
EMNLP 2019 paper, dataset, leaderboard and code
Knowledge bases (also known as knowledge graphs or ontologies) are valuable resources for developing intelligence applications, including search, question answering, and recommendation systems. However, high-quality knowledge bases still mostly rely on structured data curated by humans. Such reliance on human curation is a major obstacle to the creation of comprehensive, always-up-to-date knowledge bases such as the Diffbot Knowledge Graph.
The problem of automatically augmenting a knowledge base with facts expressed in natural language is known as Knowledge Base Population (KBP). This problem has been extensively studied in the last couple of decades; however, progress has been slow in part because of the lack of benchmark datasets.
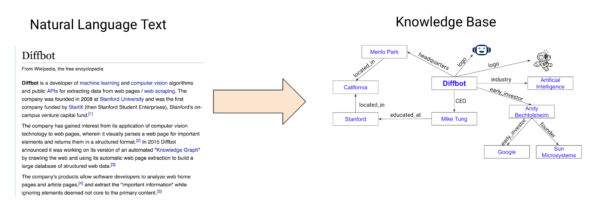
KnowledgeNet is a benchmark dataset for populating Wikidata with facts expressed in natural language on the web. Facts are of the form (subject; property; object), where subject and object are linked to Wikidata. For instance, the dataset contains text expressing the fact (Gennaro Basile; RESIDENCE; Moravia), in the passage:
“Gennaro Basile was an Italian painter, born in Naples but active in the German-speaking countries. He settled at Brunn, in Moravia, and lived about 1756…”
KBP has been mainly evaluated via annual contests promoted by TAC. TAC evaluations are performed manually and are hard to reproduce for new systems. Unlike TAC, KnowledgeNet employs an automated and reproducible way to evaluate KBP systems at any time, rather than once a year. We hope a faster evaluation cycle will accelerate the rate of improvement for KBP.
Please refer to our EMNLP 2019 Paper for details on KnowlegeNet, but here are some takeaways:
- State-of-the-art models (using BERT) are far from achieving human performance (0.504 vs 0.822).
- The traditional pipeline approach for this problem is severely limited by error propagation.
- KnowledgeNet enables the development of end-to-end systems, which are a promising solution for addressing error propagation.
You must be logged in to post a comment.