Eight years ago, Diffbot revolutionized web data extraction with AI data extractors (AI:X). Now, Diffbot is set to disrupt how businesses interact with data from the web again with the all-new DKG (Diffbot Knowledge Graph).
“What we’ve built is the first Knowledge Graph that organizations can use to access the full breadth of information contained on the Web. Unlocking that data and giving organizations instant access to those deep connections completely changes knowledge-based work as we know it.”
– Mike Tung, founder and CEO of Diffbot.
Unlocking knowledge from the Web
Ever wished there was a search engine that gave you answers to your questions with data, rather than a list of links to URLs?
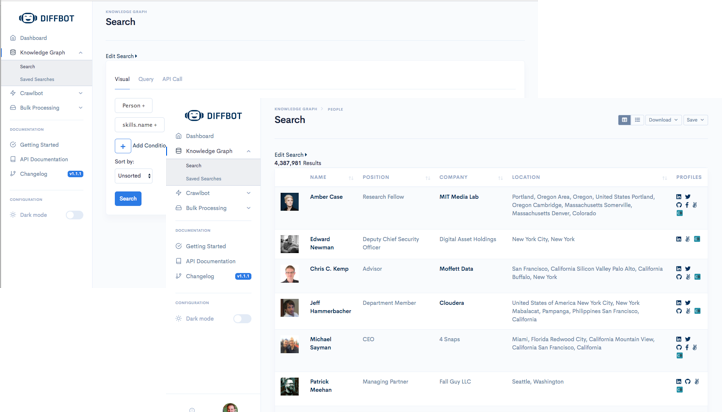
Using our trademark combination of machine learning and computer vision the DKG is curated by AI and built for enterprize, unlocking the entire Web as a source of searchable data. The DKG is a graph database of over 10 billion connected entities (people, companies, products, articles, and discussions) covering over 1+ trillion facts!
In contrast to other solutions marketed as Knowledge Graphs, the DKG is:
Fully autonomous and curated using Artificial Intelligence, unlike other knowledge graphs which are only partially autonomous and largely curated through manual labor.
Built specifically to provide knowledge as the end product, paid for and owned by the customer. No other company makes this available to their customers, as other knowledge graphs have been built to support ad-based search engine business models.
Web-wide, regardless of originating language. Diffbot technology can extract, understand, and make searchable any information in French, Chinese, and Cyrillic just as easily as in English.
Constantly rebuilt, from scratch, which is critical to the business value of the DKG. This rebuilding process ensures that DKG data is fresh, accurate, and comprehensive.
Why?
A Web-wide, comprehensive, and interconnected knowledge graph has the power to transform how enterprises do business. In our vision of the future, human beings won’t spend time sifting through mountains of data trying to determine what’s true. AI is so much better at doing that.
Right now, 30 percent of a knowledge worker’s job is data gathering. There’s a big opportunity in the market for a horizontal knowledge graph — a database of information about people, businesses, and things. Other knowledge graphs are little more than restructured Wikipedia facts with the simplest, most narrow connections drawn between. We knew we could do better. So we’re building the first comprehensive map of human knowledge by analyzing every page on the Internet.
Knowledge is needed for AI
The other reason we’re building the DKG is to enable the next generation of AI to understand the relationships between the entities in the world it represents. True AI needs the ability to make informed decisions based on deep understanding and knowledge of how entities and concepts are linked together.
We’ve already seen some fantastic research from universities and industry built on top of the DKG – including the particularly interesting creation of a state-of-the-art Q&A AI, which has been very impressive.
Evolution from Data to Knowledge
There is a subtle but pivotal difference between data and knowledge. While data helps many businesses, knowledge has the power to be transformative for any business.
Define “Data”:
Facts and statistics collected together for reference or analysis.
Define “Knowledge”:
Facts, information, and skills acquired through experience or education; the theoretical or practical understanding of a subject.
The key to the DKG’s value is how it encompasses the whole Web, and how it joins together all the data points from many sources into individual entities, and – importantly – how it then connects those entities together according to their relationships.
By building a practical contextual understanding of all data online, the DKG is able to answer complex questions like: “How many people with the skill “JAVA” who used to work at IBM as a junior, now work at Facebook as a senior manager?” by providing you with a number and a list of people who meet the criteria.
To access the DKG, Diffbot created a search query language called Diffbot Query Language (DQL). It’s flexible enough to let you perform granular searches to find the one exact piece of information you need out of the trillions, or to gather massive datasets for broad analysis. DQL has all the tools you need to access the world’s largest knowledge source with highly accurate, precise searches.
Ready to Use Now
Now, any business that wants instant access to all of the world’s knowledge can simply sign up for the DKG and turn the entire Web into their personal database for business intelligence across:
People: skills, employment history, education, social profiles
Companies: rich profiles of companies and the workforce globally, from Fortune 500 to SMBs
Locations: mapping data, addresses, business types, zoning information
Articles: every news article, dateline, byline from anywhere on the Web, in any language
Products: pricing, specifications, and, reviews for every SKU across major ecommerce engines and individual retailers
Discussions: chats, social sharing, and conversations everywhere from article comments to web forums like Reddit
Images: billions of images on the web organized using image recognition and metadata collection
Want to learn more about the Diffbot Knowledge Graph?
