Our mission at Diffbot is to build the world’s first comprehensive map of human knowledge, which we call the Diffbot Knowledge Graph. We believe that the only approach that can scale and make use of all of human knowledge is an autonomous system that can read and understand all of the documents on the public web.
However, as a small startup, we couldn’t crawl the web on day one. Crawling the web is capital intensive stuff, and many a well-funded startup and large company have gone bust trying to do so. Many of those startups in the late-2000s all raised large amounts of money with no more than an idea and a team to try to build a better Google. However they were never able to build technology that is 10X better before resources ran out. Even Yahoo eventually got out of the web crawling business, effectively outsourcing their crawl to Bing. Bing was spending upwards of $1B per quarter to maintain a fast-follower position.
As a bootstrapped startup starting out at this time, we didn’t have the resources to crawl the whole web nor were we willing to burn a large amount of investors’ money before proving the technology to ourselves.
So, we just decided to start developing the technology anyways, but without crawling the web.
We started perfecting the technology to automatically render and extract structured data from a single page, starting with article pages, and moving on to all the major kinds of pages on the web. We launched this as a paid API on Hacker News for developers, which meant that the only way we would survive was if the technology provided something of value that was better than what could be produced in-house or by off-the-shelf solutions. For many kinds of web applications automatically extracting structure from arbitrary URLs works 10X better compared to the approach of manually creating scraping rules for each site and maintaining these rulesets. Diffbot quickly powered apps like AOL, Instapaper, Snapchat, DuckDuckGo, and Bing, who used Diffbot to turn their URLs into structured information about articles, products, images, and discussion entities.
This niche market (the set of software developers that have a bunch of URLs to analyze) provided us a proving grounds for our technology and allowed us to build a profitable company around advancing the state-of-the-art in automated information extraction.
Our next big break came when we met Matt Wells, the founder of the Gigablast search engine, who we hired as our VP of Search. Matt had competed against Google in the first search wars in the mid-2000s (remember when there were multiple search engines?), had achieved a comparably-sized web index, with real-time search, with a much smaller team and hardware infrastructure. His team had written over half a million lines of C++ code to work out many of the edge-cases required to crawl the 99.999% of the web. Fortunately for us, this meant that we did not have to expend significant resources in learning how to operate a production crawl of the web, and could focus on the task of making meaning out of the web pages.
We integrated the Gigablast technology into Diffbot, essentially adding a highly optimized web rendering engine and our automatic classification and extraction technology to Gigablast’s spidering, storage, search, and indexing technology. We productized this as a product called Crawlbot, which allowed our customers to create their own custom crawls of sites, by providing a set of domains to crawl. Crawlbot worked as a cloud-managed search engine, crawling entire domains, feeding the urls into our automatic analysis technology, and returning entired structured databases.
Crawlbot allowed us to grow the market a bit beyond an individual developer tool to businesses that were interested in market intelligence, whether about products, news aggregation, online discussion, or their own properties. Rather than passing in individual URLs, Crawlbot enabled our customers to ask questions like “let me know about all price changes across Target, Macys, Jcrew, GAP, and 100 other retailers” or “let me build a news aggregator for my industry vertical”. We quickly attracted customers like Amazon, Walmart, Yandex, and major market news aggregators.
In the course of offering both the Extraction APIs and Crawlbot, our machine learning algorithms analyzed over 1 Billion URLs each month, and we used the fraction of a penny we earned on each of these calls to build a top-tier research team to improve the accuracy of these machine learning models. Another side-effect of this business model is that after 50 months, we had processed 50 billion URLs (and since our customers pay for our analysis of each URL, they are incentivized to send to us the most useful URLs on the web to process).
50 billion URLs is pretty close to the size of a decent crawl of the web (at least the valuable part of the web), and so we had confidence at this point that our technology could scale, both in terms of computational efficiency, as well as accuracy of the machine learning, as required by our demanding business customers. Because we had paid revenue from leading tech companies, we were confident that our technology surpassed what could be built in-house by their engineers. We had achieved many firsts: doing a full rendering at web scale and running sophisticated multi-lingual natural language processing and computer vision algorithms at web scale. So at this point, we started our own crawl of the web to fill in the gaps.
Our goal was to allow you to query for structured entities found anywhere across the web, but had to account for the fact that an entity (e.g. a person or a product) could appear on many pages on the web, and each appearance could contain differing sets of information with varying degrees of freshness. We had to solve the problem of entity resolution, which we call record linking, and resolving conflicts in the facts about the entity from different sources, which we call knowledge fusion. With these machine learning components in place, we were able to build a consistent universal knowledge graph, generated from an autonomous system from the whole web, another first. We launched the Knowledge Graph last year.
