 The original robots who caught my attention had physical human characteristics, or at least a physically visible presence in three dimensions: C3PO and R2D2 form the perfect duo, one modeled to walk and talk like a bookish human, the other with metallic, baby-like cuteness and it’s own language.
The original robots who caught my attention had physical human characteristics, or at least a physically visible presence in three dimensions: C3PO and R2D2 form the perfect duo, one modeled to walk and talk like a bookish human, the other with metallic, baby-like cuteness and it’s own language.
Both were imagined, but still very tangible. And this imagery held staying power. This is how most of us still think about robots today. Follow the definition of robot and the following phrase surface, “a machine which resembles a human.” A phrase only followed by a description of the types of actions they actually undertake.
Most robots today aren’t in the places we’d think to look based on sci-fi stories or dictionary definitions. Most robots come in two types: they’re sidekicks for desktop and server activities at work, or robots that scour the internet to tag and index web content.
All-in-all robots are typically still digital. Put another way, digital robots have come of age much faster than their mechanical cousins.
The first type of digital robots are better known as Robotics Process Automation, or “RPA.” We’ll also call them “process bots.”
Process bots are a valuable partner for business efficiency. They move data around and through business activities, escalating work items to humans when necessary or when their rules break (incidentally, that’s often). But overall time is saved, and humans avoid some of the more mundane and repetitive business processes.
Where do the process bots focus and excel? A lot of places, and the smoke to their fire is when humans need to perform the mind-numbing shuffle between cut, toggle screens, paste, cut, toggle screens, and paste again – repeatedly. RPA is charged with reducing monotony and increasing speed in repetitive tasks.
I spent years working on business process management and low code solutions for important company workflows. There are primarily three high-level applications for this type of solution:
- Clients build a new application to address monotonous activity
- Clients build an integration between systems to reduce monotony
- Clients use RPA as a lightweight method to scrape data and move it across user interfaces
The debate about which of these three options is best, and when, shapes technology buying and selling approaches across corporate America.
Process bots don’t always win, but win often enough to drive most market vendors to multi-billion dollar valuations and breathless articles in major publications about how they’re changing the world.

Where do these bots excel? Most of us think we know because we use search engines daily, but our experience is recently outdated.
Search bots facilitate the ability for us to query the entire web in various ways: search, classify, and read targeted web pages. Most newly, these bots infer connections between entities from raw unstructured web data.
Some search bots — like Diffbot’s AI web extraction bots — can parse the web into facts and entities
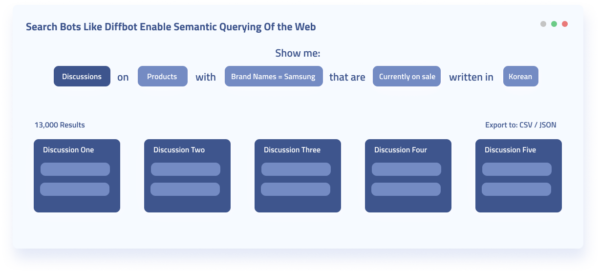
Historically a search engine couldn’t directly answer “how many companies in San Francisco have less than 500 employees and a female CEO?”
They could serve up content they think may answer this question. But for many use cases that’s not reliable, or fast enough. Today, a handful of search bots can answer questions like this directly. In summary, search bots young and old have the charge of bringing visibility and organization to the vast expanse of the web.