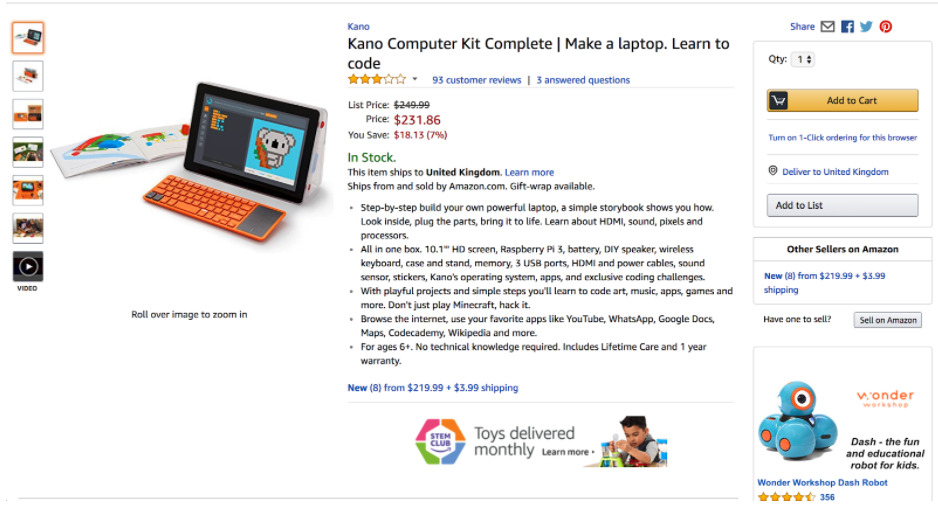
Today there are more products being sold online that there are humans on earth by a factor 100 times. Amazon alone has more than 400,000 product pages, each with multiple variations such as size, color, and shape — each with its own price, reviews, descriptions, and a host of other data points.
Imagine If you had access to all that product data in a database or spreadsheet. No matter what your industry, you could see a competitive price analysis in one place, rather than having to comb through individual listings.
Even just the pricing data alone would give at a huge advantage over anyone who doesn’t have that data. In a world where knowledge is power, and smart, fast decision making is the key to success, tomorrow belongs to the best informed, and extracting product information from web pages is how you get that data.
Obviously, you can’t visit 400 million e-commerce pages extract the info by hand, so that’s where web data extraction tools come in to help you out.
This guide will show you:
What product and pricing data is, and what it looks like
Examples of product data from the web
Some tools to extract some data yourself
How to acquire this type of data at scale
Examples of how and why industries are using this data
What is Scraped Product Data?
“Scraped product data is any piece of information about a product that has been taken from a product web page and put into a format that computers can easily understand.”
This includes brand names, prices, descriptions, sizes, colors, and other metadata about the products including reviews, MPN, UPC, ISBN, SKU, discounts, availability and much more. Every category of product is different and has unique data points. The makeup of a product page, is known as its taxonomy.
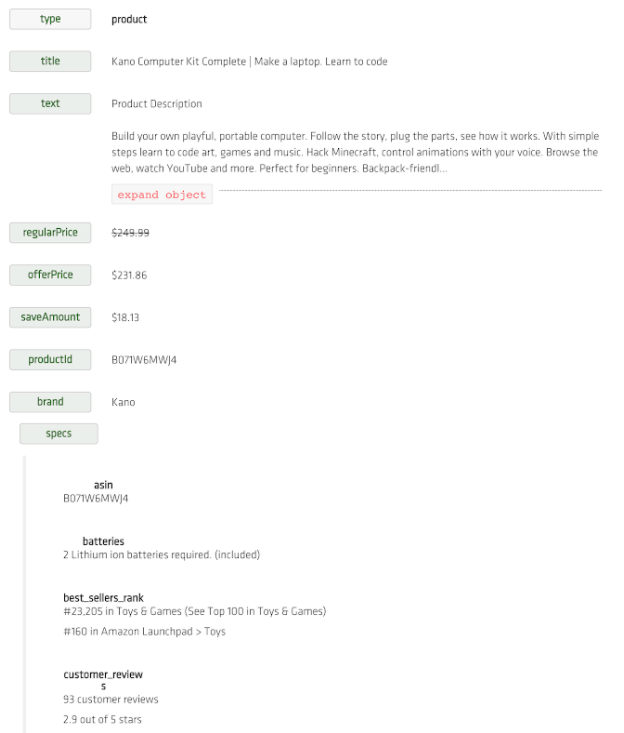
So what does a product page look like when it is converted to data?
