Skip Ahead
- How To Scrape Paginated Pages
- Solution One: Visit Each Page Separately
- Solution Two: Webdrivers
- Solution Three: Apply Extraction Through a Crawler
- How To Scrape Pages With Dynamically Created Class Names
- Option One: Use CSS Selectors
- Option Two: Rely On Hierarchy Depth
- Option Three: Return A Wider Set of Nodes And Parse On Your End
- Option Four: Rely On Computer Vision
- How To Scrape Content Held In Iframes
- Option One: Use a Visual Web Extraction Editor
- Option Two: Follow The IFrame Link
- Option Three: Rely On Computer Vision
- How To Scrape Pages With Too Many Steps To Get To Data
- Option One: Complicated Web Driver Maneuvers
- Option Two: Find The Underlying Data
- Option Three: Rely On A Crawler To Reach Hard-To-Find On-Site Locations
- How To Scrape Lazy Loading Sites
- Option One: Determine How Lazy Loaded Blocks Are Loaded
- Option Two: Utilize a Scraper That Enables Javascript Evaluation
Phrases like “the web is held together by [insert ad hoc, totally precarious binding agent]” have been around for a while for a reason.
While the services we rely on tend to sport hugely impressive availability considering, that still doesn’t negate the fact that the macro web is a tangled mess of semi or unstructured data, and site-by-site nuances.
Put this together with the fact that the web is by far our largest source of valuable external data, and you have a task as high reward as it is error prone. That task is web scraping.
As one of three western entities to crawl and structure a vast majority of the web, we’ve learned a thing or two about where web crawling can wrong. And incorporated many solutions into our rule-less Automatic Extraction APIs and Crawlbot.
In this guide we round up some of the most common challenges for teams or individuals trying to harvest data from the public web. And we provide a workaround for each. Want to see what rule-less extraction looks like for your site of interest? Check out our extraction test drive!
Skip To:
- How To Scrape Paginated Pages
- How To Scrape Behind Logged In Pages
- How To Scrape Pages With Dynamically Created Class Names
- How To Scrape Content Held In Iframes
- How To Scrape Pages With Too Many Steps To Get To Data
- How To Scrape Lazy Loading Sites
How To Scrape Paginated Pages
For beginners or individuals without much web scraping experience, pagination is one of the most common reasons why web scraping can fail. Individuals see thousands of data-rich entries on a site they wish to scrape and don’t consider how they can get their scraper to traverse through these pages.
This is partially because in many roll your own or low code web scrapers, crawling or page interaction isn’t built-in functionality.
Solution One: Visit Each Page Separately
The easiest form of pagination to figure out involves pagination navigation that lets you skip all the way to the last page of pagination. In this case look for the pattern that’s likely in the URL in a format similar to following:
https://www.sitetoscrape.com/category/name?p=8If you aren’t using a scraper that enables you to interact with the page (and click through the pagination links) you can come up with a list where you’ve changed the pagination page value and individually scrape the pages. For the above pages, that would look something like
https://www.sitetoscrape.com/category/name?p=1
https://www.sitetoscrape.com/category/name?p=2
https://www.sitetoscrape.com/category/name?p=3
...If there are many pagination pages, you’ll likely want to generate these values. This can be done by looping programmatically or if you’re using a point and click low-code scraper, by concatenating the values in a spreadsheet.
Solution Two: Webdrivers
If you’re using a roll your own extraction framework like Selenium, the use of the webdriver module allows you to control a browser programmatically. Though this option requires some configuration and will vary by page, an example of how one would use Selenium’s webdriver to click a button titled “next” could look like the code below.
driver.find_element_by_xpath("//a[contains(text(),'Next')]").click()
As you can imagine, this particular route will only work on some sites. And will rely on pages remaining the same. But many web extraction programs do utilize this route.
