As enterprise AI use has matured, the flywheel-like nature of organizations who put machine learning and AI at the center of their work has emerged.
In engineering, a flywheel is a device that is energy-intensive to get moving. Simultaneously, flywheels are exceedingly good at conserving rotational energy once they have started. And flywheels can continue to move with very little relative energy input. Figuratively, flywheels are “inertia machines” built of processes that feed off of one another and can practically run themselves.
AI adoption has historically been resource intensive as well. Specialized hardware, huge amounts of data not to mention the cost of machine learning talent to implement AI processes all contribute.
With this said, organizations who can effectively harness AI are upending entire industries. Many of these organizations help to promote entire ecosystems of AI use, reusability, and proliferation.
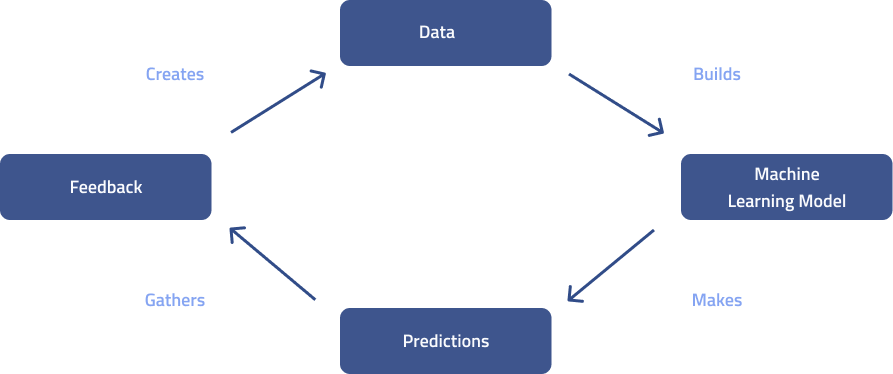
Above we have one version of an AI flywheel, in which organizations (and even entire communities) can continue to benefit from the initial output of machine learning-enabled processes to build less-and-less resource intensive processes. Organizations that can use feedback to generate more data for machine learning to generate more predictions for more feedback can enter into this ideal state.
Where do you store data for learning?
One important consideration involves discerning the best method for storing machine learning input and output. Many organizations utilize knowledge graphs for both the input and output of machine learning processes.
Why are knowledge graphs a “no brainer” for machine learning purposes? For several reasons including:
- Knowledge graphs have flexible taxonomies that can adapt to new fact types over time (or as they’re discovered by ML)
- The flexible taxonomy of knowledge graphs makes them great for structuring valuable unstructured data
- Knowledge graphs are centered around relationships between entities, a core output of many ML classification tasks
- Knowledge graphs are human readable, and are structured around the things humans and organizations care about
- Knowledge graphs can be built with data provenance, transparency, and explainability in mind
At Diffbot, we’ve created the world’s largest web-sourced Knowledge Graph filled with billions of entities sourced from the public web. We routinely see our Knowledge Graph and AI-enabled web scrapers used for machine learning uses including as a labelled data source as well as the use of the seeding of other knowledge graphs.
The Relationship Between Language and AI Flywheels
While video and audio input for machine learning models is growing, by far the largest source of machine learning training data for most organizations is derived from natural language. Information living in documents and text-based interactions comprises a lion’s share of organization data, but involves a few hurdles before it can be used for successful machine learning exercises.
Natural language processing structures previously unstructured text to make it machine readable. Furthermore, some NLP products provide data in knowledge graph format, allowing for the input of unstructured text corpora directly into what is often the best format for machine learning input and output.
Diffbot’s Natural Language API returns entities, facts, and relationships between entities allowing for the creation of machine learning training data and human readable graph formatting from unstructured text. Additionally, our NL API can determine whether a mentioned entity is already located in the Knowledge Graph, allowing users to use our Knowledge Graph to seed their own graph and add to it using the NL API.
You must be logged in to post a comment.