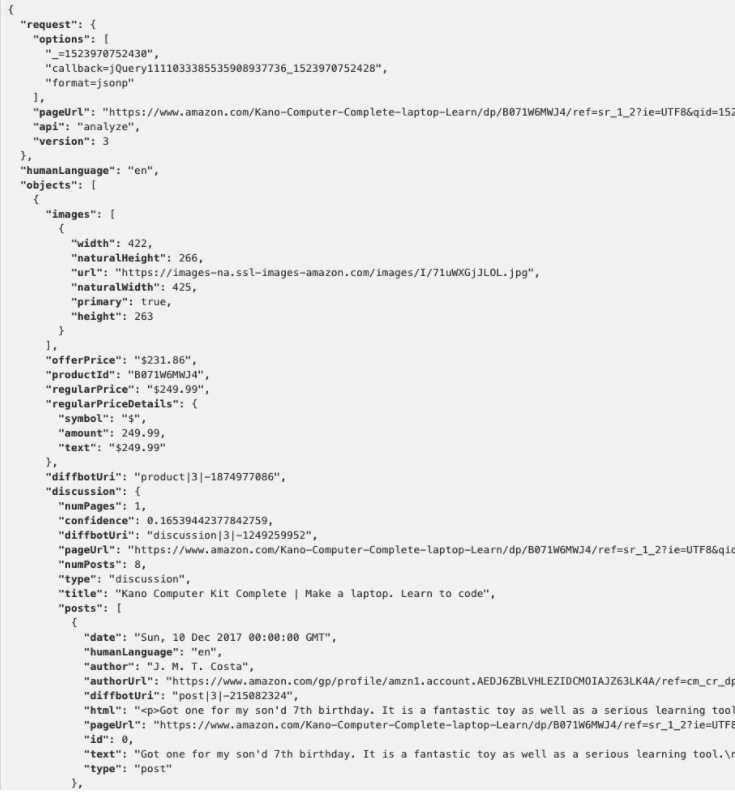
If you’re not a programmer or data scientist, the JSON view might look like nonsense. What you are seeing the data that have been extracted and turned into information that a computer can easily read and use.
What types of product data are there?
Imagine all the different kinds of products out there being sold online, and then also consider all the other things which could be considered products — property, businesses, stocks and, and even software!
So when you think about product data, it’s important to understand what data points there are for each of these product types. We find that almost all products fit into a core product taxonomy and then branch out from there with more specific information.
Core Product Taxonomy
Almost every item being sold online will have these common attributes:
Product name
Price
Description
Product ID
You might also notice that there are lots of other pieces of information available, too. For example, anyone looking to do pricing strategy for fashion items will need to know additional features of the products, like what color, size, and pattern the item is.
Product Taxonomy for Fashion
Clothing Items may also include
Core Taxonomy plus
Discounted Price
Image(s)
Availability
Brand
Reviews
colors
Size
Material
Specifications
Collar = Turn Down Collar
Sleeve =Long Sleeve
Decoration = Pocket
Fit_style = Slim
Material = 98% Cotton and 2% Polyester
Season = Spring, Summer, Autumn, Winter
What products can I get this data about?
Without wishing to create a list of every type of product on sold online, here are some prime examples that show the variety of products is possible to scrape.
Trains, planes, and automobiles (travel ticket prices)
Hotels and leisure (Room prices, specs, and availability)
Property (buying and renting prices and location)
How to Use Product Data
This section starts with a caveat. There are more ways to use product data than we could ever cover in one post. however here are;
Four of our favorites:
Dynamic pricing strategy
Search engine improvement
Reseller RRP enforcement
Data visualization
Data-Driven Pricing Strategy
Dynamic and competitive pricing are tools to help retailers and resellers answer the question: How much should you charge customers for your products?
The answer is long and complicated with many variables, but at the end of the day, there is only really one answer: What the market is will to pay for it right now.
Not super helpful, right? This is where things get interesting. The price someone is willing to pay is made up of a combination of factors, including supply, demand, ease, and trust.
In a nutshell
Increase prices when:
When there is less competition for customers
You are most trusted brand/supplier
The easiest supplier to buy from
Reduce prices when:
When there is more competition for customers, from many suppliers driving down prices
Other suppliers are more trusted
Other suppliers are easier to buy from
Obviously, this is an oversimplification, but it demonstrates how if you know what the market is doing you can adjust your own pricing to maximize profit.
When to set prices?
The pinnacle of pricing strategy is in using scraped pricing data to automatically change prices for you.
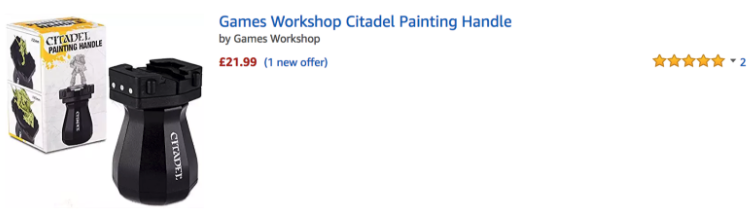
Some big brands and power sellers us dynamic pricing algorithms to monitor stock levels of certain books (price tracked via ISBN) on sites like Amazon and eBay, and increase or decrease the price of a specific book to reflect its rarity.
