
Every now and then it’s important to get back to basics and ask a question which seems obvious, because sometimes those questions have hidden depths. The question “What Is Product Data?” is one of those I recently asked myself, and it led me down a mini-rabbit hole.
The basic definition of a product is:
“A thing produced by labor, such as products of farm and factory; or the product of thought, time or space.”
When you think about it, that covers a lot of ground. By definition, a product can be almost anything you can imagine — from any item on the supermarket shelf, to an eBook, a house, or even just a theory.
So how do we at Diffbot pare down the definition from almost anything in the world, to a useful definition for someone interested in data?
What is a useful definition of a product in the context of data?
“A product is a physical or digital good, which has the attributes of existing, having a name, being tradable.” Beyond that, all bets are off.
So to frame that in the context of data, the universal attributes of a product are data attributes, like Identifier and Price.
There is, obviously, more to most product data than that. So how do you define a set of attributes (or taxonomy) that is useful, and defines all products as data? We’ve come up with a couple approaches to that question.
Approaches to defining a product as data:
1. Product Schema
One way people try to define product data is by imagining every possible product attribute, and then creating a massive set of predefined product types and the attributes each type is expected to have. Then they publish that as a schema.
Schema.org is an attempt at that exercise.
Their definition of a product is:
“Any offered product or service. For example: a pair of shoes; a concert ticket; the rental of a car; a haircut; or an episode of a TV show streamed online.”
They have tried to make a universal product taxonomy by setting out more than 30 attributes they think can cover any product — and even a set of additional attributes that can be used to add extra context to the product.
The primary aim of their schema for product data is to allow website owners to “markup” their website HTML more accurately. This method has had some success, with over one million websites using their product definition. Sadly, this is still less than 0.3% of all websites.
Schema.org works well for its intended purpose, and it does a good job at providing a framework to structure what a physical product is. But it also falls short on several fronts.
The downside of this approach is that by trying to fix a set number of attributes for all products, they exclude a vast amount of product data and limit the scope to only ever being a fraction of the data that could be available. Not only that but they require website creators to spend time adding this data themselves.
Take the example of a hard disk drive. It has some attributes that fit into Schema.org’s product data definition, but it also has 10x more data that could be available to users. For instance, there is a full table of specifications that don’t fit into the premade definitions like these for the product.
WD Red 4TB NAS Hard Disk Drive – 5400 RPM Class SATA 6GB/S 64 MB Cache 3.5-Inch
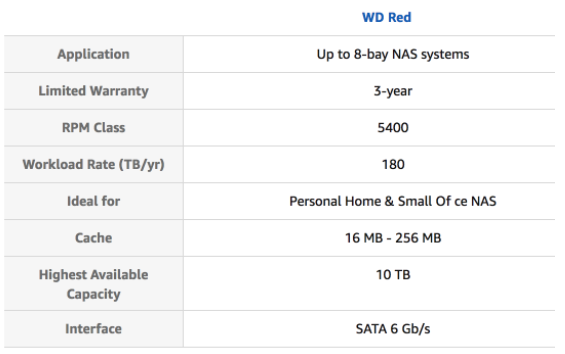
The problem is that there are so many different data points a product could have, that you can never define a universal product spec for them all. So there needs to be another way to describe products as data.
2. AI Defined Product Data
The main problem with the “universal product data definition” is that someone has to try to foresee any and all combinations, and then formalize them into a spec.
The beauty of the AI approach is that it doesn’t approach product data with any preconceived ideas of what a product should look like. Instead, it looks at data in a way similar to how a human would approach it. Using AI, you can let the product itself define the data, rather than trying to make a product fit into your pre-made classifications. The process basically looks like this:
- Load a product page
- Look at all the structures, layouts, and images
- Us AI, and computer vision techniques to decide what is relevant product data
- Use the available data to define the product
- Organize the data into a table like structure (or JSON file for experts)
You can use a smart product crawler like Diffbot to define any product data for any product.
Finally, we can define a what product is by using AI to look at the product is. So if we can now reliably define what a product is, and we can get all the data about what it is, what else do we need to know about product data?
3. Product Meta Data
Product metadata is the data about a product which is not necessarily a physical aspect of the item, but rather some intellectual information about it.It should also be considered product data. Product metadata may include:
- Its location
- Its availability
- Its review score
- What other products it is related to
- Other products people also buy or view
- Where it appears in keyword searches
- How many sellers there are for the product
- Is it one of a number of variations
Summary
Before getting any further down the rabbit hole of product semantics, data, knowledge graphs, Google product feeds and all the other many directions this question can take you, it’s time to stop and reconsider the original question.
What is Product Data?
Product data is all the information about a product which can be read, measured and structured into a usable format. There is no universal fixed schema that can cover all aspects of all products, but there are tools that can help you extract a product’s data and create dynamic definitions for you. No two products are the same, so we treat both the product and its data as individual items. We don’t put them into premade boxes. Instead, we understand that there are many data points shared between products, and there are more which are not.
As an individual or team interested in product data, the best thing you can do is use Diffbot’s AI to build datasets for you, with all the information, and then choose only the data you need.
Related posts:
You must be logged in to post a comment.