Coreference resolution is the natural language processing-related task of identifying all mentions of a given real world entity in text.
After grouping all mentions of the same real world entity, pronouns can be replaced with noun phrases reducing ambiguity and resolving which nouns are being referenced in which context.


Coreference resolution is oftentimes vital for disambiguating sentences and making them more machine readable. In particular, coreference resolution supports tasks including sentiment analysis, machine translation, document summarization, information extraction, and text understanding.
Applications of coreference resolution
Natural language corpora with many pronouns can often be difficult for machines to understand. By incorporating additional context a much more granular understanding of unstructured natural language text can surface. Applications where coreference resolution is particularly critical include the parsing of less formal document or writing styles. While medical records may not rely on substantial use of varying pronouns, reviews, articles, and creative works may rely on pronouns and mentions of many entities within single lines of text.
The applications of the ability to parse less formal document writing styles include the answering of questions (chatbots), support ticket routing, translation between languages, and the ability to summarize documents.
Anaphora, cataphora, and coreference resolution
An important distinction is that coreference resolution deals primarily with determining when two words refer to the same real world entity. This primarily surfaces when we have a noun that is later referenced by a pronoun.
Coreference resolution is a general category of tasks that involve determining when the same real world entity is being referenced multiple times. A vast majority of resolution tasks rely on simply coreference.
Two related resolution tasks are worth noting because historically algorithms that help with resolution are built to deal with one type of resolution (missing others).
These related resolution tasks include anaphora resolution and cataphora resolution.
Anaphora resolution involves resolving meaning when two real world entities are mentioned, but the first entity mentioned changes the meaning of the second.

In the above example, humans can infer that the tickets mentioned are likely for the sporting event. Depending on the type of relationships you’re trying to track, this could lead to a modifier about the tickets, noting they’re sporting event tickets.

Cataphora resolution is very similar to anaphora resolution but in reverse. This form of resolution occurs when two real world entities are mentioned but the second changes the meaning of the first.
Diffbot and Coreference Resolution
Diffbot’s Natural Language API provides benchmark-topping coreference resolution. Utilizing the power of the world’s largest Knowledge Graph, our NL API can further disambiguate entities based on information structured from across the web. Each entity extracted from natural language is provided with a unique identifier that can be paired up with one of the billions of Diffbot unique resource identifiers (diffbotUri’s) within the Knowledge Graph. This enables best-in-class disambiguation, data enrichment, and the ability to pair your natural language entity mentions with facts sourced from throughout the web.
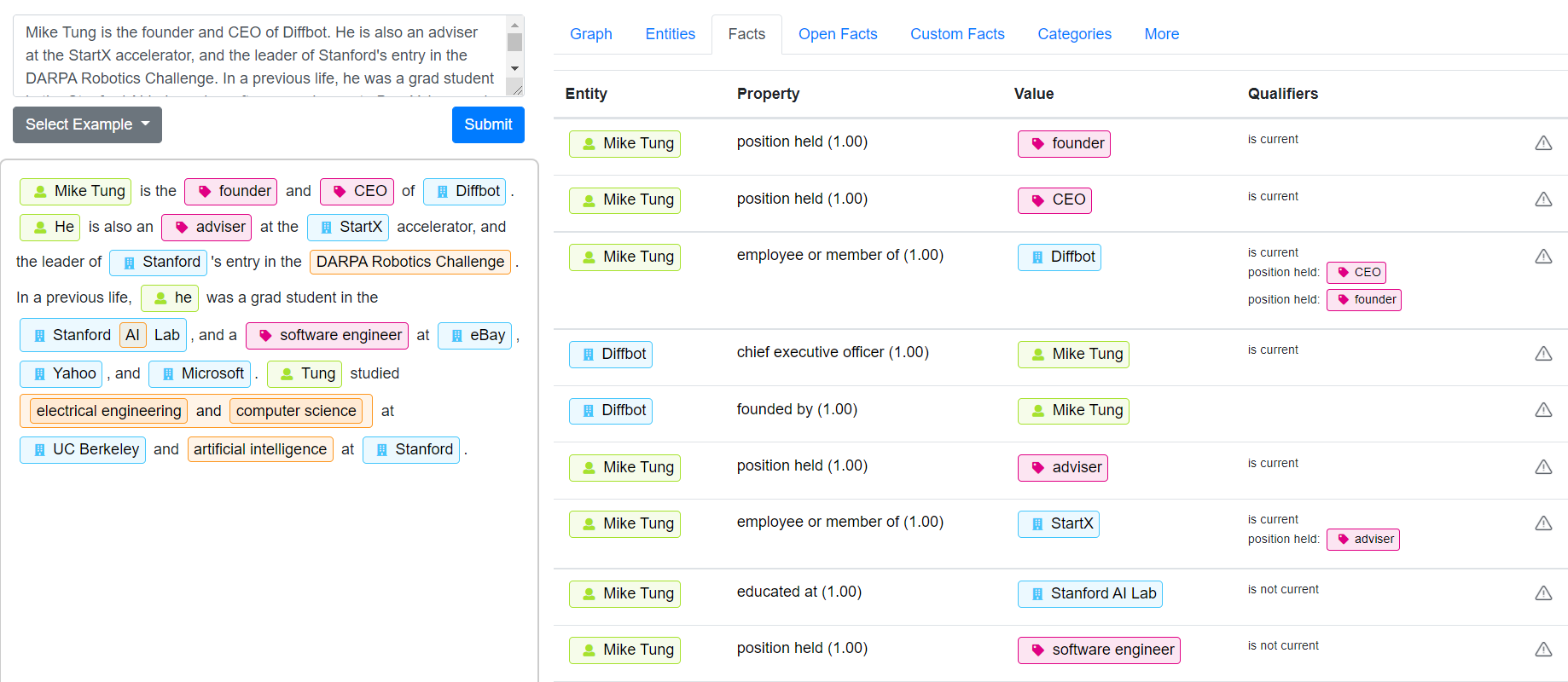
Check out entity identification, sentiment, relationships, and coreference resolution at work in our non-vaporware Natural Language API demo (shown above).
You must be logged in to post a comment.