In 2013 we welcomed Matt Wells, founder of Gigablast (and henceforth known as our grand search poobah) aboard to head up our burgeoning crawl and search infrastructure. Since then we’ve released Crawlbot 2.0, our Bulk Service/Bulk API, and our Search API — and are hard at work on more exciting stuff.
Crawlbot 2.0 included a number of ways to control which parts of sites are spidered, both to improve performance and to make sure only specific data is returned in some cases. Here’s a quick overview of the various ways to control Crawlbot.
First, a Terminology Lesson: Crawling vs. Processing
Before we dig in, it’s important to understand two Crawlbot terms:
- Crawling is the spidering of a site for links, and the following of those links to other pages, and so on. This is the definition you probably think of when you think of a web crawler.
- Processing is the handoff of a particular URL to a Diffbot API — e.g., our Article API, Product API, our Analyze API, or even a Custom API — for structured data extraction. This is the unique component that makes Crawlbot, well, Crawlbot.
When controlling Crawlbot you can determine which pages you want to be crawled — spidered for more links — and which of those you want processed — extracted and indexed in clean, structured JSON.
Crawl Patterns

Let’s assume we’re crawling a large shopping site — www.diffbotshopping.com — for baby products, but don’t want to waste time crawling through the irrelevant (to us) parts of the site. The site keeps its baby products in two categories — “Baby” and “Infant” — which are found within the www.diffbotshopping.com/baby/ and the www.diffbotshopping.com/infant sections of the site.
If we want to narrow our crawl to only these sections, we can enter crawl patterns to fence in our crawler. Only pages whose URLs contain an exact match to one or more crawl patterns will be crawled.

I’ve also added a pattern of /special/baby-clothes to crawl a special sale section using a slightly different URL scheme.
With the above crawl patterns, here’s how our crawler would handle some sample pages:
| https://www.diffbotshopping.com/autos | Not crawled |
| https://www.diffbotshopping.com/baby/page/1 | Crawled |
| https://www.diffbotshopping.com/infant/item/1712371/related | Crawled |
| https://www.diffbotshopping.com/home/specials/onesies | Not crawled |
| https://www.diffbotshopping.com/ice-ice/baby/page/1 | Not crawled |
| https://blog.diffbotshopping.com/baby-gear-for-2015 | Crawled |
| https://www.diffbotshopping.com/home/special/baby-clothes/ad.html | Crawled |
Negative Crawl Patterns
If you like to work in reverse, you can also list negative crawl patterns by adding an exclamation-point in front of a pattern. For instance, in the below crawl pattern, I have indicated I do not want the Diffbot Shopping Blog, or the Electronics or Sporting Goods categories to be crawled. All other pages of the site will be crawled.

Crawl RegEx
Sometimes a crawl pattern isn’t specific enough. In this case you can write a Crawl RegEx (regular expression) to much more concretely fence in your Crawlbot spiders.
Note: if you enter both a Crawl Pattern and a Crawl RegEx, the Crawl RegEx will be used.
For instance, if you only want to crawl the first 100 pages of the “Sports” category of www.diffbotshopping.com, and want to avoid crawling pages like www.diffbotshopping.com/sport/specials and www.diffbotshopping.com/sport/featured, you could write a Crawl RegEx:

Max “Hops”
The Max “Hops” value allows you to specify the depth of your crawl from your seed URLs. A value of “0” will limit crawling only to your seed URLs — effectively no crawling at all. A maxHops value of 1 will crawl only pages whose links appear on the seed URLs. A value of “2” will crawl all of the pages linked from those pages, and so on.
If in our case we didn’t want a comprehensive crawl of www.diffbotshopping.com, but instead wanted a crawl a broad subset of the site, we could set a maxHops value of “2” or “3” or “4” to only crawl to a fixed depth of the site, rather than crawling all the way into the recesses of each category. This is also useful for crawling topical news sites regularly for only the latest articles.
(Max) Pages to Crawl
This one is easy: it’s a hard cut-off as soon as the number of pages crawled (spidered for links) reaches the “Max to Crawl” value. All processing and crawling will stop when this is reached.
Note that this is independent of pages processed by a Diffbot API, so setting a crawling maximum may result in fewer pages processed than you intend, depending on which processing filters you have in place.
Robots.txt and Crawlbot Politeness

By default Crawlbot adheres to sites’ robots.txt instructions. If in rare cases you wish to ignore these (perhaps because you are crawling a partner’s site but their IT responsiveness is less than adequate), you may do so on a crawl-specific basis by choosing to ignore a site’s robots.txt.
Crawlbot also adheres to a default “politeness” setting, and will wait a quarter-of-a-second between crawling pages from the same IP address. If you wish to override this you may also do so on a crawl-specific basis, but be cautious: depending on Crawlbot volume many spiders may be in action at any given time, and a very low crawl delay can overwhelm sites you crawl.
Page Processing Limits

By default Crawlbot will attempt to process every URL it encounters. When processing via the Analyze API this is an efficient way to automatically structure an entire site — Analyze will determine the “page type” of each URL, and extract the full details from articles, products, discussion threads, images, and other supported page types.
If you wish to process only a subset of pages, use a processing limit.
Processing Patterns and RegExes
Processing Patterns and RegExes work the same way as Crawl Patterns or Crawl RegExes, except they dictate which pages should be processed.
If you enter processing patterns, any URL encountered that matches one or more of the patterns will be processed.
For instance, in our shopping site example: if all we care about is processing products via the Product API, we can enter a processing pattern that matches only the URLs of product pages, e.g. https://www.diffbotshopping.com/sports/view?template=2&itemId=192371
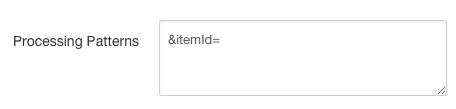
The Processing RegEx is an alternative for when you want to strictly specify the full URL expression you want matched. Again, as with the Crawl RegEx and Pattern, if both a Processing Pattern and RegEx are entered, the RegEx will be used.
HTML Processing Pattern
The HTML Processing Pattern allows you to process pages based on a match to markup in the raw source of a page’s HTML. This helps in those cases where URLs aren’t distinct enough to narrow your processing.
Any unique string of markup is a possible candidate for an HTML Processing Pattern. For example, product pages may uniquely have the markup string <div id='actualPrice'> or input type='button' id='addToCart' or even <title>Diffbot Shopping Product View:. Any unique markup string is a candidate.
If an HTML Processing Pattern is entered, only pages containing at least one exact HTML string will be processed.
(Max) Pages to Process
Similar to Pages to Crawl, this dictates when a job should be finished based on the number of pages processed. As soon as the entered value is reached, all crawling and processing will cease and your crawl job or round will be finished.
Further Reading…
The web is increasingly complex, and crawling sites can certainly feel even more complicated. We’re working to make Crawlbot the easiest way to crawl and extract data from any site on the web. Check out the following for more info:
- Diffbot Support at https://support.diffbot.com
- Crawlbot Overview and API Documentation at https://www.diffbot.com/dev/docs
- Sign up for a Diffbot token at https://www.diffbot.com/pricing
You must be logged in to post a comment.