

Today there are more products being sold online that there are humans on earth by a factor 100 times. Amazon alone has more than 400,000 product pages, each with multiple variations such as size, color, and shape — each with its own price, reviews, descriptions, and a host of other data points.
Imagine If you had access to all that product data in a database or spreadsheet. No matter what your industry, you could see a competitive price analysis in one place, rather than having to comb through individual listings.
Even just the pricing data alone would give at a huge advantage over anyone who doesn’t have that data. In a world where knowledge is power, and smart, fast decision making is the key to success, tomorrow belongs to the best informed, and extracting product information from web pages is how you get that data.
Obviously, you can’t visit 400 million e-commerce pages extract the info by hand, so that’s where web data extraction tools come in to help you out.
This guide will show you:
- What product and pricing data is, and what it looks like
- Examples of product data from the web
- Some tools to extract some data yourself
- How to acquire this type of data at scale
- Examples of how and why industries are using this data
What is Scraped Product Data?
“Scraped product data is any piece of information about a product that has been taken from a product web page and put into a format that computers can easily understand.”
This includes brand names, prices, descriptions, sizes, colors, and other metadata about the products including reviews, MPN, UPC, ISBN, SKU, discounts, availability and much more. Every category of product is different and has unique data points. The makeup of a product page, is known as its taxonomy.
So what does a product page look like when it is converted to data?
You can see what these look like for any e-commerce page, by pasting a URL into the free diffbot automatic product scraper.
For example, this listing from the amazon:
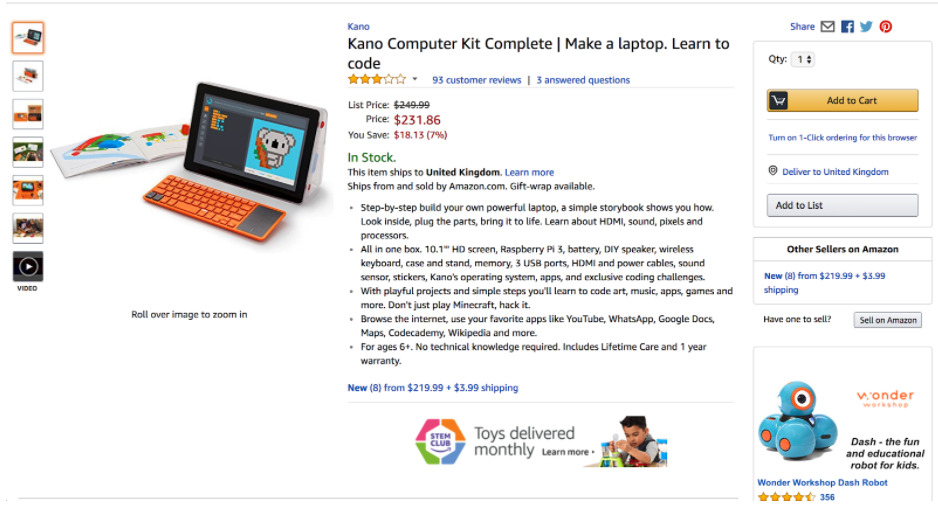