Process Bots Vs. Search Bots
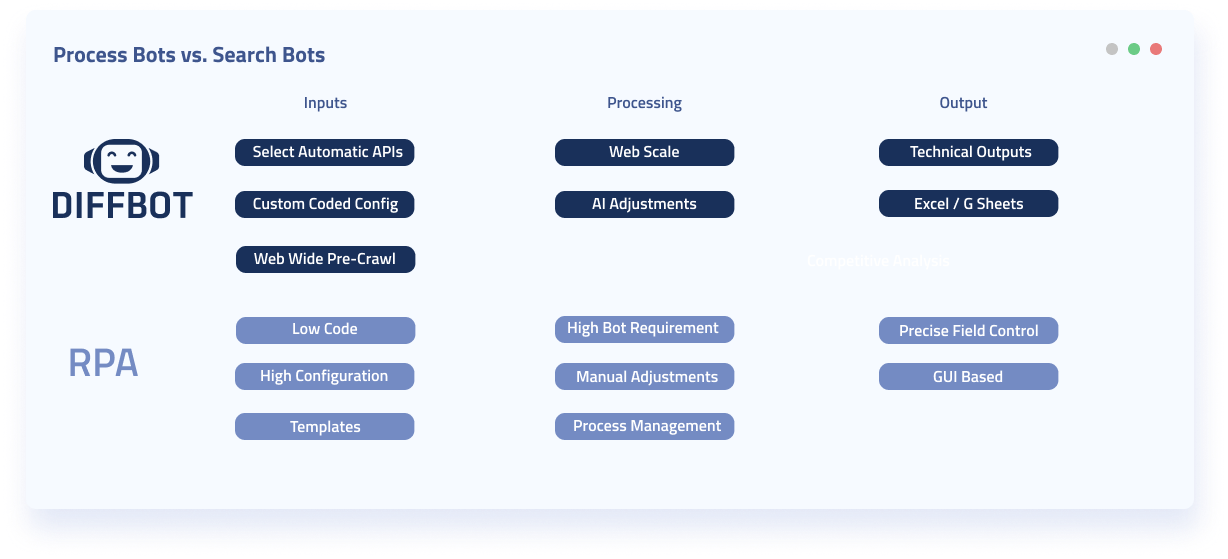
Process Robot Strengths
- Low Code UX
- Precise control of input and output locations via the UX
- Working behind a log-in for business applications
- Passing data along a business process
- Business templates for certain usage patterns (Customer Service; Financial tables, etc.)
Search Robot Strengths
- Scale to Process tens of thousands of pages simultaneously
- Zero configuration and automatic processing for numerous webpage types
- Crawlers adapt automatically as pages change
- Rich custom configuration
- Spider entire sites without even knowing all urls.
- Comprehensive reading of page HTML (Author name; Product UPC)
- Extract sentiment from text automatically
- Extract related Entities from text (Organizations, Locations, People, etc.)
Bots are on the loose. They’re in business applications, and on the web. They’re trained by humans, and by AI. They augment our decision making, process the largest collection of data ever created — the web — and accelerate the monotony of cut and paste.
But which bots are best?
Like everything it depends, but one key distinguishing feature between web and process bots can be shown through a discussion of what contexts we want our bots to work in.
RPA bots were developed in an era of static applications. Spreadsheets needed to be updated from accounting software. Applications held largely the same format for months or years at a time. And the uses of data pushed between applications was well defined and somewhat limited.
Today all of our applications live in the cloud. And data pipelines are highly reliant on unstructured data from the web. Since the advent of RPA, the output of applications we use has become dramatically more dynamic. A key distinguishing feature between search and process bots is seen through the fact that search bots are built to adapt to ever changing web pages. RPA breaks when sites change too much, or when you try out the same routine on different locations in the cloud.
Automation Of Unstructured Web Data
On the unstructured data front, let’s compare an RPA and Diffbot’s Crawlbot. You want to collect data from a home and garden store site. You want to know prices, sale prices, what’s in stock, SKUs, and review data. Everyone’s into gardening in the time of quarantine. (And some people are into crawling gardening sites in the time of quarantine.)
With RPA you have a beautiful, low-code IDE. You select the garden store, choose the category – say, seeds – select elements on the first seed page. This teaches the RPA where to find the import bits. If you need to scroll across pages you’ll likely need to teach the bot to recognize the pagination button.
Then you move on to the fruits page, train the model again, train it on pagination again. Keep in mind many ecommerce sites have hundreds of categories. And you may not want just one garden site. You may want dozens, or hundreds.
And then a garden site changes. Your RPA extractor may still work, or it may break. How many sites worth scraping do you find that aren’t dynamic these days?
Now take an AI-enabled search bot. You enter one site into Diffbot’s Crawlbot, wait several minutes, and thousands of pages are recognized and parsed as product pages. You download the data is JSON or CSV, or you feed an application or dashboard with a selection of the results.