They can change the prices of their books by the second without any human intervention and never sell an in-demand item for less than the market is willing to pay.
Great example:
When the official store runs out of stock (at £5)
The resellers can Ramp up pricing on Amazon by 359.8% (£21.99)
Creating and Improving Search Engine Performance
Search engines are amazing pieces of technology. They not only index and categorize huge volumes of information and let you search, but some also figure out what you are looking for and what the best results for you are.
Product data APIs can be used for search in two ways:
To easily create search engines
To improve and extend the capabilities of existing search engines with better data
How to quickly make a product search engine with diffbot
You don’t need to be an expert to make a product search engine. All you need to do is:
Get product data from websites
Import that data into a search as a service tool like Algolia
Embed the search bar into your site
What kind of product data?
Most often search engine developers are actually only interested in the products they sell, as they should be, and want as much data as they can get about them. Interestingly, they can’t always get that from their own databases for a variety of reasons:
Development teams are siloed and they don’t have access, or it would take too long to navigate corporate structure to get access.
The database is too complex or messy to easily work with
The content in their database is full of unstructured text fields
The content in their database is primarily user-generated
The content in their database doesn’t have the most useful data points that they would like, such as review scores, entities in discussion content, non-standard product specs.
So the way they get this data is by crawling their own e-commerce pages, and letting AI structure all the data on their product pages for them. Then they have access to all the data they have in their own database without having to jump through hoops.
Manufacturers Reseller RRP Enforcement
Everyone knows about Recommended Retail Price (RRP), but not as many people know it’s cousins MRP (Minimum Retail Price) and MAP (Minimum Advertised Price).
If you are a manufacturer of goods which are resold online by many thousands of websites, you need to enforce a minimum price and make sure your resellers stick to it. This helps you maintain control over your brand, manage its reputation, and create a fair marketplace.
Obviously, some sellers will bend the rules now and then to get an unfair advantage — like doing o a sub-MRP discount for a few hours on a Saturday morning when they think nobody is paying attention. This causes problems and needs to be mitigated.
How do you do that?
You use a product page web scraper and write one script, which sucks in the price every one of your resellers is charging, and automatically checks it against RRP for you every 15 minutes. When a cheeky retailer tries to undercut the MRP, you get an email informing you of the transgression and can spring into action.
It’s a simple and elegant solution that just isn’t possible to achieve any other way.
This is also a powerful technique to ensure your product are being sold in the correct regions at the correct prices at the right times.
Data visualization
Beyond just being nice to look at and an interesting things to make, data visualization takes on a very serious role at many companies who use them to generate insights that lead to increased sales, productivity and clarity in their business.
Some simple examples are:
Showing the price of an item around the world
Charting trends products over time
Graphing competitors products and pricing
A stand out application of this is using in the housing agency and property development worlds where it’s child’s play to scrape properties for sale (properties are products) and create a living map of house prices and stay ahead of the trends in the market, either locally or nationally.
There is some great data journalism using product data like this, and we can see some excellent reporting here:
Here are some awesome tools that can help you with data visualization:
So now you get the idea that getting information off product pages to use for your business is a thing, now let’s dive into how you can get your hands on it.
The main way to retrieve product data is through an API, which allows anyone with the right skill set to take data from a website and pull it into a database, program, or Excel file — which is what you as a business owner or manufacturer want to see.
Because information on websites doesn’t follow a standard layout, web pages are known as ‘unstructured data.’ APIs are the cure for that problem because they let you access the products of a website in a better more structured format, which is infinitely more useful when you’re doing analysis and calculations.
“A good way to think about the difference between structured and unstructured product data is to think about the difference between a set of Word documents vs. an Excel file.
A web page is like a Word document — all the information you need about a single product is there, but it’s not in a format that you can use to do calculations or formulas on. Structured data, which you get through an API, is more like having all of the info from those pages copy and pasted into a single excel spreadsheet with the prices and attributes all nicely put into rows and columns”
APIs for product data sound great! How can I use them?
Sometimes a website will give you a product API or a search API, which you can use to get what you need. However, only a small percentage of sites have an API, which leaves a few options for getting the data:
Manually copy and paste prices into Excel yourself
Pay someone to write scraping scripts for every site you want data from
Use an AI tool that can scrape any website and make an API for you.
Buy a data feed direct from a data provider
Each of these options has pros and cons, which we will cover now.
How to get product data from any website
1) Manually copy and paste prices into Excel
This is the worst option of all and it NOT recommended for the majority of use cases.
Pros: Free, and may work for extremely niche, extremely small numbers of products, where the frequency of product change is low.
Cons: Costs your time, prone to human error, and doesn’t scale past a handful of products being checked every now and then.