So in short, here is our roadmap so far:
- Build a service that analyzes URLs using machine learning and returns structured JSON
- Use the revenue and learnings from that to build a service on top of that to crawl entire domains and return structured databases
- Use the revenue and learnings from that to build a service that allows you to query the whole web like a database and return entities
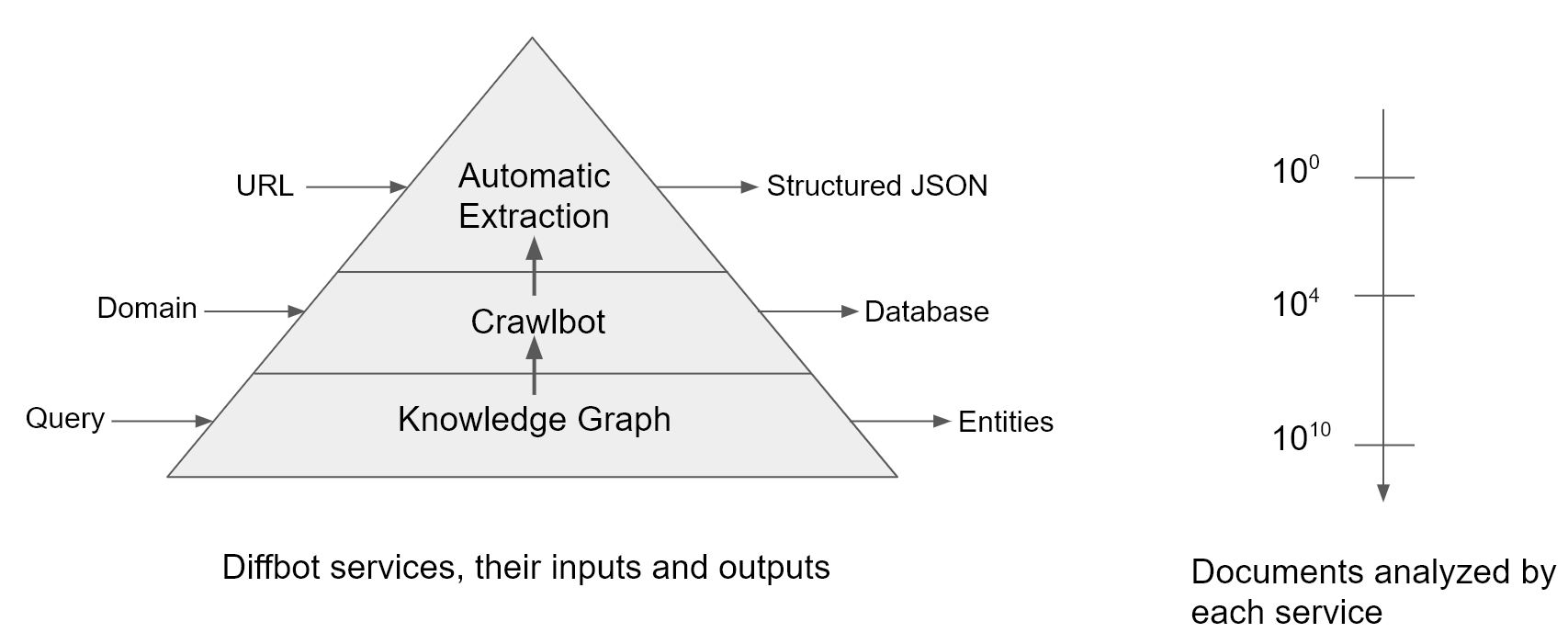
While the Extraction APIs and Crawlbot served a very Silicon-valley centric developer audience, due to its requirement of passing in individual urls or domains, the Knowledge Graph serves the much larger market of information professionals with business questions. This includes the market of business analysts, market researchers, salespersons, recruiters, and data scientists, a much larger segment of the population as compared to software developers.
As long as a question can be formed as a precise statement (using the Diffbot query language) it be answered by the Diffbot Knowledge Graph, and all of the entities and facts that match the query can be returned no matter where they originally appeared on the web.
Knowledge workers rely on the quality of information for their day-to-day work. They demand ever-improving accuracy, freshness, comprehensiveness, and detail, metrics that are aligned with our mission to build a complete map of human knowledge. We have an opportunity to build the first power tool for searching the web for knowledge professionals, one that is not ad-supported freeware, but where our technical progress is aligned with the values of our customers.
You must be logged in to post a comment.