Today we’re happy to announce the public availability of Crawlbot, our computer-vision-powered site crawler and extractor.
If you want structured data from an entire site, Crawlbot will fully spider a domain and hand off the right pages to Diffbot APIs. The result? A queryable index of the entire site’s data, or a complete download of the site’s structured data in easy-to-read — for a robot — JSON.
Crawlbot isn’t your ordinary crawler. (If it was, we’d just call it “Crawler.”) No, Crawlbot is Smart Spidering. Using our Page Classifier API, Crawlbot’s Smart Processing option allows you to only extract and process those pages that match your desired page type.
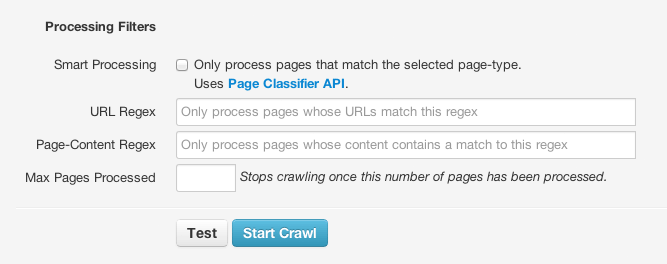
Only looking for products? Crawlbot will only process product pages. Want to just grab articles and blog posts from a corporate web site? Same.
Crawlbot also features lots of knobs and switches for fine-tuning the particulars of your crawl — if you want to widen or narrow scope from the starting URL, limit the number of pages, etc.
Take Crawlbot for a spin in your Developer Dashboard. If you don’t have a token yet, sign up for one.
You must be logged in to post a comment.