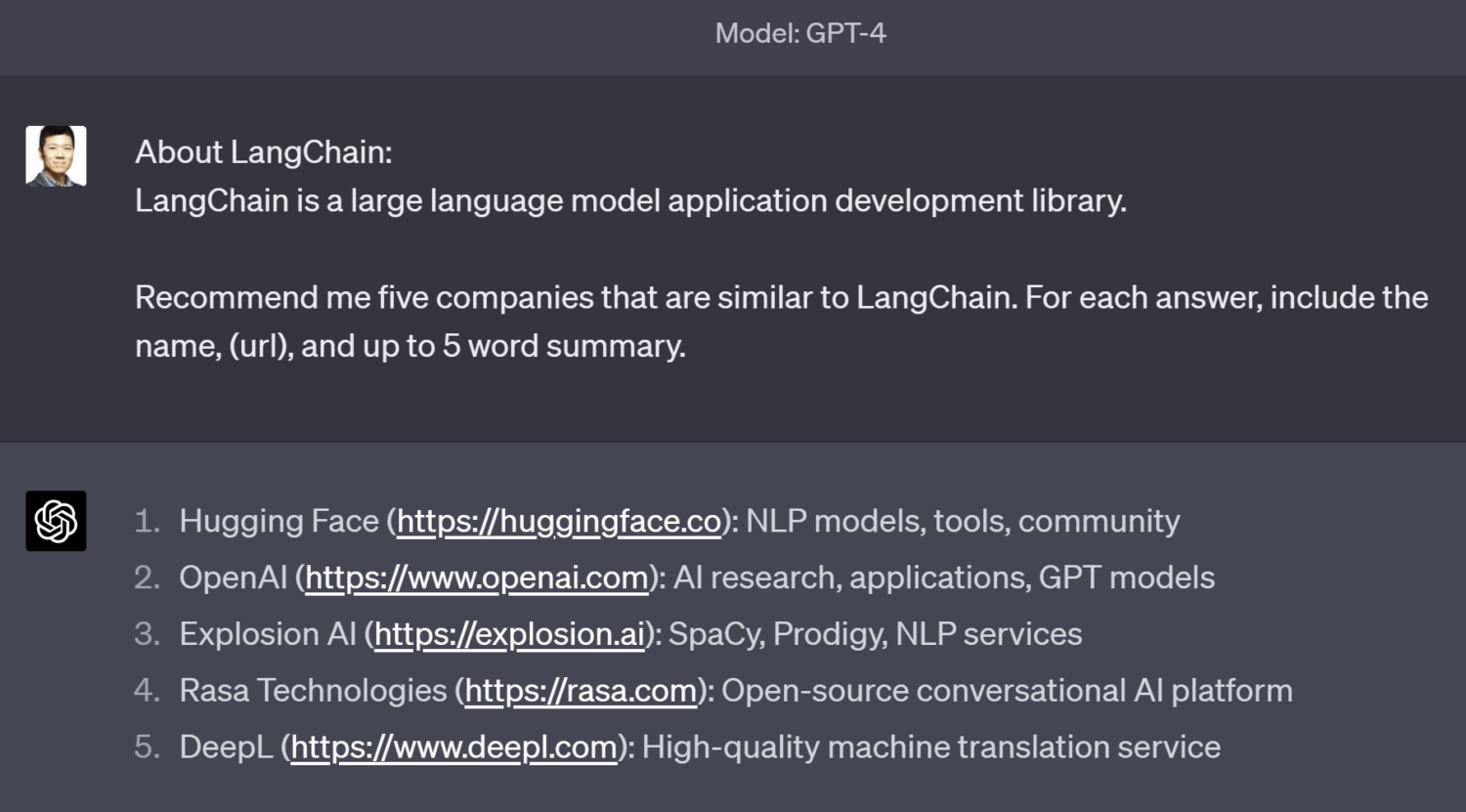
Much better! We see that the recommendations are no longer language learning services, but actually startup companies that provide NLP developer APIs that you can use in our own applications. This has solved the problem of lack of information at training time.
To solve the problem of hallucination, we can turn to the Knowledge Graph again to lookup each of these recommended companies by their name and URL to find their entities in the Diffbot Knowledge Graph. This code just checks that these return non-null company entities, but you could also add any manner of validation here on the returned entities (e.g. on industry=”natural language process”, nbEmployees<100 to enforce company size, etc.)
In this blog post, we demonstrated how to generate company recommendations using large language models like GPT-4 and large knowledge graphs such as the Diffbot Knowledge Graph. By combining these two powerful technologies, we can create a more accurate and reliable recommendation system than using either technology alone. While this example focused on company recommendations, the same approach can be applied to other domains and use cases, such as movie or book recommendations.
You must be logged in to post a comment.