Becomes this:
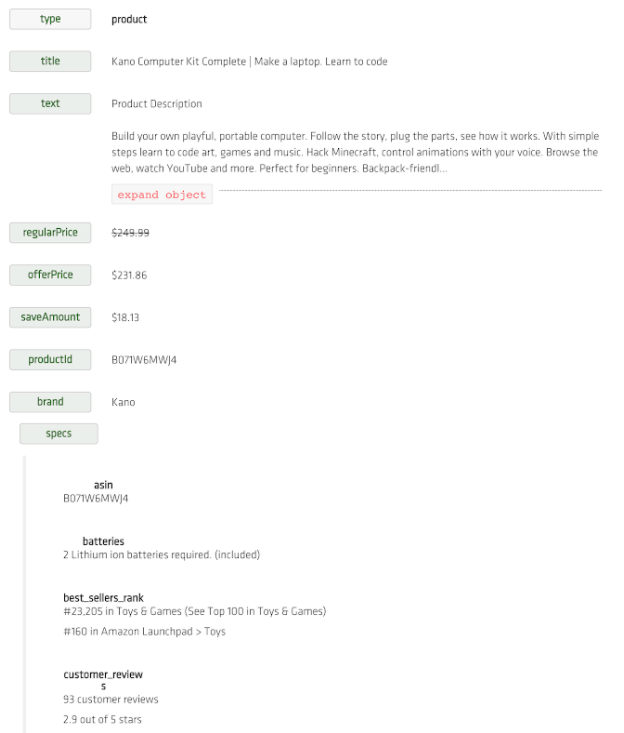
Or in the Json view
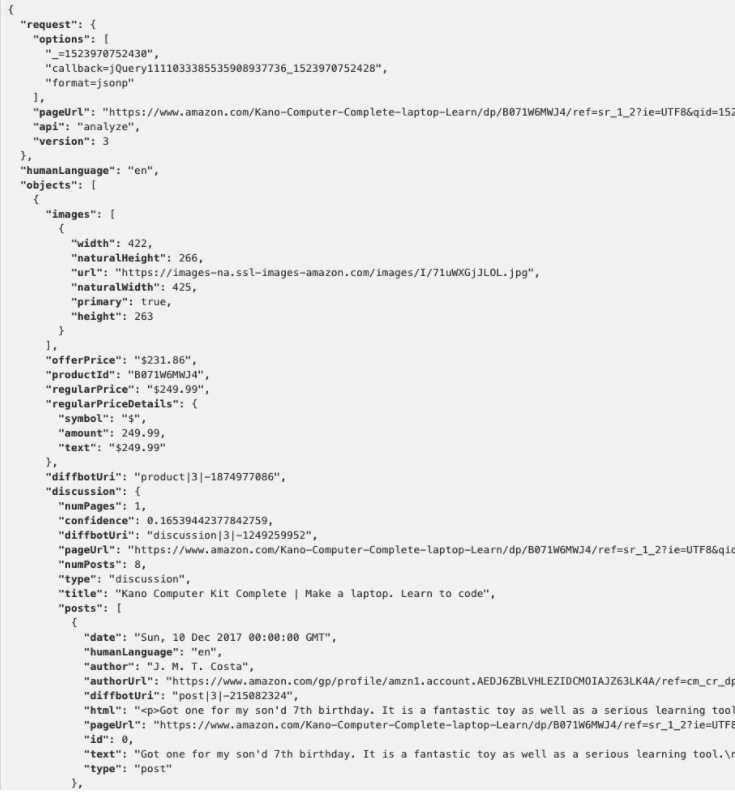
If you’re not a programmer or data scientist, the JSON view might look like nonsense. What you are seeing the data that have been extracted and turned into information that a computer can easily read and use.
What types of product data are there?
Imagine all the different kinds of products out there being sold online, and then also consider all the other things which could be considered products — property, businesses, stocks and, and even software!
So when you think about product data, it’s important to understand what data points there are for each of these product types. We find that almost all products fit into a core product taxonomy and then branch out from there with more specific information.
Core Product Taxonomy
Almost every item being sold online will have these common attributes:
- Product name
- Price
- Description
- Product ID
You might also notice that there are lots of other pieces of information available, too. For example, anyone looking to do pricing strategy for fashion items will need to know additional features of the products, like what color, size, and pattern the item is.
Product Taxonomy for Fashion
Clothing Items may also include
- Core Taxonomy plus
- Discounted Price
- Image(s)
- Availability
- Brand
- Reviews
- colors
- Size
- Material
- Specifications
- Collar = Turn Down Collar
- Sleeve =Long Sleeve
- Decoration = Pocket
- Fit_style = Slim
- Material = 98% Cotton and 2% Polyester
- Season = Spring, Summer, Autumn, Winter
What products can I get this data about?
Without wishing to create a list of every type of product on sold online, here are some prime examples that show the variety of products is possible to scrape.
- E-commerce platforms (Shopify, woocommerce, wpecommerce)
- Marketplace platforms (Amazon, eBay, Alibaba)
- Bespoke e-commerce (any other online store)
- Supermarket goods and Fast Moving Consumer Goods
- Cars and vehicles (Autotrader, etc.)
