At Diffbot, our goal is to build the most accurate, comprehensive, and fresh Knowledge Graph of the public web, and Diffbot researchers advance the state-of-the-art in information extraction and natural language processing techniques.
Outside of our own research, we’re proud to enable others to do new kinds of research in some of the most important topics of our times: like analyzing the spread of online news, misinformation, privacy advice, emerging entities, and Knowledge Graph representations.
As an academic researcher, one of the limiting factors in your work is often access to high-quality accurate training data to study your particular problem. This is where tapping into an external Knowledge Graph API can help you greatly accelerate the boostrapping of your own ML dataset.
Here is a sampling of some of the academic research conducted by others in 2020 that uses Diffbot:
Online Near-Duplicate Detection of News Articles
https://www.aclweb.org/anthology/2020.lrec-1.156/
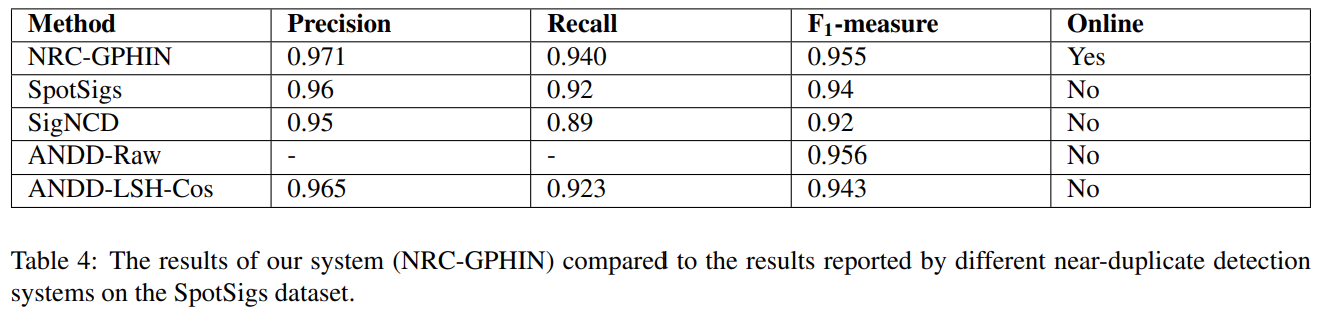
If you’ve ever used Google News or any other news aggregator, you’ve experienced near-duplicate article detection. These are the algorithms that cluster news stories about the same topic or event, so that you don’t see a lot of repetition in your newsfeed. Published in LREC 2020, the authors from the National Research Council of Canada used Diffbot to build a dataset to study this problem and achieve a new state-of-the-art result in news clustering.
CompRes: A Dataset for Narrative Structure in News
https://arxiv.org/abs/2007.04874

A news article is not just a statement of facts (wouldn’t that be great?), but an expression of storytelling that conveys a particular interpretation of events. This narrative bias in the news we consume is something that has been understudied, and the authors use Diffbot to construct CompRes–the first dataset for narrative structure in news media. Published at ACL 2020.
A Comprehensive Quality Evaluation of Security and Privacy Advice on the Web
https://www.usenix.org/system/files/sec20-redmiles.pdf
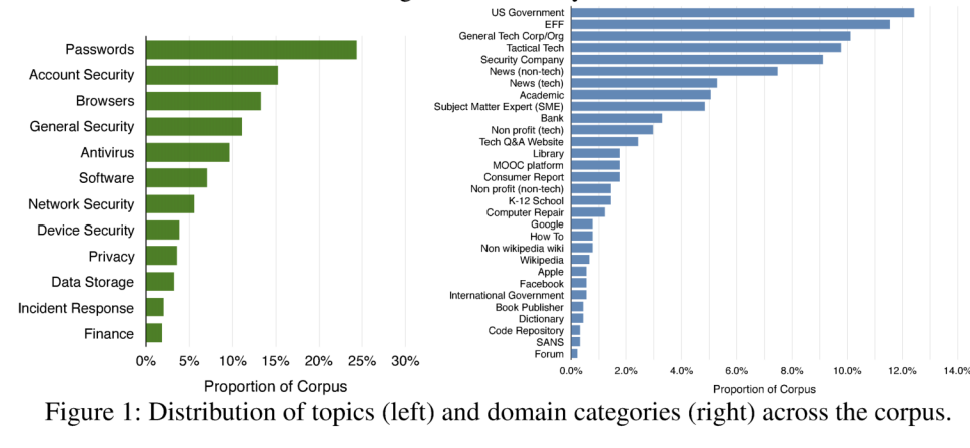
The weakest link in defensive security is often user education, and users learn about best practices for security and privacy from–where else–the internet! Researchers from University of Maryland, UCSD, and Rutgers evaluated 374 pieces of security advice with 1,586 users and 41 professional security experts, studying the quality of the advice found online, as returned by Google and parsed by Diffbot at the 29th USENIX Security Symposium.