In the event of a particularly complex site, you provide a few custom crawling rules. Perhaps you send along cookie data in Javascript to simulate being logged in. Or perhaps you specify you only want pages crawled with “/product” in the URL.
The core technology behind this use case shows warning signs for RPA bots. Search bots speed read and classify the web on their own!
Automation In Business Applications
In business applications, there’s more hope for process bots. Particularly for non-technical users.
Let’s say you have a customer service application and you want to take updated addresses and paste them into five other internal systems. You log into the IDE, select the address field, and specify that whenever this field is updated, the RPA loads up the other five applications and enters the data there.
It’s fairly easy, assuming none of the pages changes their visual layout (and assuming each application has visual edit functionality). Similar steps could be used to move financial records to other locations.
So how would a search bot do in this case? First off, most search bots are created to scan public and open data. With this said, some can log into applications if they’re on the cloud. Diffbot’s Crawlbot allows technical users to pass cookies to get behind a login. The Crawlbot could then spider all of your applications pages (or just some). And return data in a format consumable for humans or applications. A Zapier hook could send the output data to nearly any application. But the initial need for some technical know-how may still nudge this use case in favor of an RPA (for some users).
Search bots like Crawlbot and Diffbot’s automatic extraction APIs also provide context. They don’t just shuffle bits between applications, but rather pull facts from textual data, assimilating unstructured input into profiles of individuals, organizations, products, and more. The technical aspect is challenging for some. But semantic data offered by some search bots is much more robust than just shuffled bits.
So what is the better choice at this junction? Search bots can do a large portion of what process bots can do. And process bots can do almost anything a search bot can do, but with no “understanding” of what they’re doing or the data they’re handling (and in a way that’s prone to break).
A case can be made for using these tools in tandem. Think of process bots moving boxes and inventory around a warehouse, while search bots scan, tag, and provide contextual data on each inventory item.
But maybe this portends deeper concerns for the core technologies within RPA. The most vibrant applications are now dynamic. The most useful data is contextual and gathered from many sources. The scale of data and data sources doesn’t bode well for tools with much of any manual aspect. ML-aided automation is the new standard, and costs will continually rise for not taking the leap.
I’ve always thought that RPA was a useful technology, an efficient way to train robots to carry the burden of repetitive digital activities. It’s easy enough to train and configure. That was until I joined Diffbot. Our customers simply enter the name of tens, hundreds or even thousands of web domains, and the bots process entire bulk loads of websites! We shift the human thought work to deciding where you send the structured information afterwards, which is increasingly easy as most integration platforms and corporate systems have numerous APIs to ingest structured data. At scale, search bots must be two or three orders of magnitude faster than RPA.
To be fair, RPA vendors are working to incorporate machine learning into their models, but the entire industry was built on users configuring the bots in a low-code IDE for custom workflows. The low-code IDE is powerful, but that’s an interface wrapper that won’t dig a wide moat. Is the need to log in to a business application a unique technology? Architecturally that’s a feature, not a cornerstone.
What’s needed for RPA to read UIs like Search bots? More business process templates, more self-training on how to reach constantly tweaked input and output screens. Machine learning, or flexibility that is seldom robust enough in low code environments.
Redesigning a point and click system into a machine learning application reader is more than cleaning the closet. It’s a front-porch-to-garage, paint-to-foundation, furniture-to-blinds, redesign. It might also require new tenants in charge.
On the other hand, search robots don’t have much interest in cutting, pasting, toggling, or so forth around business applications. But is the future really in speeding up cut and paste?
For now these digital bots perform distinct enough activities that they rarely wind up in the same conversation or article. That has made sense to date: unique buyers and use cases. For me the interest sprang from my shock and disbelief at how far search bots had progressed at reading UIs without the RPA industry or corporate IT groups almost noticing at all. For RPA as a concept – not a technology – to endure, those products will need to look outward at advancement in computer vision, natural language processing and web crawling, at massive scale, much larger than they attempt today. Otherwise it’s possible that large companies are anchoring their architecture around a technology just at the point when it’s nearly outdated.
You must be logged in to post a comment.