This route also relies on handling the looping through a range of pages. Best case scenario, there is a button that takes you to the final pagination page. Alternatively, when there are no more “next” buttons, the extraction could end.
Solution Three: Apply Extraction Through a Crawler
Alternatively, you can use a web crawler that applies web extraction to each page it crawls through. Diffbot’s Crawlbot product is one solution. In this case, a user could control which pages they want crawled by a number or routes including the crawl pattern, processing pattern, regular expressions or the max hops fields.
In the case above an individual could specify a seed url of the following
https://www.sitetoscrape.com/categoryAnd then only crawl or process pages that are part of the pagination by specifying a crawling or processing pattern of the following.
category?p=To visit, say each product page listed on each paginated category page, one would likely also look to the URL structure of these pages and add to the crawling or processing patterns. This could be all urls that contain a string like
category/p/After starting your crawl every page that can be reached by a link from your seed url (and ensuing pages) and that meets your crawling and processing patterns will automatically have an extraction protocol applied to it.
How To Scrape Behind Logged In Pages
A great deal of our most valuable online data is housed behind logins. Whether this is an internal data store, or your CRM, logged in pages can provide many difficulties to roll your own or point and click scraping tools.
Option One: Pass Data To A Login Screen
If you want to actually mimic the process of logging into a page with a scraper, you’ll need to utilize a web driver-powered scraper or to find a login endpoint you can pass a username and password payload.
This can work if there is a login endpoint that doesn’t require additional validation. But if there’s one component of a site built to keep out automated traffic the most, it’s form submissions. Hit just one captcha with an unsophisticated scraper and your crawl is over before it begins.
Option Two: Use Crawlbot’s Cookie Parameter
You can enjoy robust out-of-the-box scraping of many common page types that are behind logins using Crawlbot’s cookie parameter with an Automatic Extraction API. If you need an unusual or particular data field returned, this parameter is also available in the Custom Extraction API, which enables you to choose precisely which fields you want returned.
The steps here involve heading to your login guarded page. After you log in look in your web dev inspector and search through your network tab and locate a file containing your login cookies. Simply paste the entirity of your login cookies into your Custom API or Crawlbot set up and you’re ready to go!
How To Scrape Pages With Dynamically Created Class Names
There are a number of reasons why sites end up with dynamically created class names. They’re especially common on
- sites that utilize visual editors
- sites made with React
- sites compiled from Java
- sites that use Javascript to dynamically add css classes
- sites built to deter programmatic consumption of their content
These are class names that can look like the following, and compared to human-generated class names can seem to have no rhyme or reason.
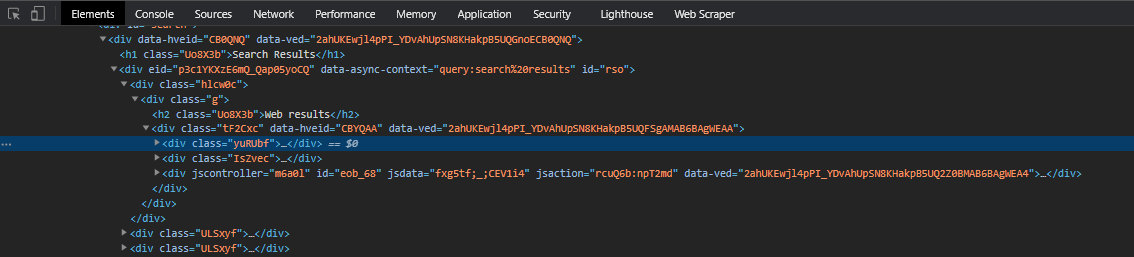
When rolling your own scraper, these classes introduce a whole new level of potential for errors. These classes may change from page to page. They may be applied based on some sort of authentication of the user on the page. They may change from day to day. And they’re simply easy to mistype if you need to specify rules for what your scraper will return. Below are some options for dealing with this pesky layout.