Digital Data Sources and Methods for Conservation Culturomics
https://conbio.onlinelibrary.wiley.com/doi/full/10.1111/cobi.13706
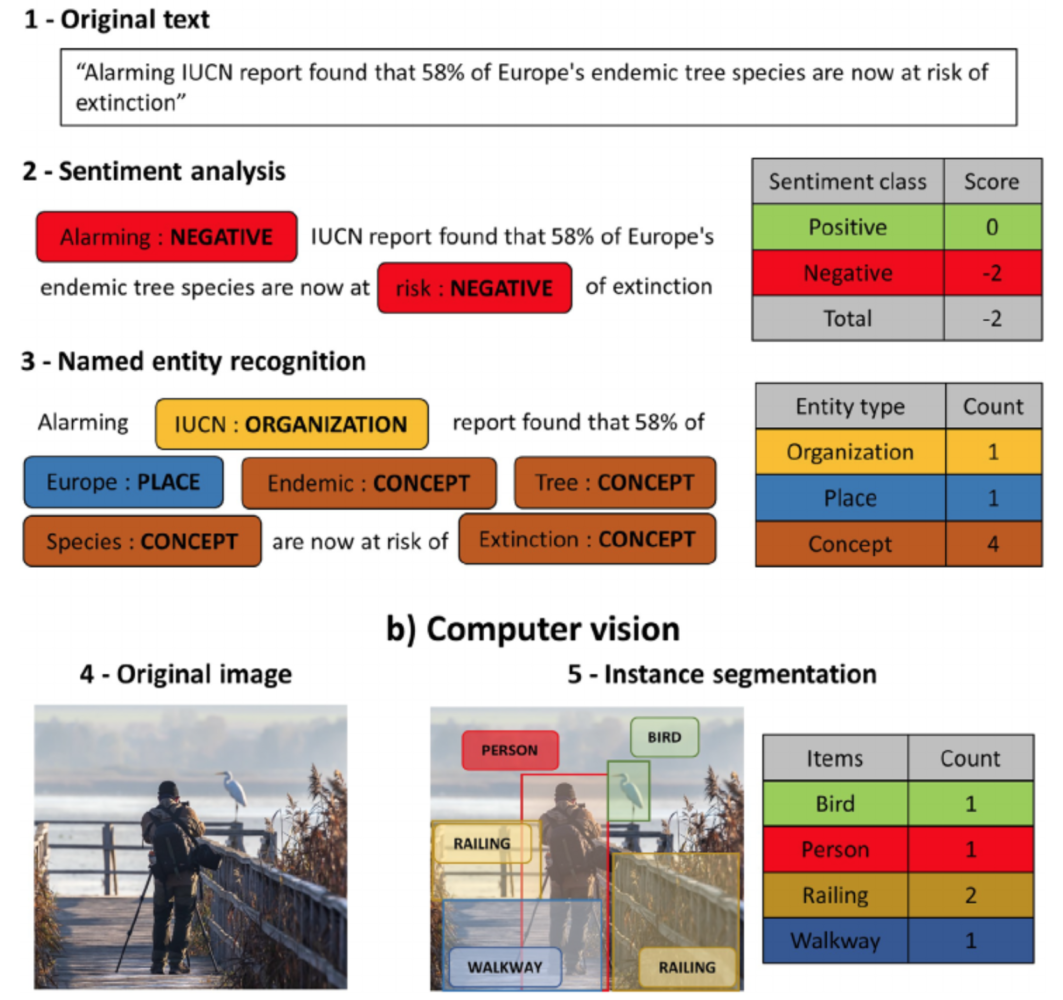
Biodiversity on Earth is rapidly declining due to land use change, climate warming, and pollution. While we can use satellites to measure and locate the effects of these changes on our planet, how do we monitor the human causes of these changes on our planet and other species? A broad consortium of academic researchers and zoological institutes propose a system for monitoring conservation culturonomics based on the Internet. Published in Conservation Biology.
