One of the more common uses of Crawlbot and our article extraction API: monitoring news sites to identify the latest articles, and then extracting clean article text (and all other data) automatically. In this post we’ll discuss the most straightforward way to do that.
First, a quick note: this is a difficult task for a few reasons:
- Identifying articles from non-articles is hard! Often articles will be identifiable based on URL patterns, but this is different on each site. Diffbot’s Analyze API makes it easy by automatically identifying articles (and other matching pages) while crawling.
- Sites commonly post new content not only on their home page, but often on sub-section home pages (e.g., not every article from the New York Times appears on the nytimes.com home page)
- New articles often contain links to related articles that may be months or years old.
- An article needs to be extracted in order to validate its date (using our Article API’s date normalization functionality).
Shortcut Answer: If Possible, Use RSS
If the site you’re looking to monitor provides an RSS feed, you may be in the clear. Simply by monitoring this feed and sending new links to our Article API (either directly or via our Bulk Processing Service, which handles tens to millions of URLs asynchronously), you can have a clean feed of the site’s complete content.
Some potential pitfalls of this approach:
- many RSS feeds are incomplete and do not represent an entire site’s content
- RSS feeds may contain extraneous content
- many sites do not offer RSS feeds or update them infrequently
Complete Answer: Use Crawlbot’s Recurring Crawl Functionality
We will use Crawlbot to first spider and index (a portion of) the site, and then Crawlbot’s repeat-crawl functionality to monitor the site regularly in order to identify new articles (and automatically extract clean text from them).
1) Specify Seed URLs, including sub-sections, if desired.
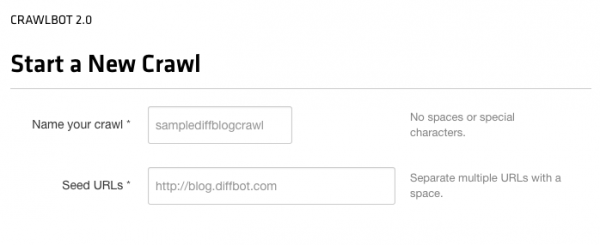
After giving our crawl a name, we’ll enter our seed URL(s). For simple sites (e.g., the Diffblog) we can simply enter a single seed, like blog.diffbot.com. If we want to monitor the main sections of a large news site, for instance, we might enter multiple seeds:
- https://www.samplenews.com
- https://sports.samplenews.com
- https://entertainment.samplenews.com
- https://politics.samplenews.com
- …and so on.
2) Specify the “Max Hops”
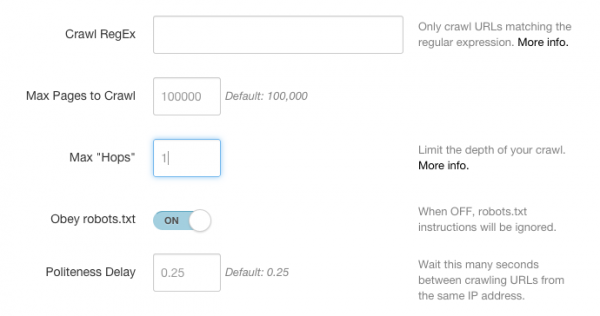
Crawlbot’s maxHops parameter will let us limit our crawl based on link depth from the seed URL(s). For instance, in the following hierarchy:
Seed URL > Pages Linked from Seed URL > Pages Linked from (Pages Linked from Seed URL)
maxHopsof 0: process seed URLs onlymaxHopsof 1: process seed URLs, and pages linked from seed URLsmaxHopsof 2: process pages seed URLs, pages linked from seed URLs, and pages linked from those pages in turn
For processing a news site, typically setting a maxHops of 2 will be sufficient for limiting the depth of your crawl. If you specify all of the sub-sections of your site as multiple seed(s), 1 may be desired.
Why do we want to limit a crawl’s depth? This prevents both over-indexing the site unnecessarily (many news sites have millions of pages of old content that you may not be interested in), and over-processing the site regularly in a hunt for new content.
3) Set Up a Repeating Crawl Schedule
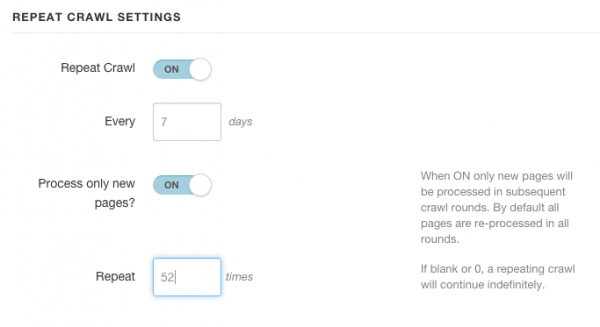
Let’s turn “Repeat Crawl” ON, since we want to repeatedly and automatically monitor the site for new content. Set your repeat schedule based on how frequently the site updates its content. For a major news site you may want to crawl every day (1) or even twice daily (0.5). For a less-frequently-updated blog, crawling weekly (7) may be sufficient.
What you want to consider is what schedule, in conjunction with your maxHops value, will cause you to pick up most/all of the newest content.
Then, make sure “Process only new pages” is ON. This setting ensures that only new URLs — pages that were not present during previous rounds — are processed in any given round.
4) Use the Search API to retrieve content on a regular basis.
Once our crawl is set up, we can make Search API queries at any time to retrieve the clean content in JSON format. Using the date filters (and Diffbot’s automatic visual date extraction and normalization) makes it easy to only get the latest articles. For example:
https://api.diffbot.com/v3/search?token=…&col=samplediffblogcrawl&num=all&query=min:date:2015-01-15
…will retrieve all articles whose date is after January 15, 2015. A breakdown of our call arguments:
token: our Diffbot tokencol: our crawl namenum: the amount of results desired (num=all returns all matching objects)query: the search query, in this case all articles with a minimum date of 2015-01-15
Running this query regularly (and adjusting the date each time) will allow us to easily retrieve all articles written on or after the specified date.
(Note: we can also download the complete crawl data at any time in either JSON or CSV formats, and then simply filter the output by the “date” field. For small sites, this may be preferable. For large content sets, the Search API will be faster.)
You must be logged in to post a comment.