Option One: Use CSS Selectors
You don’t have to precisely match a CSS class to get what you want with a CSS selector. Taking note of any html attribute attached to the node containing data you’re interested in works. The syntax for this type of CSS selector follows the following form.
element[attribute=value]Additionally if you can find a pattern in the class or id you can use “begins with, “ends with” and “contains” selections. These follow the following formats.
div[class^="beginsWith"]
div[class$="endsWith"]
div[class*="containsThis"]Option Two: Rely On Hierarchy Depth
If you’re using Javascript you can utilize XPath selectors through the document.evaluate object. Additionally, web scraping libraries like Scrapy come with a number of functions built on top of XPath.
XPath works similarly to CSS in which you select a element on the DOM and work your way towards specificity. But XPath also let’s you specify which objects you want returned based on the index of an entity. For example, if you’re dealing with oddly arranged or counterintuitive CSS classes, you can rather start with a common element and work your way down.
In the below example we’re selecting each first button element that’s inside of a div and inside of the body element if it doesn’t start with the text “submit.”
//body/div/button[0][not(starts-with(text(),"Submit"))]Some additional XPath capacities that can be handy include returning all of a given type of element or a specific range. Additionally CSS pseudo elements can be chained with all of the above features. For example, you could select inner text of a title in the following way.
.css('title::text').get()Option Three: Return A Wider Set of Nodes And Parse On Your End
Depending on your end goal, this option can add many steps to your web data extraction. Though there may be cases in which selecting the entirety of the HTML body, or main, or all of one selector type could be useful even if it turns up a great deal of extraneous data. While this process can save a deal of time on the extraction front when compared to a nuanced rule-based scraper, you’ll likely be adding a great deal more work in wrangling once you’ve received the data.
Option Four: Rely On Computer Vision
Believe it or not, there are ways to extract important data from pages without specifying any rules.
Diffbot’s Automatic Extraction APIs are example of ruleless, AI-enabled extraction. Using machine learning and computer vision, we’ve built out web extractors for most common page types that actually render and view each page like a person. And then pull out the details surrounded by context clues that they’re important.
For example, if our Automatic Extraction API determines a page is a product page, it may look for availability, price, sale price, reviews, an image, and so forth. If our Automatic Extraction API determines a page is an article, it may seek out comments, an author, sentiment, topics, and so forth.
One additional perk of going “ruleless” with your web data extraction is that for common page types, all commonly valuable field types are pretrained. This means there’s no need to set up a host of custom extraction rules for every new site.
Pro Tip: See if Automatic Extraction API works to extract a page of your choice in our test drive.
How To Scrape Content Held In Iframes
This is a common question that tends to stump individuals who have tried to select an element inside of an Iframe with a css or Xpath selector as they would for other elements on the page. Depending on what the Iframe is rendering, this won’t work. Luckily there are a number of ways to work around Iframes causing your web extraction issues.
Option One: Use a Visual Web Extraction Editor
Some visual web extractors rely on pixel coordinates when a CSS selector fails them. These point and click extractors such as WebPlotDigitizer often take a range of user provided cues, such as the color of the foreground and background of what they should be selecting, or prompt a user to draw a rectangle around the area they want extracted. This can work, though relies heavily on the pattern matching abilities of the software if you want multiple values returned. Additionally, some web extraction rendering sees pages differently from typical user driven web browsers, leading to more potential pitfalls.
Option Two: Follow The IFrame Link
If you’re extracting from a rendered browser you can interact with (through a webdriver, or point and click web data extraction method), you can simply follow the link in the Iframe tag to load the subpage. On the page being loaded inside of the iframe you’ll be able to see and interact with the html nodes that comprise the Iframe.
One downside to this method is that the src of the Iframe isn’t a link. So crawlers will need to have Iframe source links passed as a seed url to start from. Additionally, if you want to extract details from the page containing the Iframe, and the Iframe source, you’ll need to set up custom extraction rules for both pages if you’re using rule-based extraction.