2) Paying a freelancer or use an in-house developer to write rules-based scraping scripts to get the data into a database
These scripts are essentially a more automated version of visiting the site yourself and extracting the data points, according to where you tell a bot to look.
You can pay a freelancer, or one of your in-house developers to write a ‘script’ for a specific site which will scrape the product details from that site according to some rules they set.
These types of scripts have come to define scrapers over the last 20 years, but they are quickly becoming obsolete. The ‘rules-based’ nature refers to the lack of AI and the simplistic approaches which were and are still used by most developers who make these kinds of scripts today.
Pros: May work and be cheap in the short term, and may be suited to one-off rounds of data collection. Some people have managed to make this approach work with very sophisticated systems, and the very best people can have a lot experience forcing these systems to work.
Cons: You need to pay a freelancer to do this work, which can be pricey if you want someone who can generate results quickly and without a lot of hassle.
At worst this method is unlikely to be successful at even moderate scale, for high volume, high-frequency scraping in the medium to long term. At best it will work but is incredibly inefficient. In a competition with more modern practices, they lose every time.
This is because the older approach to the problem uses humans manually looking at and writing code for every website you want to scrape on a site by site basis.
That causes two main issues:
When you try to scale that it gets expensive. Fast. You developer must inherently write (and maintain) at least one scraper per website you want data from. That takes time.
When any one of those websites breaks the developer has to go back and re-write the scraper again. This happens more often than you imagine, particularly on larger websites like Amazon who are constantly trying out new things, and whose code is unpredictable.
Now we have AI technology that doesn’t rely on rules set by humans, but rather with computer vision they can look at the sites themselves and find the right data much the same way a human would. We can remove the human from the system entirely and let the AI build and maintain everything on its own.
Plus, It never gets tired, never makes human errors, and is constantly alert for issues which it can automatically fix itself.Think of it as a self-driving fleet vs. employing 10,000 drivers.
The last nail in the coffin for rules-based scrapers is that they require long-term investment in multiple classes of software and hardware, which means maintenance overhead, management time, and infrastructure costs.
Modern web data extraction companies leverage AI and deep learning techniques which make writing a specific scraper for a specific site a thing of the past. Instead, focus your developer on doing the work to get insights out of the data delivered by these AI.
Quora also has a lot of great information about how to utilize these scripts if you chose to go this route for obtaining your product data.
3) Getting an API for the websites you want product data from
As discussed earlier, APIs are a simple interface that any data scientist or programmer can plug into and get data out. Modern AI product scraping services (like diffbot) take any URLs you give them and provide perfectly formatted, clean, normalized, and highly accurate product data within minutes.
There is no need to write any code, or even look at the website you want data from. You simply give the API a URL and it gives your team all the data from that page automatically over the cloud.
No need to pay for servers, proxies or any of that expensive complexity. Plus, the setup in order of magnitude faster and easier.
Pros:
No programming required for extraction, you just get the data in the right format.
They are 100 percent cloud-based, so there is no capex on an infrastructure to scrape the data.
Simple to use: You don’t even need to tell the scraper what data you want, it just gets everything automatically. Sometimes even things you didn’t realize were there.
More accurate data
Doesn’t break when a website you’re interested in changes its design or tweaks its code
Doesn’t break when websites block your IP or proxy
Gives you all the data available
Quick to get started
Cons:
Too much data. Because you’re not specifying what data you’re specifically interested in, you may find the AI-driven product scrapers pick up more data than you’re looking for. However, all you need do is ignore the extra data.
You could end up with bad data (or no data at all) if you do not know what you’re doing
If you can buy the data directly, that can be the best direction to go. What could be easier than buying access to a product dataset, and integrating that into your business? This is especially true if the data is fresh, complete and trustworthy.
Pros:
<li>Easy to understand acquistion process.</li>
<li>You do not need to spend time learning how to write data scraping scripts or hiring someone who does.</li>
<li>You have the support of a company behind you if issues arise.</li>
<li>Quick to start as long as you have the resources to purchase data and know what you are looking for.</li>
Cons:
Can be more expensive, and the availability of datasets might not be great in your industry or vertical.
Inflexible rigid columns. These datasets can suffer from an inflexible rigid taxonomy meaning “you get what you get” with little or no option to customize. You’re limited to what the provider has in the data set, and often can’t add anything to it.
Transparency is important when looking at buying data sets. You are not in control of the various dimensions such as geolocation, so be prepared to specify exactly what you want upfront and check they are giving you the data you want and that it’s coming from the places you want.
Putting It All Together
Now that you know what scraped product data is, how you can use that data, and how to get it, the only thing left to do is start utilizing it for your business. No matter what industry you are in, using this data can totally transform the way you do business by letting you see your competitors and your consumers in a whole new way — literally.
The best part is that you can use existing data and technology to automate your processes, which gives you more time to focus on strategic priorities because you’re not worrying about minutia like prices changes and item specifications.