- Second-hand goods (Gumtree, Craigslist)
- Trains, planes, and automobiles (travel ticket prices)
- Hotels and leisure (Room prices, specs, and availability)
- Property (buying and renting prices and location)
How to Use Product Data
This section starts with a caveat. There are more ways to use product data than we could ever cover in one post. however here are;
Four of our favorites:
- Dynamic pricing strategy
- Search engine improvement
- Reseller RRP enforcement
- Data visualization
Data-Driven Pricing Strategy
Dynamic and competitive pricing are tools to help retailers and resellers answer the question: How much should you charge customers for your products?
The answer is long and complicated with many variables, but at the end of the day, there is only really one answer: What the market is will to pay for it right now.
Not super helpful, right? This is where things get interesting. The price someone is willing to pay is made up of a combination of factors, including supply, demand, ease, and trust.
In a nutshell
Increase prices when:
- When there is less competition for customers
- You are most trusted brand/supplier
- The easiest supplier to buy from
Reduce prices when:
- When there is more competition for customers, from many suppliers driving down prices
- Other suppliers are more trusted
- Other suppliers are easier to buy from
Obviously, this is an oversimplification, but it demonstrates how if you know what the market is doing you can adjust your own pricing to maximize profit.
When to set prices?
The pinnacle of pricing strategy is in using scraped pricing data to automatically change prices for you.
Some big brands and power sellers us dynamic pricing algorithms to monitor stock levels of certain books (price tracked via ISBN) on sites like Amazon and eBay, and increase or decrease the price of a specific book to reflect its rarity.
They can change the prices of their books by the second without any human intervention and never sell an in-demand item for less than the market is willing to pay.
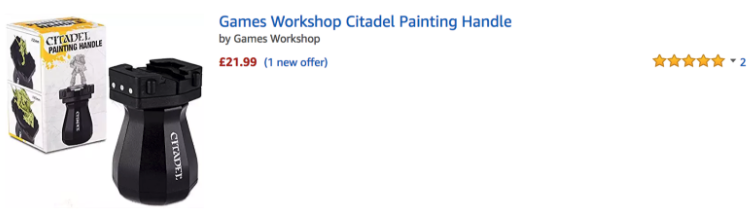
Great example:
When the official store runs out of stock (at £5)

The resellers can Ramp up pricing on Amazon by 359.8% (£21.99)
Creating and Improving Search Engine Performance
Search engines are amazing pieces of technology. They not only index and categorize huge volumes of information and let you search, but some also figure out what you are looking for and what the best results for you are.
Product data APIs can be used for search in two ways:
- To easily create search engines
- To improve and extend the capabilities of existing search engines with better data
How to quickly make a product search engine with diffbot
You don’t need to be an expert to make a product search engine. All you need to do is:
- Get product data from websites
- Import that data into a search as a service tool like Algolia
- Embed the search bar into your site
What kind of product data?
Most often search engine developers are actually only interested in the products they sell, as they should be, and want as much data as they can get about them. Interestingly, they can’t always get that from their own databases for a variety of reasons:
- Development teams are siloed and they don’t have access, or it would take too long to navigate corporate structure to get access.
- The database is too complex or messy to easily work with
- The content in their database is full of unstructured text fields
- The content in their database is primarily user-generated
- The content in their database doesn’t have the most useful data points that they would like, such as review scores, entities in discussion content, non-standard product specs.
So the way they get this data is by crawling their own e-commerce pages, and letting AI structure all the data on their product pages for them. Then they have access to all the data they have in their own database without having to jump through hoops.
Manufacturers Reseller RRP Enforcement
Everyone knows about Recommended Retail Price (RRP), but not as many people know it’s cousins MRP (Minimum Retail Price) and MAP (Minimum Advertised Price).
If you are a manufacturer of goods which are resold online by many thousands of websites, you need to enforce a minimum price and make sure your resellers stick to it. This helps you maintain control over your brand, manage its reputation, and create a fair marketplace.
Obviously, some sellers will bend the rules now and then to get an unfair advantage — like doing o a sub-MRP discount for a few hours on a Saturday morning when they think nobody is paying attention. This causes problems and needs to be mitigated.