Option Three: Rely On Computer Vision
Yet again, computer vision mimics human’s ability to see information and extract it — whether it’s in an iframe or not. Computer vision-based scrapers like Diffbot’s Automatic Extraction APIs don’t need to rely on precisely matching css class names to extract data. They just need to see it.
Don’t believe me? I’ve thrown an Iframe linking to a product page into this fiddle. If you place the fiddle link containing the iframe of a product page into the Automatic Extraction API Test Drive, you’ll see a range of product fields returned (with no rules!). Even though a fiddle is not a commonly scraped page type, and 3/4th of the rendered page isn’t a product page, the Automatic Extraction API detects the visual characteristics of a product page and determines the right fields to return.
How To Scrape Pages With Too Many Steps To Get To Data
Some web pages require numerous interactions to get to the data you would like to extract. Recording interaction steps is highly error prone as it relies not only on elements on page not changing, but relies on timing of loaded elements which may not be the same in a web driver or automated renderer as on your screen. Additionally, traversing a site too repetitively or at too high of a speed can get your IP flagged. There are a few routes here, but pages with many steps between site entrance and the data you want are tough!
Option One: Complicated Web Driver Maneuvers
This is the most error prone option. But through web driver or a handful of point and click visual web scrapers you can record a set of actions to take before extracting data. You’ll want to allow ample time for any interactivity and page changes to register in the event load times vary. You’ll also want to ensure that interactivity occurs in a similar manner to a human-driven browser in your web driver or scraping service. Depending on which web driver or service you’re using, Javascript as well as page styling can load in different ways, obscuring your path towards the data you want.
Option Two: Find The Underlying Data
In this case, a valid argument can be made for trying to circumvent a scrape by looking for an underlying data file that powers the visual site. There a number of ways to do this. But if the site doesn’t have an API one of the best ways to find the underlying data is to look in your browser’s inspector under the network tab. This may point you to a csv or JSON file that’s providing the data for the front end. A simple get request to each page you were going to programmatically interact with can alleviate a great deal of headache.
Option Three: Rely On A Crawler To Reach Hard-To-Find On-Site Locations
There are two components to whether you can grab all of the initially hidden data on a page. First is whether you’re using a scraper that looks for hidden fields. Secondly, if interacting with the page changes the URL, a crawler can effectively traverse to the hidden areas of a site.
Diffbot’s Automatic Extraction APIs are built to extract fields that may not be immediately visible to a human site visitor. Additionally, Crawlbot can visit millions of URLs URL permutations a day. If an Automatic Extraction API isn’t doing the trick, check out our Custom Extraction API which enables you to specify custom fields to be returned and can also be paired with Crawlbot.
How To Scrape Lazy Loading Sites
Many of the most data abundant sites use lazy loading, whether on individual posts in the case of images or other resources, or in a nav page such as a feed.
Option One: Determine How Lazy Loaded Blocks Are Loaded
Scroll down the page you would like to scrape as lazy loading occurs with your web dev console open. See if whatever is being lazy loaded is loaded. Two of the most common methods include an Ajax call or URL parameters. You may be able to factor the URLs that are called to or URLs with parameters into your scraper to bypass lazy loading altogether.
If you can discern a pattern in the URLs providing lazy loading components, passing this pattern to a crawler can extract from exponentially more pages than most web scrapers that rely on interacting with the browser.
Option Two: Utilize a Scraper That Enables Javascript Evaluation
For this, you’ll need to bypass scraping options that use http. A handful of roll your own headless scrapers allow JavaScript evaluation including Dryscrape and PhantomJS.
If you’re looking to crawl through many pages that require dealing with lazy loading, you may want to try out the X-Eval functionality built into Diffbot’s Custom Extraction API. This functionality allows you to piggyback on Crawlbot to apply Javascript to pages the crawler visits.
You must be logged in to post a comment.