Explainable Link Prediction for Emerging Entities in Knowledge Graphs
https://link.springer.com/chapter/10.1007/978-3-030-62419-4_3
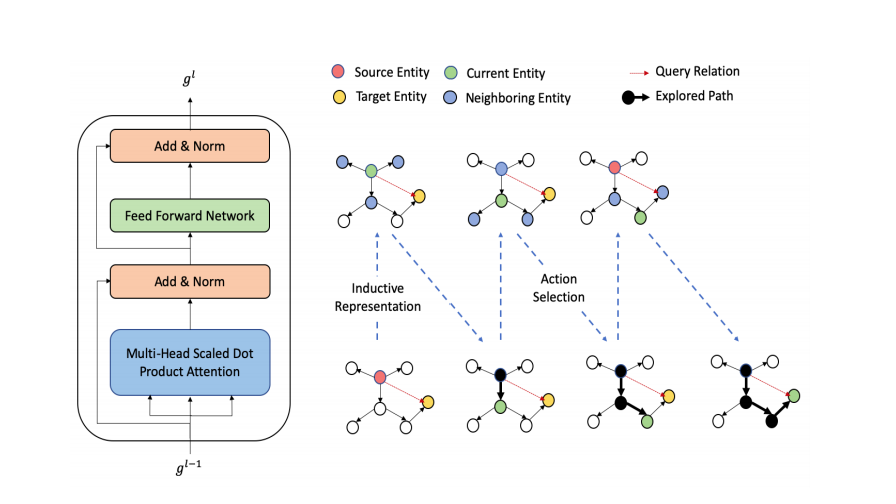
Popular consumer knowledge graph search engines like Google and Siri suffer from the issue of answering questions about emerging entities that don’t have a popular wikipedia page. Bhowmik and Melo propose a new algorithm for inferring properties of previously unseen entities using an inductive representation at the International Semantic Web Conference 2020. Disclaimer: this work was partially supported by Diffbot and Google
Tensor embeddings for Content-based MisInformation Detection with Limited Supervision
https://arxiv.org/pdf/1804.09088.pdf
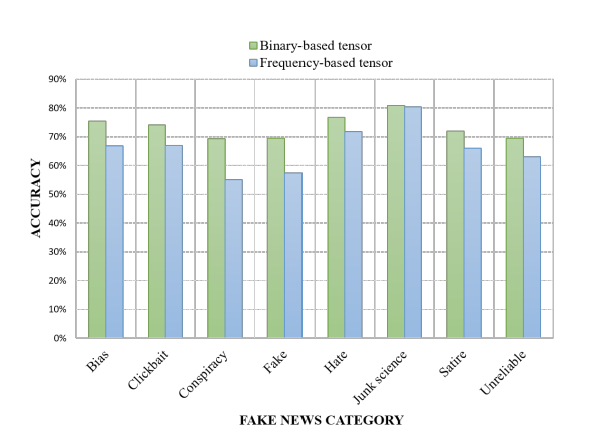
Misinformation is currently a big problem on the internet, however fighting misinformation using large teams of human moderators is expensive and using machine learning require enormous amounts of labeled data that is infeasible to collect comprehensively. Researchers from UC Riverside and Snapchat were able to use Diffbot to automatically collect a dataset of misinformation content categories (bias, clickbait, conspiracy, fake, hate, junk science, rumor, satire) and use a semi-supervised tensor embedding technique to achieve 70.92% classification accuracy only using 2% of the data conventional techniques would use.
You must be logged in to post a comment.