
Machine Learning Loads are Different than Web Loads
One of the lessons I learned early is that scaling a machine learning system is a different undertaking than scaling a database or optimizing the experiences of concurrent users. Thus most of the scalability advice on the web doesn’t apply. This is because the scarce resources in machine learning systems aren’t the I/O devices, but the compute devices: CPU and GPU.
Different, because most machine learning algorithms at their core “learn” by searching through a space of parameters that are comparably smaller than the size of the input data by doing a lot of number crunching. Of course, if you are applying non-parametric learning, you have a data problem in addition to a compute problem.
When rapidly iterating on machine learning algorithm development, using CPU load as a design parameter to accurately predict how many nodes are needed at any given time isn’t always possible. Enter Spot Instances and Auto Scaling.
Spot Instances are ideal for machine learning workloads
Spot Instances were introduced by Amazon in 2009 as a way for Amazon to improve their system capacity optimization by auctioning off portions of the AWS grid that aren’t claimed by on-demand instance customers. Since this unused portion is a varying and transient resource, a spot instance is a lot cheaper than a spec-equivalent on-demand instance. Today, an XL on-demand instance costs $0.66/hr, six times more than the current spot price of $0.11/hr.
| EC2 Spot Instance (c1.xlarge) | $0.11 |
| EC2 On-demand Instance (c1.xlarge) | $0.66 |
| Rackspace 8GB Instance | $0.48 |
| Linode 8GB Instance | $0.22 |
| Google Compute (n1-highcpu-8-d) | $0.74 |
| Microsoft Azure (Large VM) | $0.24 |
Spot instances are much cheaper per CPU hour.
Sidebar: Startups Using Spot Instances Spot Instances have enabled machine learning and similar startups to run CPU intensive jobs that previously would have required access to a datacenter.
- Ooyala: a video analytics startup in Mountain View, uses spot instances to perform video encoding.
- DNANexus: a sequence analysis platform in the cloud, uses spot instances to run its computationally expensive sequence analysis jobs.
- BrowserMob: ran 5,000 Firefox browsers on 2,300 CPU cores in order to load-test an online gaming website.
Auto Scaling was introduced by Amazon in August 2010 at the same time they added CloudWatch (a feature for monitoring cluster health metrics), as a way to take automated actions based on pre-configured policies.
Spot Instances and Auto Scaling go together like marshmallows and hot chocolate; or peanut butter and chocolate; or whatever it is that’s secretly combined to form Nutella. You get my point. The transience of Spot Instances makes them ideal for automated triggers, and adding another bidding option to an automated bidding strategy seems like a no-brainer.
Caveats
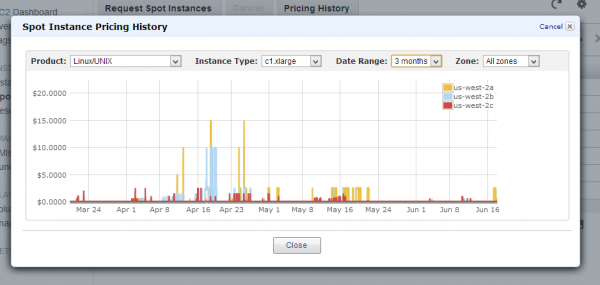
What can go wrong when you combine an automated bidding agent with nodes that can terminate themselves at any time? For starters:
- Historically, the spot price has been very volatile, remaining constant for long periods, punctuated by sharp spikes (see Figure above). These spikes can at times rise higher than the on-demand price of a comparable instance.
- Bugs in code or bad data can errantly activate your trigger, causing your cluster to scale up in a never-ending loop.
- Amazon’s grid can become fully booked with on-demand instances, which forcibly terminates all spot instances.
Despite these apparent gotchas, most of the drawbacks can be eliminated with some basic forethought and care in setup.
In the next post, I’ll go over how to script your way out of these drawbacks, and provide code snippets to show how Diffbot uses Spot Instances and Auto Scaling to rapidly iterate through our machine learning algorithms (and save a buck or two).
Thoughts? Discuss how you do Machine Learning in the Cloud on Hacker News.
You must be logged in to post a comment.