While we’ve covered a lot of the basics about product data in this guide, it’s by no means 100 percent complete. Forums like Quora provide great resources for specific questions you have or issues you may encounter.
Do you have an example of how scraped product data has helped your business? Or maybe a lesson learned along the way? Tell us about it in the comments section.
Every now and then it’s important to get back to basics and ask a question which seems obvious, because sometimes those questions have hidden depths. The question “What Is Product Data?” is one of those I recently asked myself, and it led me down a mini-rabbit hole.
The basic definition of a product is:
“A thing produced by labor, such as products of farm and factory; or the product of thought, time or space.”
When you think about it, that covers a lot of ground. By definition, a product can be almost anything you can imagine — from any item on the supermarket shelf, to an eBook, a house, or even just a theory.
So how do we at Diffbot pare down the definition from almost anything in the world, to a useful definition for someone interested in data?
What is a useful definition of a product in the context of data?
“A product is a physical or digital good, which has the attributes of existing, having a name, being tradable.” Beyond that, all bets are off.
So to frame that in the context of data, the universal attributes of a product are data attributes, like Identifier and Price.
There is, obviously, more to most product data than that. So how do you define a set of attributes (or taxonomy) that is useful, and defines all products as data? We’ve come up with a couple approaches to that question.
Approaches to defining a product as data:
1. Product Schema
One way people try to define product data is by imagining every possible product attribute, and then creating a massive set of predefined product types and the attributes each type is expected to have. Then they publish that as a schema.
“Any offered product or service. For example: a pair of shoes; a concert ticket; the rental of a car; a haircut; or an episode of a TV show streamed online.”
They have tried to make a universal product taxonomy by setting out more than 30 attributes they think can cover any product — and even a set of additional attributes that can be used to add extra context to the product.
The primary aim of their schema for product data is to allow website owners to “markup” their website HTML more accurately. This method has had some success, with over one million websites using their product definition. Sadly, this is still less than 0.3% of all websites.
Schema.org works well for its intended purpose, and it does a good job at providing a framework to structure what a physical product is. But it also falls short on several fronts.
The downside of this approach is that by trying to fix a set number of attributes for all products, they exclude a vast amount of product data and limit the scope to only ever being a fraction of the data that could be available. Not only that but they require website creators to spend time adding this data themselves.
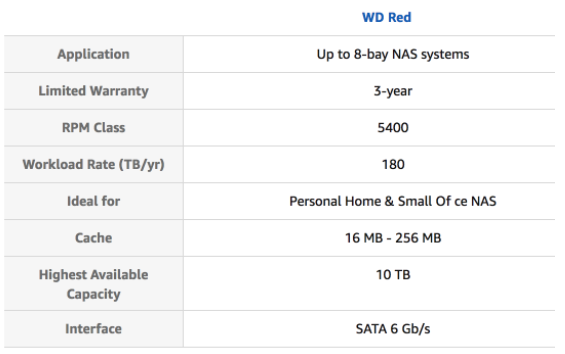
Take the example of a hard disk drive. It has some attributes that fit into Schema.org’s product data definition, but it also has 10x more data that could be available to users. For instance, there is a full table of specifications that don’t fit into the premade definitions like these for the product.
WD Red 4TB NAS Hard Disk Drive – 5400 RPM Class SATA 6GB/S 64 MB Cache 3.5-Inch
The problem is that there are so many different data points a product could have, that you can never define a universal product spec for them all. So there needs to be another way to describe products as data.
2. AI Defined Product Data
The main problem with the “universal product data definition” is that someone has to try to foresee any and all combinations, and then formalize them into a spec.
The beauty of the AI approach is that it doesn’t approach product data with any preconceived ideas of what a product should look like. Instead, it looks at data in a way similar to how a human would approach it. Using AI, you can let the product itself define the data, rather than trying to make a product fit into your pre-made classifications. The process basically looks like this:
Load a product page
Look at all the structures, layouts, and images
Us AI, and computer vision techniques to decide what is relevant product data
Use the available data to define the product
Organize the data into a table like structure (or JSON file for experts)
Finally, we can define a what product is by using AI to look at the product is. So if we can now reliably define what a product is, and we can get all the data about what it is, what else do we need to know about product data?
3. Product Meta Data
Product metadata is the data about a product which is not necessarily a physical aspect of the item, but rather some intellectual information about it.It should also be considered product data. Product metadata may include:
Its location
Its availability
Its review score
What other products it is related to
Other products people also buy or view
Where it appears in keyword searches
How many sellers there are for the product
Is it one of a number of variations
Summary
Before getting any further down the rabbit hole of product semantics, data, knowledge graphs, Google product feeds and all the other many directions this question can take you, it’s time to stop and reconsider the original question.
What is Product Data?