How do you do that?
You use a product page web scraper and write one script, which sucks in the price every one of your resellers is charging, and automatically checks it against RRP for you every 15 minutes. When a cheeky retailer tries to undercut the MRP, you get an email informing you of the transgression and can spring into action.
It’s a simple and elegant solution that just isn’t possible to achieve any other way.
This is also a powerful technique to ensure your product are being sold in the correct regions at the correct prices at the right times.
Data visualization
Beyond just being nice to look at and an interesting things to make, data visualization takes on a very serious role at many companies who use them to generate insights that lead to increased sales, productivity and clarity in their business.
Some simple examples are:
- Showing the price of an item around the world
- Charting trends products over time
- Graphing competitors products and pricing
A stand out application of this is using in the housing agency and property development worlds where it’s child’s play to scrape properties for sale (properties are products) and create a living map of house prices and stay ahead of the trends in the market, either locally or nationally.
There is some great data journalism using product data like this, and we can see some excellent reporting here:
Here are some awesome tools that can help you with data visualization:
Let’s talk about Product Data APIs
So now you get the idea that getting information off product pages to use for your business is a thing, now let’s dive into how you can get your hands on it.
The main way to retrieve product data is through an API, which allows anyone with the right skill set to take data from a website and pull it into a database, program, or Excel file — which is what you as a business owner or manufacturer want to see.
Because information on websites doesn’t follow a standard layout, web pages are known as ‘unstructured data.’ APIs are the cure for that problem because they let you access the products of a website in a better more structured format, which is infinitely more useful when you’re doing analysis and calculations.
“A good way to think about the difference between structured and unstructured product data is to think about the difference between a set of Word documents vs. an Excel file.
A web page is like a Word document — all the information you need about a single product is there, but it’s not in a format that you can use to do calculations or formulas on. Structured data, which you get through an API, is more like having all of the info from those pages copy and pasted into a single excel spreadsheet with the prices and attributes all nicely put into rows and columns”
APIs for product data sound great! How can I use them?
Sometimes a website will give you a product API or a search API, which you can use to get what you need. However, only a small percentage of sites have an API, which leaves a few options for getting the data:
- Manually copy and paste prices into Excel yourself
- Pay someone to write scraping scripts for every site you want data from
- Use an AI tool that can scrape any website and make an API for you.
- Buy a data feed direct from a data provider
Each of these options has pros and cons, which we will cover now.
How to get product data from any website
1) Manually copy and paste prices into Excel
This is the worst option of all and it NOT recommended for the majority of use cases.
Pros: Free, and may work for extremely niche, extremely small numbers of products, where the frequency of product change is low.
Cons: Costs your time, prone to human error, and doesn’t scale past a handful of products being checked every now and then.
2) Paying a freelancer or use an in-house developer to write rules-based scraping scripts to get the data into a database
These scripts are essentially a more automated version of visiting the site yourself and extracting the data points, according to where you tell a bot to look.
You can pay a freelancer, or one of your in-house developers to write a ‘script’ for a specific site which will scrape the product details from that site according to some rules they set.
These types of scripts have come to define scrapers over the last 20 years, but they are quickly becoming obsolete. The ‘rules-based’ nature refers to the lack of AI and the simplistic approaches which were and are still used by most developers who make these kinds of scripts today.
Pros: May work and be cheap in the short term, and may be suited to one-off rounds of data collection. Some people have managed to make this approach work with very sophisticated systems, and the very best people can have a lot experience forcing these systems to work.
Cons: You need to pay a freelancer to do this work, which can be pricey if you want someone who can generate results quickly and without a lot of hassle.
At worst this method is unlikely to be successful at even moderate scale, for high volume, high-frequency scraping in the medium to long term. At best it will work but is incredibly inefficient. In a competition with more modern practices, they lose every time.
This is because the older approach to the problem uses humans manually looking at and writing code for every website you want to scrape on a site by site basis.
That causes two main issues:
- When you try to scale that it gets expensive. Fast. You developer must inherently write (and maintain) at least one scraper per website you want data from. That takes time.
- When any one of those websites breaks the developer has to go back and re-write the scraper again. This happens more often than you imagine, particularly on larger websites like Amazon who are constantly trying out new things, and whose code is unpredictable.
Now we have AI technology that doesn’t rely on rules set by humans, but rather with computer vision they can look at the sites themselves and find the right data much the same way a human would. We can remove the human from the system entirely and let the AI build and maintain everything on its own.
Plus, It never gets tired, never makes human errors, and is constantly alert for issues which it can automatically fix itself.Think of it as a self-driving fleet vs. employing 10,000 drivers.
The last nail in the coffin for rules-based scrapers is that they require long-term investment in multiple classes of software and hardware, which means maintenance overhead, management time, and infrastructure costs.
Modern web data extraction companies leverage AI and deep learning techniques which make writing a specific scraper for a specific site a thing of the past. Instead, focus your developer on doing the work to get insights out of the data delivered by these AI.
Tools to use
- Freelancers on Upwork
- Python and Beautifulsoup
- A freelancer and Scrapy
Quora also has a lot of great information about how to utilize these scripts if you chose to go this route for obtaining your product data.
3) Getting an API for the websites you want product data from
As discussed earlier, APIs are a simple interface that any data scientist or programmer can plug into and get data out. Modern AI product scraping services (like diffbot) take any URLs you give them and provide perfectly formatted, clean, normalized, and highly accurate product data within minutes.
There is no need to write any code, or even look at the website you want data from. You simply give the API a URL and it gives your team all the data from that page automatically over the cloud.
No need to pay for servers, proxies or any of that expensive complexity. Plus, the setup in order of magnitude faster and easier.
Pros:
- No programming required for extraction, you just get the data in the right format.
- They are 100 percent cloud-based, so there is no capex on an infrastructure to scrape the data.
- Simple to use: You don’t even need to tell the scraper what data you want, it just gets everything automatically. Sometimes even things you didn’t realize were there.
- More accurate data
- Doesn’t break when a website you’re interested in changes its design or tweaks its code
- Doesn’t break when websites block your IP or proxy
- Gives you all the data available
- Quick to get started
Cons:
- Too much data. Because you’re not specifying what data you’re specifically interested in, you may find the AI-driven product scrapers pick up more data than you’re looking for. However, all you need do is ignore the extra data.
- You could end up with bad data (or no data at all) if you do not know what you’re doing
Tools to use:
4) Buy a data feed direct from a data provider
If you can buy the data directly, that can be the best direction to go. What could be easier than buying access to a product dataset, and integrating that into your business? This is especially true if the data is fresh, complete and trustworthy.
Pros:
<li>Easy to understand acquistion process.</li>
<li>You do not need to spend time learning how to write data scraping scripts or hiring someone who does.</li>
<li>You have the support of a company behind you if issues arise.</li>
<li>Quick to start as long as you have the resources to purchase data and know what you are looking for.</li>
Cons:
- Can be more expensive, and the availability of datasets might not be great in your industry or vertical.
- Inflexible rigid columns. These datasets can suffer from an inflexible rigid taxonomy meaning “you get what you get” with little or no option to customize. You’re limited to what the provider has in the data set, and often can’t add anything to it.
- Transparency is important when looking at buying data sets. You are not in control of the various dimensions such as geolocation, so be prepared to specify exactly what you want upfront and check they are giving you the data you want and that it’s coming from the places you want.
Putting It All Together
Now that you know what scraped product data is, how you can use that data, and how to get it, the only thing left to do is start utilizing it for your business. No matter what industry you are in, using this data can totally transform the way you do business by letting you see your competitors and your consumers in a whole new way — literally.
The best part is that you can use existing data and technology to automate your processes, which gives you more time to focus on strategic priorities because you’re not worrying about minutia like prices changes and item specifications.
While we’ve covered a lot of the basics about product data in this guide, it’s by no means 100 percent complete. Forums like Quora provide great resources for specific questions you have or issues you may encounter.
Do you have an example of how scraped product data has helped your business? Or maybe a lesson learned along the way? Tell us about it in the comments section.


You must be logged in to post a comment.