Product data is all the information about a product which can be read, measured and structured into a usable format. There is no universal fixed schema that can cover all aspects of all products, but there are tools that can help you extract a product’s data and create dynamic definitions for you. No two products are the same, so we treat both the product and its data as individual items. We don’t put them into premade boxes. Instead, we understand that there are many data points shared between products, and there are more which are not.
As an individual or team interested in product data, the best thing you can do is use Diffbot’s AI to build datasets for you, with all the information, and then choose only the data you need.
The Semantic web is a dream that many are attempting to make into reality through the use of machine-readable metadata. Web developers worldwide would use this metadata to make the search for content easy for users that wish to extract web data. In a perfect world this would have already happened, but alas, developers today still have to find ways to cleanly extract the data they’re looking for. What follows is a comprehensive breakdown of such web data tools, ranging from the free code libraries that developers can tailor to their needs to cloud-managed services that provide APIs for code integration and everything solution between. If you’re looking for the best way to handle your web data collection problem, you’ve come to the right place!
Do It Yourself!
The most time-intensive way to deal with the web data issue is to create your own custom APIs specific to a website of interest. Despite being a good chance to flex your developer chops, this method does not bring along with it a high level of robustness. Any change that affects the source code of that website can potentially render your self-made API useless, and require an update from you or the poor soul that you’re constantly bothering for fixes. This approach also means that you’ll likely have to develop multiple APIs if you’re working on any sort of aggregation from multiple websites. If you’re particularly lucky, the data that you want will be accessible via an API provided by the website(s) in question. Unfortunately, web developers typically let the API sink to the bottom of their workflows, leaving you at the mercy of any website revision that will deprecate the API.
If you do you web data collection yourself, there are free online code libraries that can help you do your web data collection. BeautifulSoup is one of these options. This library can be easily integrated into your code (working with Python) and can drastically reduce the amount of time required for web data projects. The library does the hard work for you, parsing the input and doing the tree traversal (identifying and extracting selected elements in the process). Other frameworks such as lxml support the easy integration of BeautifulSoup for improved web scraping results.
JSoup also allows easy extraction of selected elements. It is an open-source Java-library that parses web pages into usable chunks which are selectable by XML/HTML markup.
Another library that can be very helpful in web data extracion is BoilerPipe by Christian Kohlschutter. This Java library provides algorithms to extract useful text from the web. Just like BeautifulSoup, the main purpose of BoilerPipe is to cut out all of the superfluous content that surrounds the data you’re looking for. It already provides fully fleshed out functionality for basic types of pages such as articles, but is still useful for myriad other applications.
Scrapy is a more developed Python-based platform for scraping entire websites . On its website, it touts an established community and extensive documentation for easy implementation. Scrapy is currently being used by a variety of businesses to crawl entire websites (ranging from news outlets to real estate listing aggregators) for valuable relevant data. The advantage to this library is that aside from being able to collect data collection from an individual page, it can also crawl entire websites for you. Scrapy allows you to write “spiders” that do this and output data in a variety of formats including JSON, XML, and CSV.
JusText is another code library available at https://code.google.com/p/justext/; it’s main goal is to strip away erroneous content and extract usable text from websites. Here it is in action analyzing a generic news article (taken from their in-browser test tool)
As you can see, JusText has done a pretty good job of ignoring side stories, links, and ads while delivering the usable article text. It also is designed to work in Python with lxml just like BoilerPipe. However, as the name implies, JusText cannot help you if you’re looking to extract images or video to use to your application.
Goose is another available open source Scala library that can provide a more complete answer to the problem of gathering diverse data. It has recently been ported to Scala from Java but is still suitable for use in Java with some small modifications. Goose is tailored towards extracting information purely from article pages and returns data that is highly relevant to this purpose. Goose attempts to return the main text, main image, any embedded YouTube/Vimeo videos, meta descriptions and tags, and the publish date.
With this many choices for implementation in your code, it may be difficult to settle on just one. Luckily, a backend engineer named Tomaž Kovačič had done a comparison of code library option on his blog, saying:
“According to my evaluation setup and personal experience, the best open source solution currently available on the market is the Boilerpipe library. If we treat precision with an equal amount of importance as recall…and take into account the performance consistency across both domains, then Boilerpipe performs best. Performance aside, its codebase is seems to be quite stable and it works really fast.”
Let someone else do it!
Exploring automated options is also a viable way to retrieve your desired data from the web. These options can either retrieve targeted data or scrape entire websites and return information in a database, both with minimal effort from the developer. Most automated options fall into the category of web-based APIs, which typically charge a monthly rate to process a capped number of URLs and return a specified output in a preferred format (XML, JSON, PDF, etc.) via a provided API. Service providers in this space include Alchemy, Bobik, Connotate, Diffbot, Mozenda, Readability, and Tubes.io. They share similar attributes such as continued user support, upgrades, flexible subscription plans which often include free low-usage plans.
One of these cloud-managed services is Tubes.io. This service provides an in-browser interface for creating “Tubes”, which return relevant data.
Bobik is a scraping platform that aims to eliminate the headache of developing custom APIs and working around various use cases. For example, Bobik can (if passed login information through the API) automatically collect data from protected sources. It is directly supported in a variety of languages (JavaScript, Java, Ruby, Python), and it integratable in any language (with proper implementation of the REST flow).
Diffbot is a slightly different offering from Bobik because it is completely cloud-hosted with an in-browser interface for users. It uses machine vision to find the selected data regardless of where it is on the page (unlike many options here, it doesn’t rely on XML or HTML tags) since it has been trained to visually recognize web data. It provides developers with an API to grab data from specific types of pages through their Frontpage, Article, and Product APIs. Although these algorithms are created with their specific purpose in mind, Diffbot lets you override their output with their Customize and Correct tool to create a Custom API. This means that you can tailor your data collection by simply adding on to an existing API . Diffbot utilizes learning algorithms to return the desired data, and so your output becomes more accurate over time.
AlchemyAPI provides web text extraction but differs from other offerings in that they also focus on automated text interpretation. AlchemyAPI can scrape web text and return named entities, authors, and quotes but also can identify languages, keywords, intents, and topics within text. It provides REST APIs for developers to use their service and also have large-scale personalized solutions.
There are other web services that differ from the previous category of web-hosted APIs in that there is virtually no coding required to create and manage data crawlers. These are typically software packages that provide a local point-and-click interface for users.This solution works best for small businesses that likely don’t have personnel that can develop a proprietary solution.
Kapow is one such solution in this space, which allows data collection solutions to be rolled out to business users with little to no coding. Their framework is based on “robots”, which are integrated workflows that are user-defined through a local interface. This interface (termed a “KappZone”) allows one user to define a workflow for a different user to access and use for their own purposes. Kapow has no publicly available pricing information, but is open to requests for information and for trial versions.
Connotate also provides data collection capability for non-coders. Their “intelligent Agent” technology lets users easily specify and collect the data that they want. Connotate’s service comes in three ways: Hosted, Local, and Cloud. The Hosted solution takes virtually all of the work out of collecting web data, users simply interface with Connotate to specify what data they would like and clean data is returned. On the other hand, the Local service lets users define their own collection parameters and use an installed version of the software to get their data. Lastly, Cloud provides the same function as Local, with the exception of cloud-hosted services rather than local.
WebHarvy differs from the majority of the entries in this list because it is offered directly as software that only interacts with the pages that users wish to extract data from. WebHarvy’s interface is similar to that of Kapow’s, it also is a simple point-and-click in which users can specify which elements they want and let the software do the rest.
AutomationAnywhere takes a broader approach to the problem of repetition-intensive collection tasks. This software package allows users to record any workflow within a point-and-click interface (not just web tasks) and set the machine to work at repeating the workflow. Though this approach smacks of a brute-force approach to the problem of collecting web data (individually saving portions of web pages through a recorded user action), it may work for certain applications of web data collection.
If you happen to be an enterprise user, you may also find yourself wanting to extract a particular large or complex dataset for business purposes. One may also wonder how you ended up on this blog, but that’s beside the point. When you aren’t serving up continually changing content to users, there is another set of companies that can help. These companies act as contractors, with customer representatives that characterize the dataset you are trying to obtain and return clean data in a specified format. I won’t spend much time on this subject since we are reaching the fringes of relevance to the developer community, but players in this market include ScraperWiki and Loginworks.
As a developer, you want the most accurate data collection algorithms if you’re leaving your work to be done by a service. A fairly robust evaluation of several API-based options has been done by Tomaž Kovačič, part of which is reproduced here:
“If you’re looking for an API and go by the same criteria (equal importance of precision and recall, performance consistency across both domains), diffbot seems to perform best, although alchemy, repustate and extractiv are following closely. If speed plays a greater role in your decision making process; Alchemy API seems to be a fairly good choice, since its response time could be measured in tenths of a second, while others rarely finish under a second…”
It’s a big world out there, and the tools for bending data to your will are growing more accurate and more accessible. Hopefully you’ve found a suitable solution to your data collection in this post, and if there are other tools that are personal favorites of yours please let me know at roberto@diffbot.com.
Visit Customize and Correct in the Developer Dashboard
We introduced “Customize and Correct” in 2012 because, let’s face it, robots aren’t perfect.
(Yet.)
So in this post I’ll walk you through using Customize and Correct to make instant changes to Diffbot API output, either to correct a rare issue, or to augment information you’re already receiving.
For those of you with heavy call volume, our Batch API lets you submit up to 50 API calls in a single request, and set a custom timeout parameter to make sure you get what you want on your own timeline.
Full documentation is in our Developer Dashboard. Here’s a quick introduction:


“What we’ve built is the first Knowledge Graph that organizations can use to access the full breadth of information contained on the Web. Unlocking that data and giving organizations instant access to those deep connections completely changes knowledge-based work as we know it.”





You must be logged in to post a comment.